光子学与人工智能的融合:光互连、光交换、AI辅助光子设计、光计算


在科技飞速发展的当下,光子学与人工智能(AI)的融合成为了前沿热点领域。这一融合不仅为AI的发展注入了新动力,也为光子学开辟了更广阔的应用空间。今天就来分享一篇来自Coherent公司DCTO陈博士(Young-Kai Chen,IEEE终生fellow)的邀请文章,深入剖析这一极具潜力的领域。
(https://ieeexplore.ieee.org/document/10930836)
一、AI发展的困境与光子学的介入
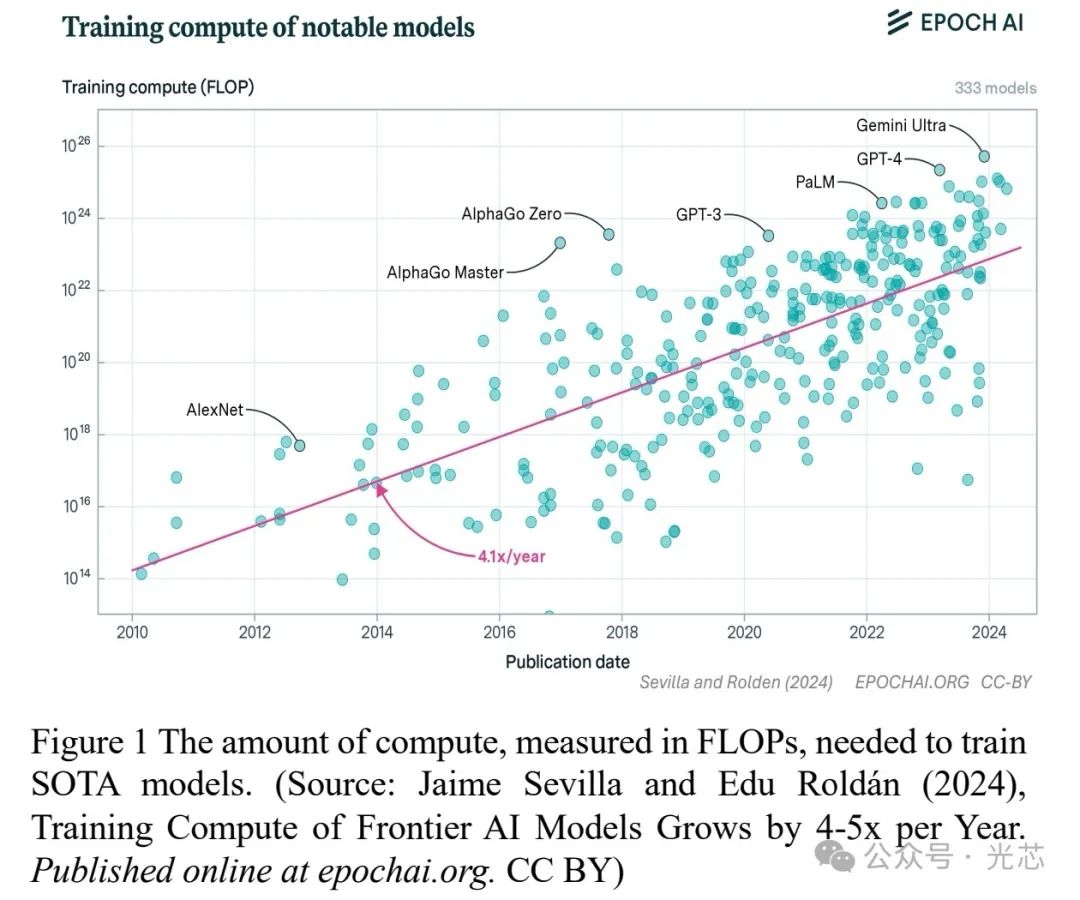
过去十年间,AI取得了显著进展,深度学习在计算机视觉、自然语言处理等领域成果斐然。像卷积神经网络提升了图像分类和物体检测能力,Transformer架构革新了自然语言处理任务,强化学习推动了机器人和自动驾驶系统的发展,生成式AI模型能创造逼真的多媒体内容,大语言模型(LLM)在文本生成等方面表现出色。
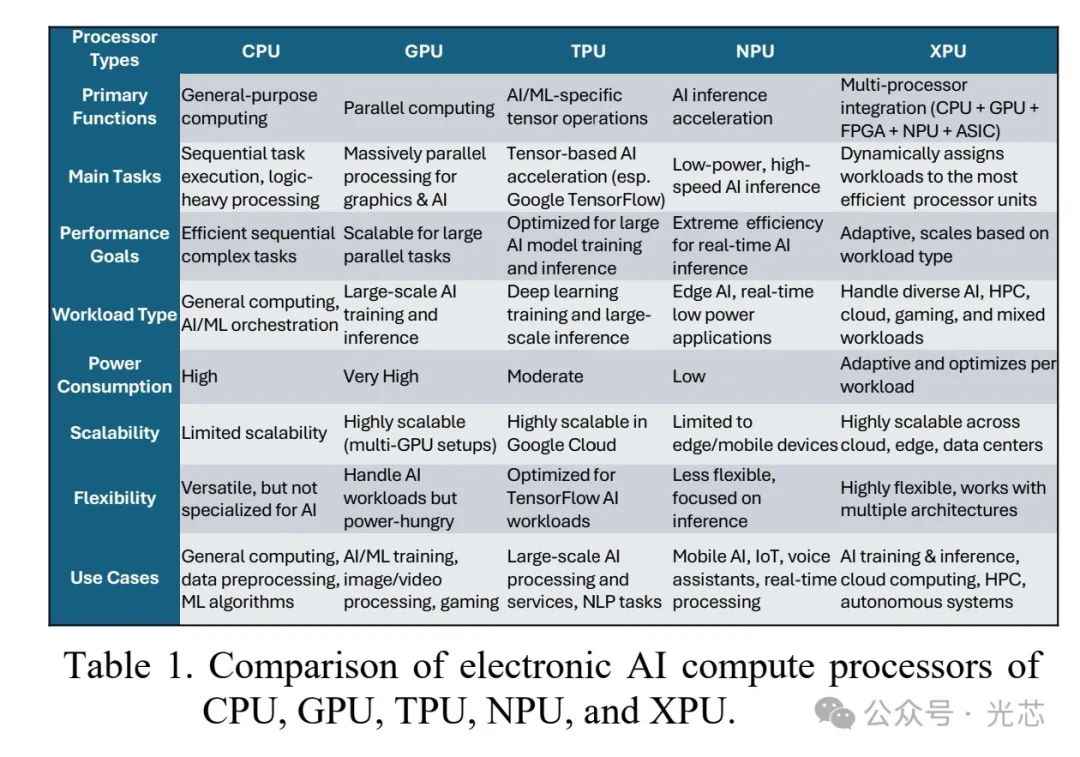
然而,AI的发展也面临挑战。为训练数十亿参数的LLM模型,需要处理海量多维信息,计算工作量呈指数级增长,远超微电子技术遵循的摩尔定律。例如,训练一个GPT-4 LLM模型,需2.25×10^25次浮点运算(Flops)来建立10万亿模型参数,以达到86.4%的MMLU(Massive Multitask Language Understanding)准确率,这需要15,000个NVIDIA 20-peta-Flop B200 GPU不间断运行3天。目前AI处理主要依赖电子处理器,数据中心训练LLM模型需大量处理器,且处理时间长、能耗高。
光子学凭借其高速、低延迟、在时间和频谱等多领域的多样性和相干性等独特优势,成为解决AI发展困境的关键。它能实现高速数据互连,连接更多电子AI处理器,支撑AI技术的未来发展。

二、光子学支撑高容量AI工作负载
2.1 光子学作为AI数据中心的骨干(光互连)
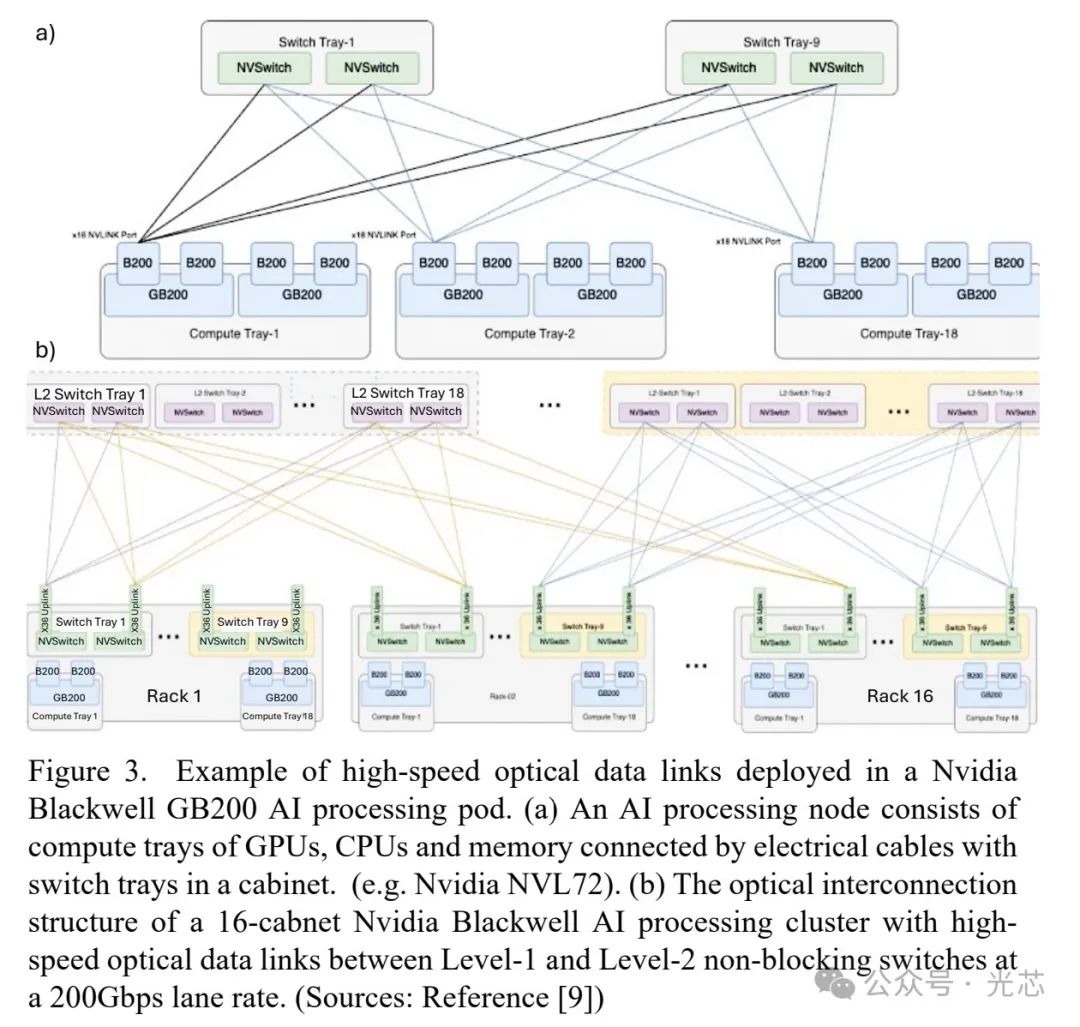
在典型的超大规模数据中心,光学互连为GPU、CPU等快速处理器和内存单元提供了高容量数据连接,实现了高吞吐量和低延迟的AI计算。如在Nvidia Blackwell HGX GB200 AI处理集群中(见图3),处理器层的高速GPU、CPU和内存ASIC通过200Gb/s的高速电气数据链路连接,这些机柜再通过200 Gbps每通道的并行光纤高速光数据链路聚合形成计算集群,以执行11.5 exaflops的FP4计算。

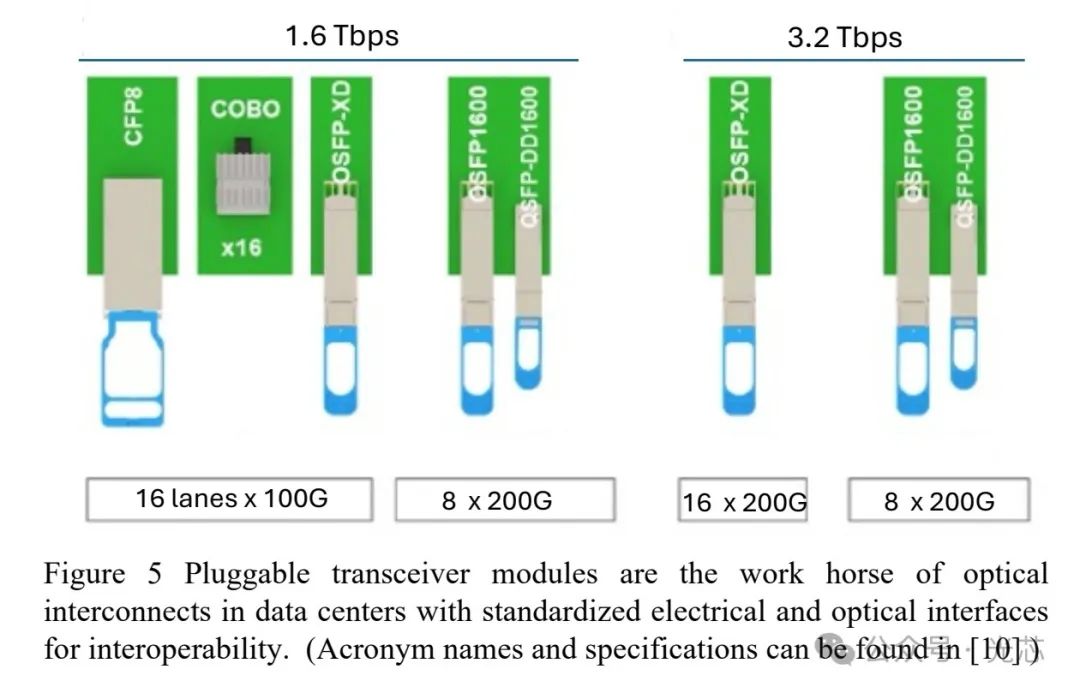
随着电子处理器的发展,光收发器的速度和容量也在不断提升(见图4),从2020年的100(4x25)Gbps每链路增加到2025年的1,600(8x200)Gbps。高容量光收发器通常采用可插拔收发模块,放置在交换机或服务器盒的前/后面板,便于热插拔维护(见图5)。根据传输距离和带宽需求,会采用不同的调制方式,如短距离采用PAM4调制,长距离采用数字相干光(DCO)检测。
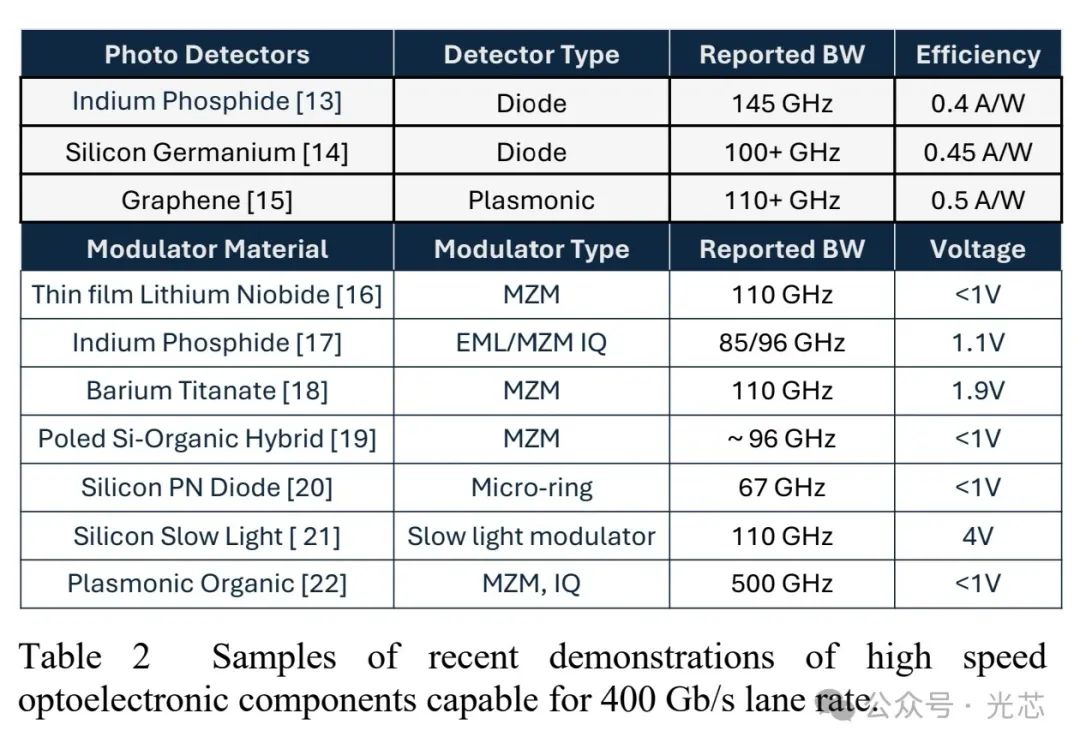

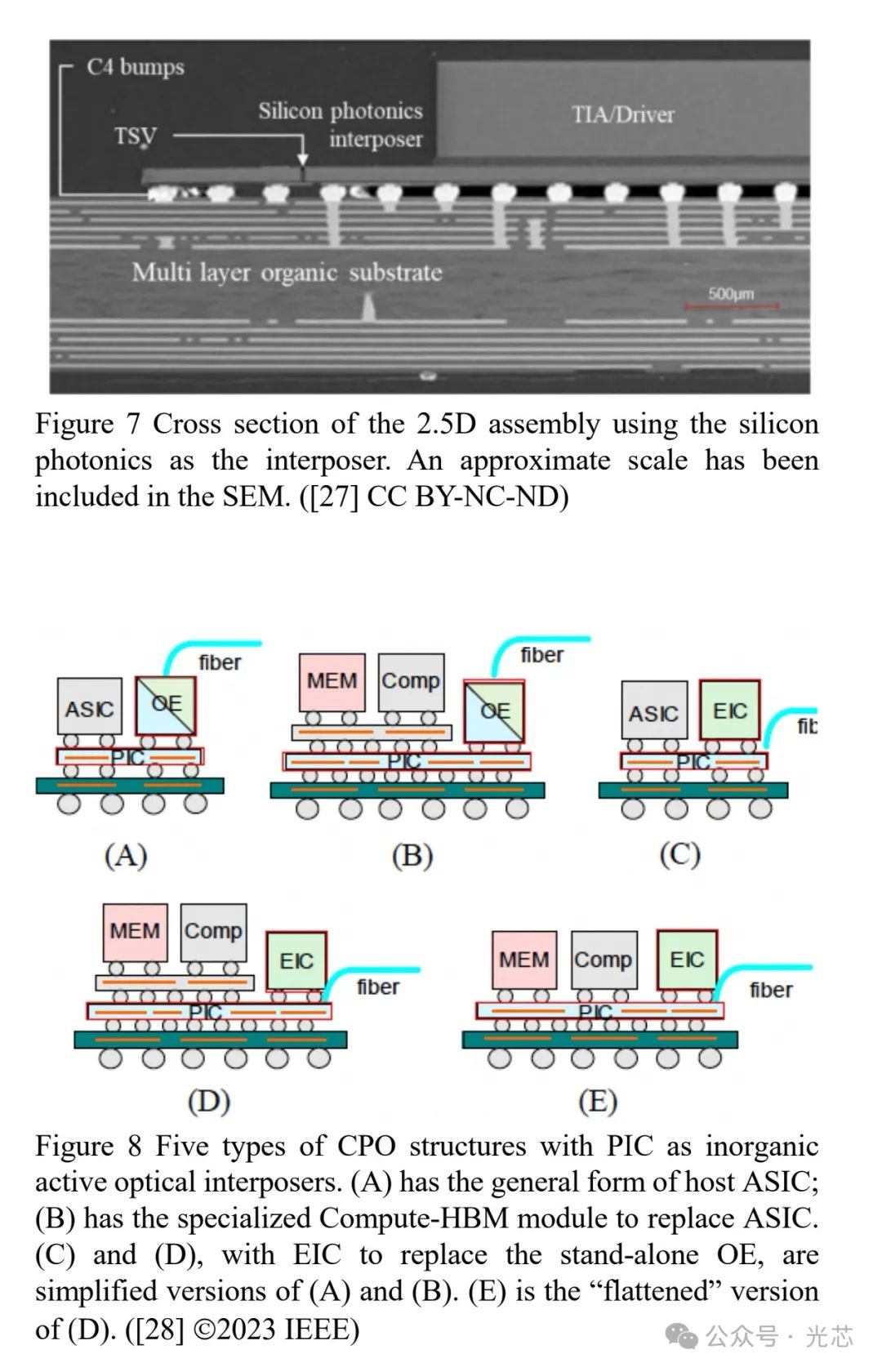
为减少铜互连损耗,光收发器逐渐靠近ASIC处理器,从可插拔模块到中间板COBO,再到靠近封装的近处理器光学(NPO),最终实现与电子AI处理器的共封装光学(CPO)集成(见图6)。光子集成电路(PICs)在InP或硅光子学中能提供高传输容量,如台积电基于其Chip-on-Wafer-on-Substrate(COWOS)晶圆级集成平台的集成光学互连系统(iOIS)(见图8),实现了光学输入输出数据通过处理器封装传输,不受电气互连限制。
2.2 光子学配置AI数据流量和计算(光交换)
生成式预训练Transformer(GPT)模型驱动了对大量处理需求的增长,光子开关除了用高容量光数据链路连接服务器外,还能在处理和存储块之间实现低延迟、高吞吐量的动态路由。为处理大规模工作负载,数据网络工程师开发了容错数据处理方法,如谷歌基于MapReduce架构训练PaLM模型。

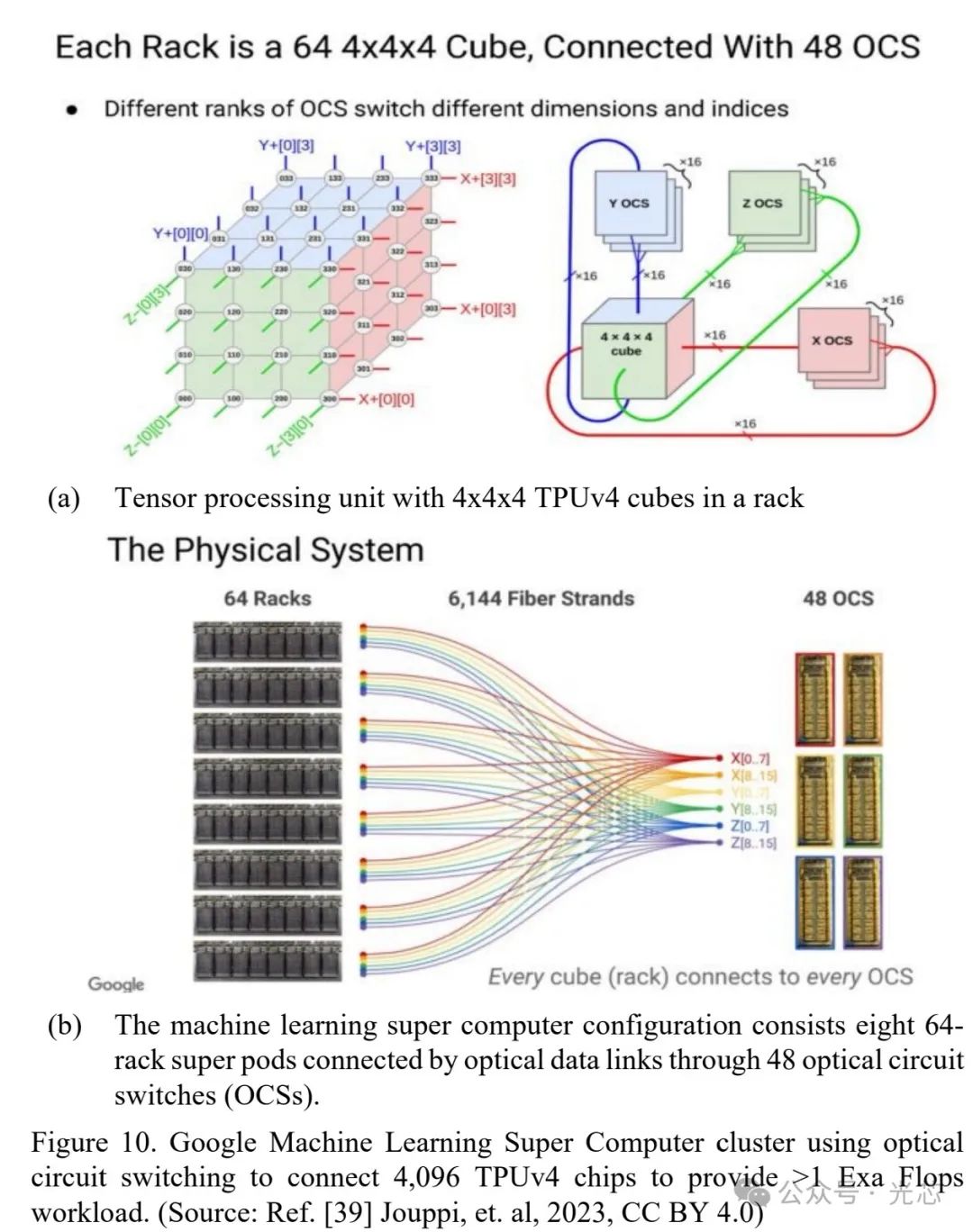
在数据中心网络中,需要快速的光子或混合电光开关来路由高容量流量。混合电光开关存在能耗高、延迟大的问题,而无阻塞光电路开关(OCS)可在光域内进行数据交换,无需光-电-光转换,实现高吞吐量和低延迟。许多光子开关技术被用于实现无阻塞光电路开关阵列,如基于MEMS和液晶的OCS(见图9)。谷歌数据中心用基于MEMS的OCS取代高速特定速率的光-电-光开关层,实现了低延迟、数据速率无关的无阻塞交换,还能进行动态拓扑重构和集中式软件定义网络(SDN)控制(见图10)。
三、AI辅助光电子设计
3.1 光子器件的端到端优化
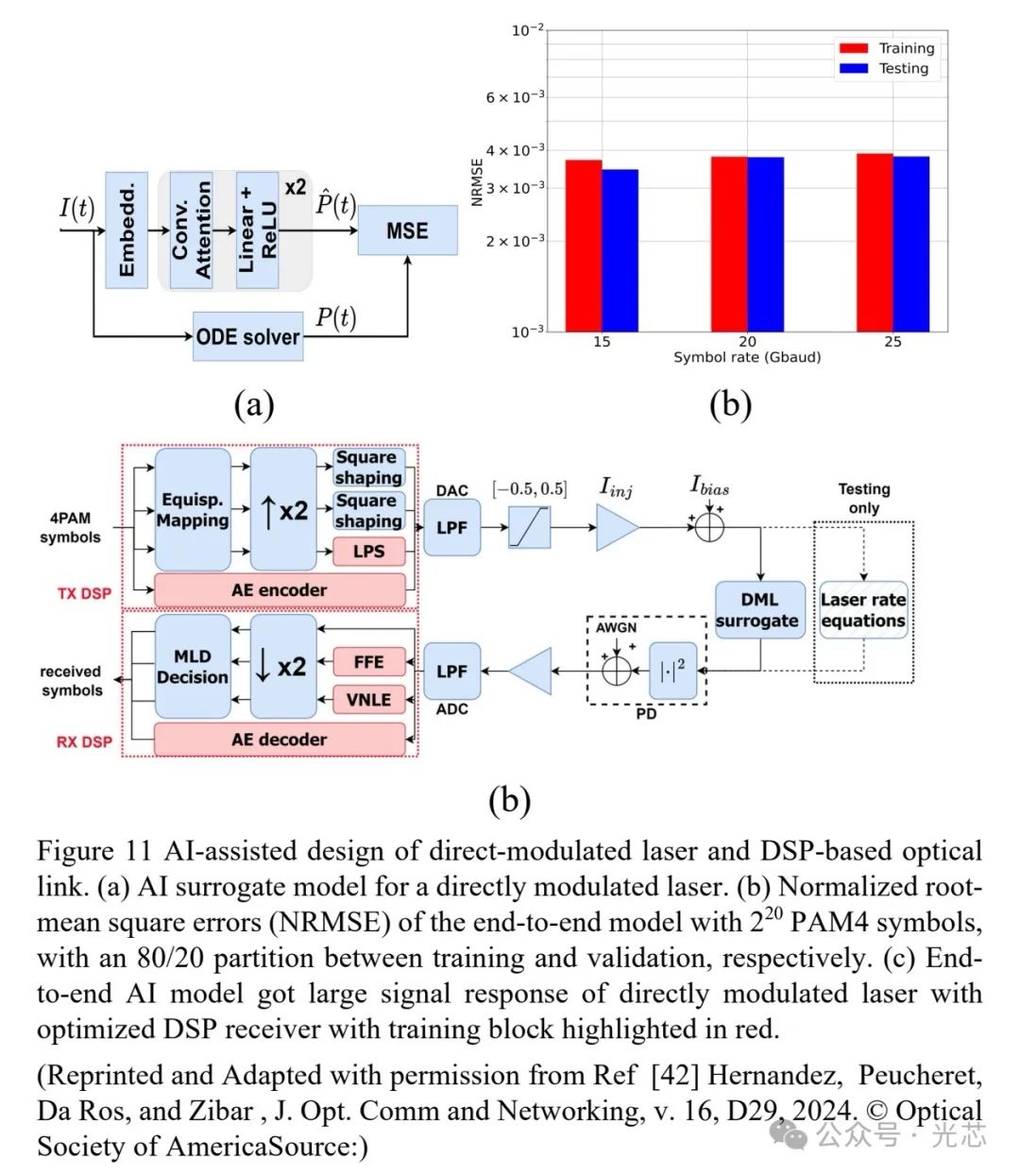
传统物理设计技术在优化光子器件性能时存在局限,AI辅助设计技术应运而生。以耦合腔直调激光器DML为例,虽然目前已经能够实现了超过 100GBaud 的速率 ,然而,将激光器设计与相应的DSP相结合,从而优化所有参数以在高速调制下实现端到端性能(如激光偏置、带宽、大信号特性、啁啾、误码率等)是很困难的。通过利用以速率方程为基础事实的基于物理学的人工智能建模方法,可以借助自动编码器建立一个具有可解释性的替代激光器模型。然后,通过联合优化激光器设计以及相关的 DSP 参数,就能实现目标端到端大信号调制性能 (见图11)。
3.2 AI驱动的光子逆向设计
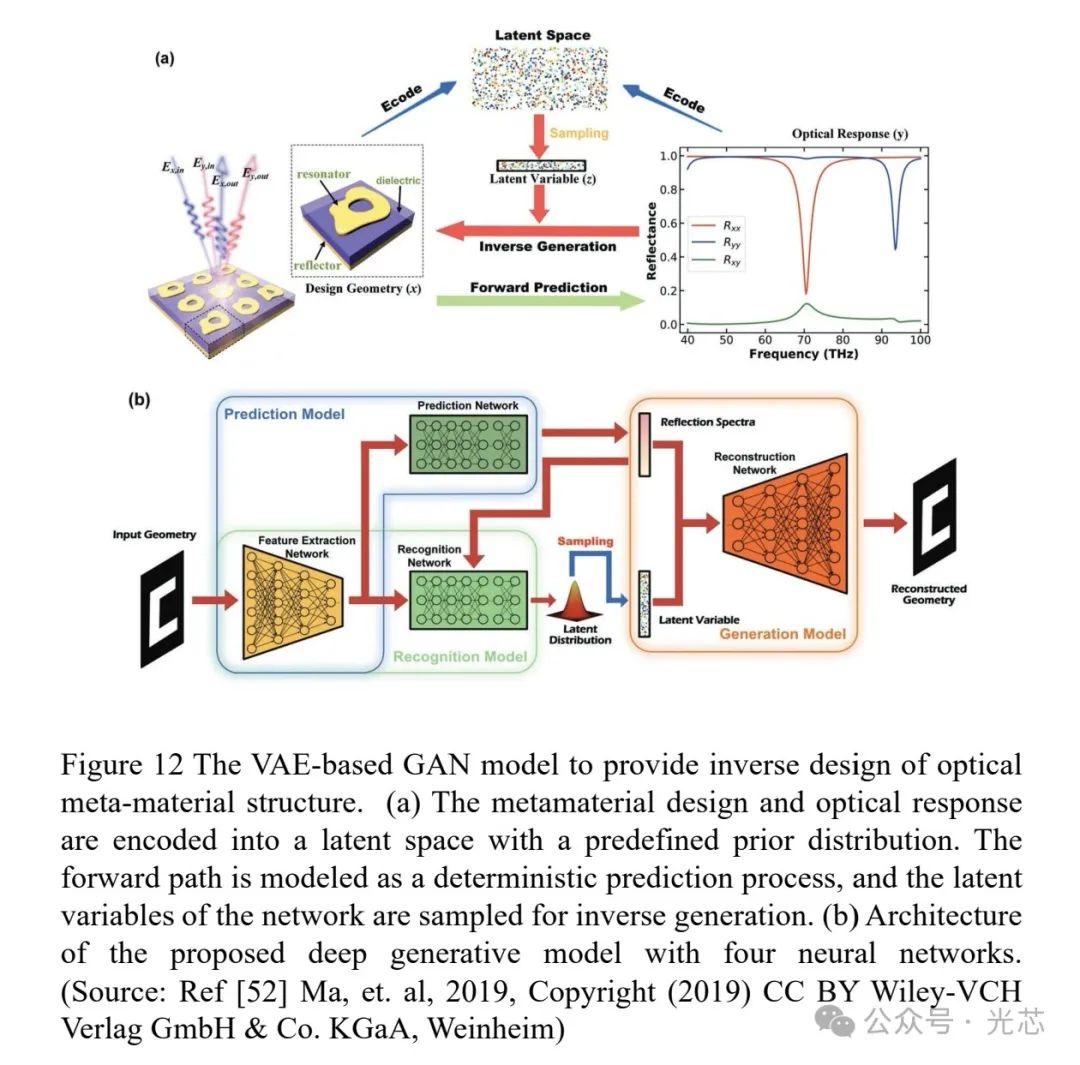
纳米制造技术的进步使纳米光子材料能提供新的光学功能(色散调控、滤波器、偏振控制、谐振腔、带隙工程等),逆向设计技术基于有限元分析的拓扑优化和梯度优化,结合数据驱动的机器学习和AI技术,可实现具有特定功能的纳米光子结构设计。例如,利用基于变分自编码器(VAE)的生成对抗网络(GAN),成功设计出能产生特定光学响应的超材料谐振器(见图12)。其设计策略是将超材料结构及其光学响应被编码到具有先验分布的潜在空间中。网络通过采样潜在变量进行逆向生成,而正向路径则被建模为确定性预测过程。该深度生成模型由三个子模型组成,包括识别模型、预测模型和生成模型。
四、光子学实现高能效AI处理
4.1 AI处理的能源效率
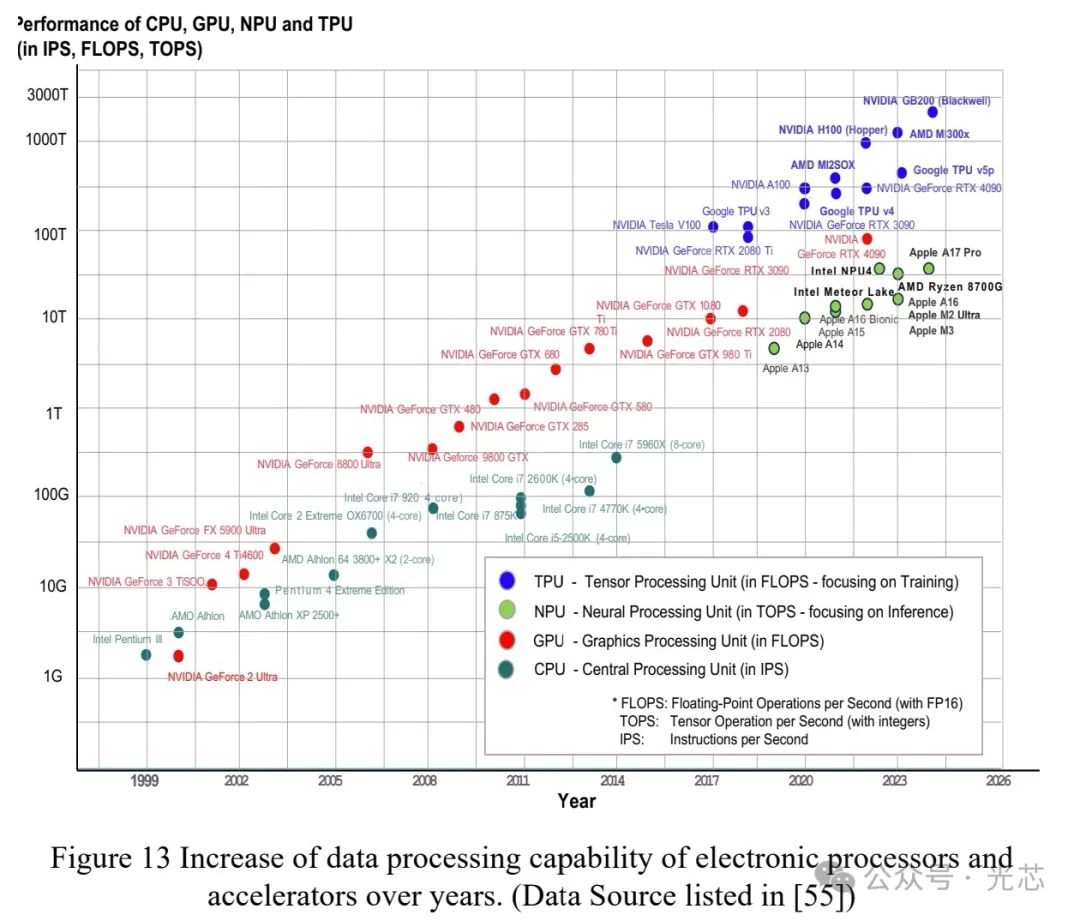
AI处理中的张量运算需要大量的乘法累加(MAC)操作,电子处理器执行这些操作时能耗巨大。以NVIDIA B200加速器为例,它能以2,250 Tera FLOPS的速度进行16位浮点数据的AI训练操作,但功耗高达1,000W,芯片面积为800 mm2,包含2080亿个4nm晶体管,能源效率为400 pJ/OP。根据Landauer公式,擦除一位信息所需的最小能量有限,而实际的电子逻辑开关能耗远高于此,如翻转一个3nm FINFET CMOS反相器需要0.039fJ能量,比Landauer极限高六个数量级。训练大型语言模型需要大量的MAC操作,如训练GPT-3模型(1750亿参数),处理1,000个token需要87.5 T MAC操作,按每个MAC操作0.25fJ的最小能量计算,训练将消耗36 MW的能量。

4.2 高效能光子神经形态网络
受人类大脑启发,研究人员致力于开发高效、可扩展且灵活的非冯·诺依曼处理架构。光子神经形态网络(PNNs)在光学领域进行计算,具有高速、低延迟的优势。与电子神经元相比,光子可作为更优越的神经元元素,实现突触、延迟存储、阈值决策和脉冲生成等功能。通过干涉测量、衰减和非线性等操作,光信号能在低延迟和低能耗的情况下处理信息,并可通过波分复用(WDM)、模式分复用(MDM)和空分复用(SDM)在一个通道中组合或分离,实现复杂计算和信号处理(见图15)。

4.3 光子AI加速器
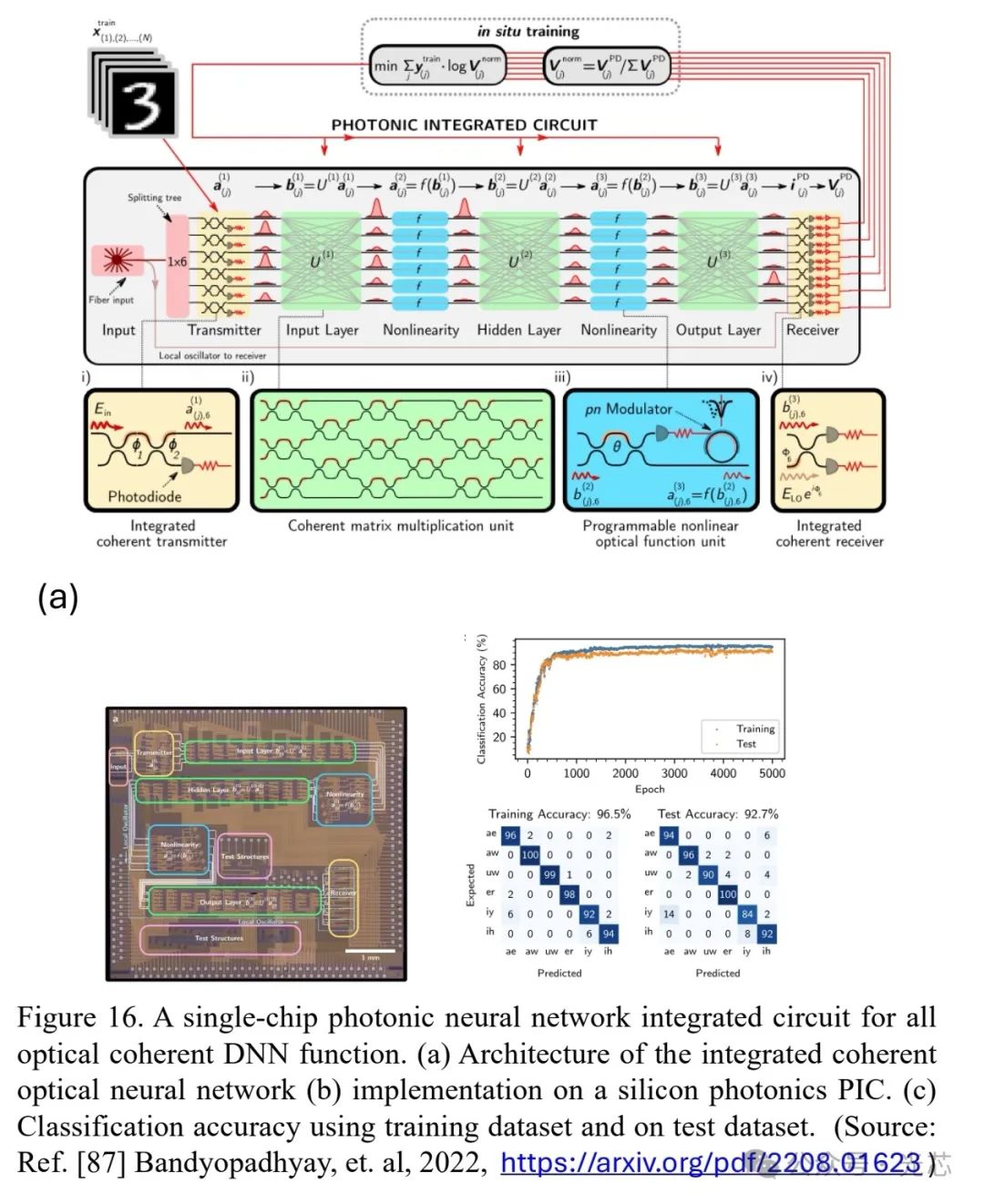
光子组件的特性使其在实现AI/ML操作方面具有优势,如能进行低延迟的MAC操作、傅里叶变换、卷积和延迟时间递归网络计算等。对于光子MAC操作,大规模光网络中每个MAC的最小能量受探测器量子散粒噪声和光电子I/O转换限制,估计为50zJ,对于中等规模的卷积神经网络,10fJ/MAC的光子处理是可行的,与NVIDIA B200张量处理器的1.25pJ/OP(FP16)能耗相当。例如,一个光子加速器集成电路在光学域内实现了相干单次DNN训练和推理功能,用于元音分类,分类准确率在训练数据上达到96.5%,测试数据上达到92.7%,估计延迟为435 ps,片上能耗为9.8 pJ/OP,吞吐量为0.53 TOPS(见图16)。
4.4 高密度3D光子加速器
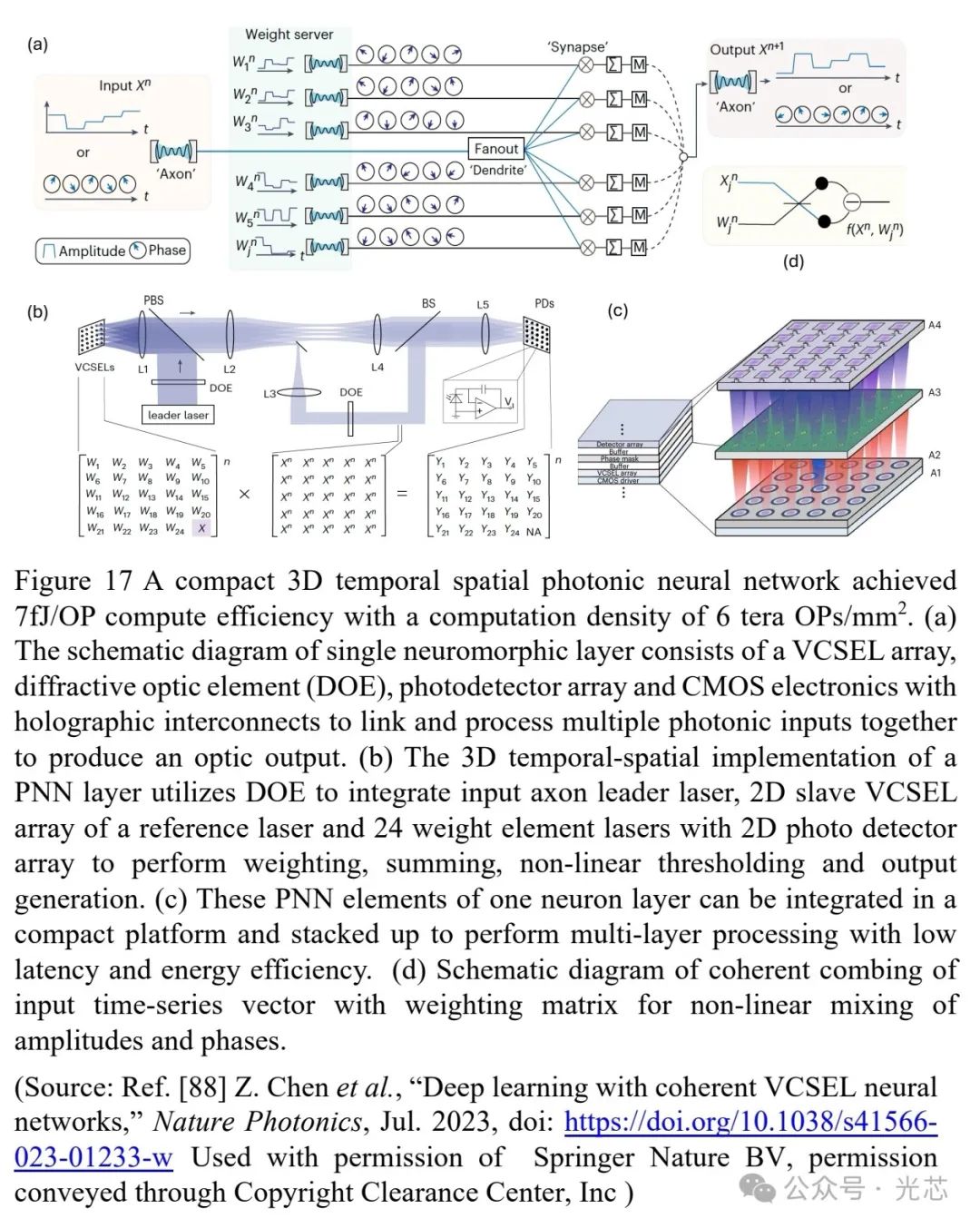
纳米制造技术的进步提高了计算密度,但光子器件的大横向尺寸限制了其面积计算密度。基于VCSEL的3D时空PNN通过空间分集、波长复用和3D光互连,提高了计算密度,达到了7fJ/OP的计算效率和6 tera OPs / mm2的密度。该网络的基本神经形态处理层架构中,输入激光通过衍射光学元件(DOE)扇出到多个光学树突和VCSEL阵列,通过相干组合和非线性混频实现加权和输出(见图17)。
4.5 集成脉冲光子神经形态网络

为进一步提高计算效率和密度,出现了具有波分复用(WDM)光学树突的脉冲光子神经元。如在硅基平台上实现的高速集成WDM PNN,利用Si3N4光频梳作为WDM源,可变光衰减器(VOAs)编码输入向量,相变存储器(PCM)实现光学加权功能,进行并行MAC操作(见图18)。该PNN在MNIST手写识别任务中,对10,000张测试图像的实验准确率达到95.3%,与计算预测准确率96.1%相符,其张量核心操作可扩展到每秒2万亿次操作,每个MAC操作能耗为17 fJ,计算密度超过400 TOPS/mm2。
五、光子学实现先进AI/ML计算
光子处理通过光谱、时间和空间域的多维性,以及前向/后向传播能力,为先进AI/ML运算提供独特优势。其低延迟、低能耗特性特别适合实时应用,如自动驾驶和边缘AI。然而,模拟光计算受限于信号噪声比(典型30-40 dB),导致精度损失(6-7位),影响复杂模型训练。
近期电子领域的降低精度训练技术(如FP4/Integer-8)为光子计算提供了新路径。实验表明,光子处理在48 dB SNR下可实现8位精度,与电子处理相当。结合储备池计算和超维计算等新型架构,光子处理器能效比电子GPU高2个数量级,同时保持可接受的精度。
5.1 光子储备池计算

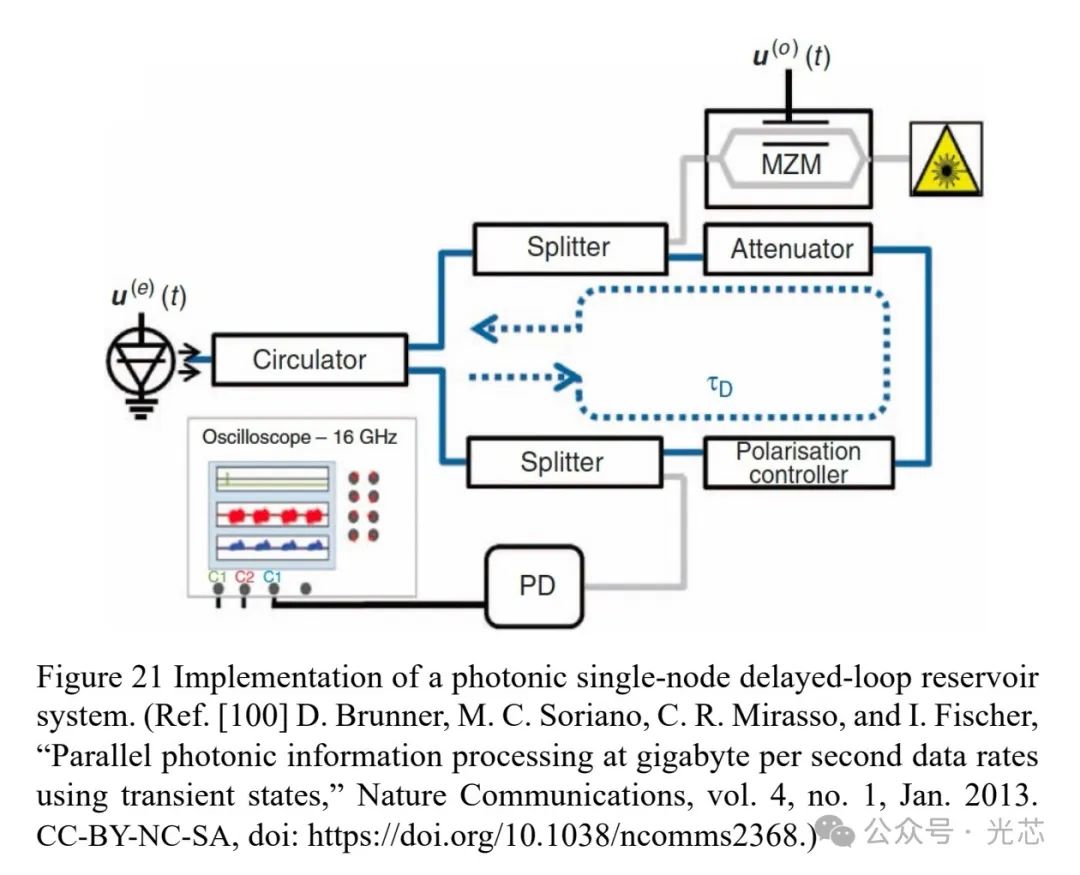
储备池计算是一种机器学习方法,通过固定随机连接的人工神经网络和简单的可训练读出机制处理输入数据。光子学的超快速度和多维度操作特性,使其非常适合实现储层计算架构。在典型的单节点延迟环光子储层系统中,输入数据通过时间复用注入系统,利用非线性节点和延迟反馈,单个动态节点就能处理复杂系统的信息,实现高速处理(见图19)。这种简化的光子硬件实现展示了千兆位的处理速度(见图21)。
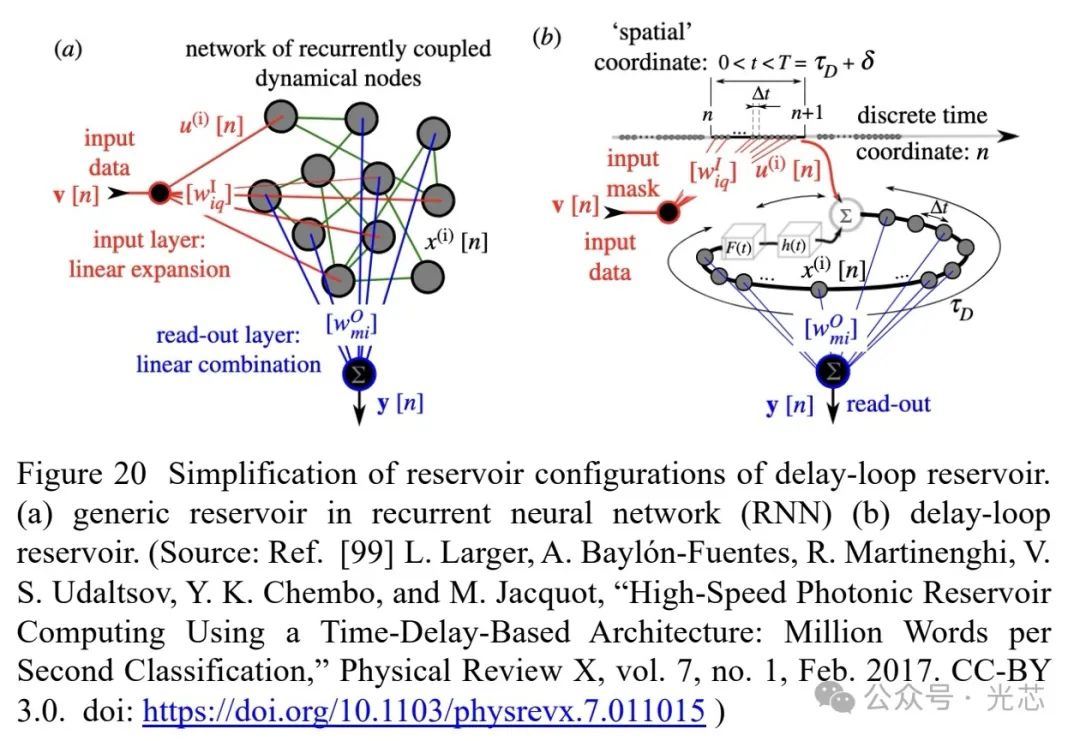
5.2 光子WDM多环储备池计算
为提高计算性能和精度,引入了多个光子延迟环,通过扩展维度增强计算能力。例如,一个WDM多环储备池测试平台用于特定发射器识别(SEI)功能,识别20个RF WiFi设备的发射信号源(见图22)。与电子处理相比,光子WDM DLR处理显著减少了所需存储的模型参数数量(比ResNet少17倍,比LSTM RNN少130倍),计算复杂度相当,计算延迟在训练时比电子RNN降低700倍,推理时降低5倍。
除延迟设计之外,其他光子储备池网络还利用了独特的光学特性,如硅光子芯片上的耦合腔、多模光纤的时空混合、氮化硅频率梳以及衍射超表面光学等。这些技术突破为光子储层计算在实时信号处理、生物医学和工业控制等领域的应用奠定了基础。
六、总结
光子学与AI的融合在多领域取得了显著进展,如在通信、计算、传感等领域都展现出巨大潜力。然而,光子处理受限于有限的信噪比,分辨率不如高精度数字处理器,因此光子AI处理目前更适合边缘推理应用。随着技术的不断发展,光子学与AI的融合有望在电信、高性能计算、医疗保健和环境监测等领域取得更大突破,为未来科技发展带来更多可能性。
腾讯云开发者
