【深度学习入门篇①】手动完成线性回归!


【🍊易编橙:一个帮助编程小伙伴少走弯路的终身成长社群~🍊】 大家好,我是小森( ﹡ˆoˆ﹡ ) ! 易编橙·终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官、CSDN人工智能领域优质创作者 。
大家好!今天我们将一起踏上一场探索深度学习的奇妙之旅,而我们的起点,就是线性回归这一经典而基础的算法。我将带大家从零开始,手动实现线性回归!

Pytorch完成线性回归
向前计算
对于pytorch中的一个tensor,如果设置它的属性 .requires_grad为True,那么它将会追踪对于该张量的所有操作。或者可以理解为,这个tensor是一个参数,后续会被计算梯度,更新该参数。
计算过程
假设有以下条件(1/4表示求均值,xi中有4个数),使用torch完成其向前计算的过程
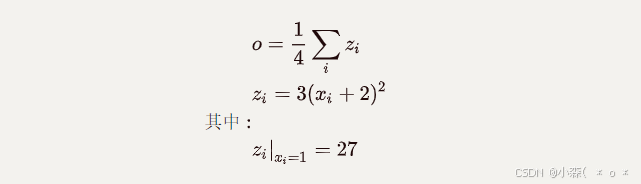
如果x为参数,需要对其进行梯度的计算和更新
那么,在最开始随机设置x的值的过程中,需要设置他的requires_grad属性为True,其默认值为False
import torch
x = torch.ones(2, 2, requires_grad=True) # 设置requires_grad=True用来追踪其计算历史
print(x)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
y = x+2
print(y)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
z = y*y*3
print(x)
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>)
out = z.mean() # 均值
print(out)
tensor(27., grad_fn=<MeanBackward0>)💦从上述代码可以看出:
- x的requires_grad属性为True
- 之后的每次计算都会修改其
grad_fn属性,用来记录做过的操作
requires_grad和grad_fn
a = torch.randn(2, 2)
a = ((a * 3) / (a - 1))
print(a.requires_grad) # False
a.requires_grad_(True) # 修改
print(a.requires_grad) # True
b = (a * a).sum()
print(b.grad_fn) # <SumBackward0 object at 0x4e2b14345d21>
with torch.no_gard():
c = (a * a).sum() #tensor(151.6830),此时c没有gard_fn
print(c.requires_grad) #False注意:
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型时特别有用,因为模型可能具有requires_grad = True的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
在机器学习和深度学习中,模型有训练模式和评估模式 训练模式:前向传播、计算损失、反向传播
- 在训练过程中,模型中的某些层,例如Dropout层会在训练时随机丢弃一部分神经元的输出,以防止过拟合。
评估模式:模型被用来评估其在新数据上的性能,而不需要进行参数的更新;例如,Dropout层在评估模式下会停止丢弃神经元,以确保模型输出的一致性。
梯度计算
对于上面的计算过程,我们可以使用backward方法来进行反向传播,计算梯度💫
out.backward(),此时便能够求出导数
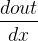
$\frac{d out}{dx}$
,调用x.gard能够获取导数值:
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])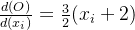
\frac{d(O)}{d(x_i)} = \frac{3}{2}(x_i+2)
在
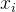
x_i
等于1时其值为4.5
注意:在输出为一个标量的情况下,我们可以调用输出tensor的backword() 方法,但是在数据是一个向量的时候,调用backward()的时候还需要传入其他参数。
很多时候我们的损失函数都是一个标量,所以这里就不再介绍损失为向量的情况。
loss.backward()就是根据损失函数,对参数(requires_grad=True)的去计算他的梯度,并且把它累加保存到x.gard,此时还并未更新其梯度
-
tensor.data:- 在tensor的require_grad=False,tensor.data和tensor等价
- require_grad=True时,tensor.data仅仅是获取tensor中的数据
-
tensor.numpy():-
require_grad=True不能够直接转换,需要使用tensor.detach().numpy()
-

线性回归实现
我们使用一个自定义的数据,来使用torch实现一个简单的线性回归;
假设我们的基础模型就是y = wx+b,其中w和b均为参数,我们使用y = 3x+0.8来构造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8。
import torch
import numpy as np
from matplotlib import pyplot as plt
x = torch.rand([50]) # 相当于就是y = 3*x + 0.8 这条直线的x的数量
y = 3*x + 0.8
# 初始权重w和b都是设置为1
w = torch.rand(1,requires_grad=True)
b = torch.rand(1,requires_grad=True)
def loss_fn(y,y_predict):
loss = (y_predict-y).pow(2).mean()
for i in [w,b]:
# 每次反向传播前把梯度设为0
if i.grad is not None:
i.grad.data.zero_()
# [i.grad.data.zero_() for i in [w,b] if i.grad is not None]
loss.backward()
return loss.data
def optimize(learning_rate):
# print(w.grad.data,w.data,b.data)
w.data -= learning_rate* w.grad.data
b.data -= learning_rate* b.grad.data
for i in range(3000):
# 预测值
y_predict = x*w + b
# 计算损失,把参数的梯度置为0,进行反向传播
loss = loss_fn(y,y_predict)
if i%500 == 0:
print(i,loss)
# 更新参数w和b
optimize(0.01)
# 绘制图形,观察训练结束的预测值和真实值
predict = x*w + b
# 使用训练后的w和b计算预测值
plt.scatter(x.data.numpy(), y.data.numpy(),c = "r")
plt.plot(x.data.numpy(), predict.data.numpy())
plt.show()
print("w",w)
print("b",b)输出结果:
0 tensor(2.0233)
500 tensor(0.0692)
1000 tensor(0.0201)
1500 tensor(0.0059)
2000 tensor(0.0017)
2500 tensor(0.0005)
w tensor([2.9586], requires_grad=True)
b tensor([0.8253], requires_grad=True)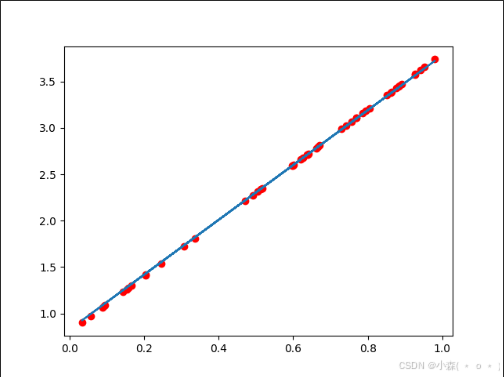
💯可以看到已经很接近我们所预期的值了!
💥下期我们再来动手使用Pytorch的API来创建线性回归!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-07-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号