npj Digit. Med. | 利用大型语言模型作为评估者评估临床AI摘要

npj Digit. Med. | 利用大型语言模型作为评估者评估临床AI摘要

DrugAI
发布于 2026-01-06 13:46:52
发布于 2026-01-06 13:46:52
DRUGONE
电子病历(EHR)包含大量临床数据,难以由医务人员有效整合。生成式人工智能(GenAI),尤其是大型语言模型(LLM),能够自动生成摘要,从而减少认知负担,但其准确性需要可靠的评估方法。人工审阅虽为金标准,却耗时且成本高昂。为此,研究人员提出并验证了一种基于LLM的自动化评估框架(LLM-as-a-Judge),用于评估多文档EHR摘要质量。以经验证的“临床文档摘要质量评估量表(PDSQI-9)”为基准,研究发现GPT-o3-mini模型在与人工专家比对中取得组内相关系数(ICC)为0.818,与人工评估结果中位数差异为0,单次评估仅耗时22秒。推理型模型在需要临床推断与专业知识的评估任务中表现尤为突出,优于非推理型与多智能体方法。该方法为实现高效、可扩展的临床AI摘要评估提供了可靠路径。

EHR在集中存储临床信息方面极具价值,但数据量庞大常导致信息过载。医院中约五分之一的入院患者,其电子病历长度堪比小说《白鲸》。虽然EHR改善了信息访问与工作流程,但庞杂记录使临床人员难以快速提炼关键信息,从而可能漏判重要线索。
随着大型语言模型的发展,生成式AI被视为缓解此问题的潜在方案。例如GPT-4等模型能处理超长上下文输入,从多份文档中生成摘要,逐步融入医疗工作流。尽管如此,AI生成的临床摘要仍易出现幻觉(hallucination)、遗漏(omission)与事实错误。特别是在多文档场景下,模型易受“中间遗失效应”影响,忽略细节或时间顺序混乱。
传统自动化指标(如ROUGE或BERTScore)主要用于一般语言任务,无法有效捕捉临床文本中的事实一致性与逻辑连贯性。人工专家评估虽精准,却成本高、速度慢。因此,研究人员尝试让LLM本身充当评估者,利用其语义理解与推理能力,实现AI评估AI的闭环机制。
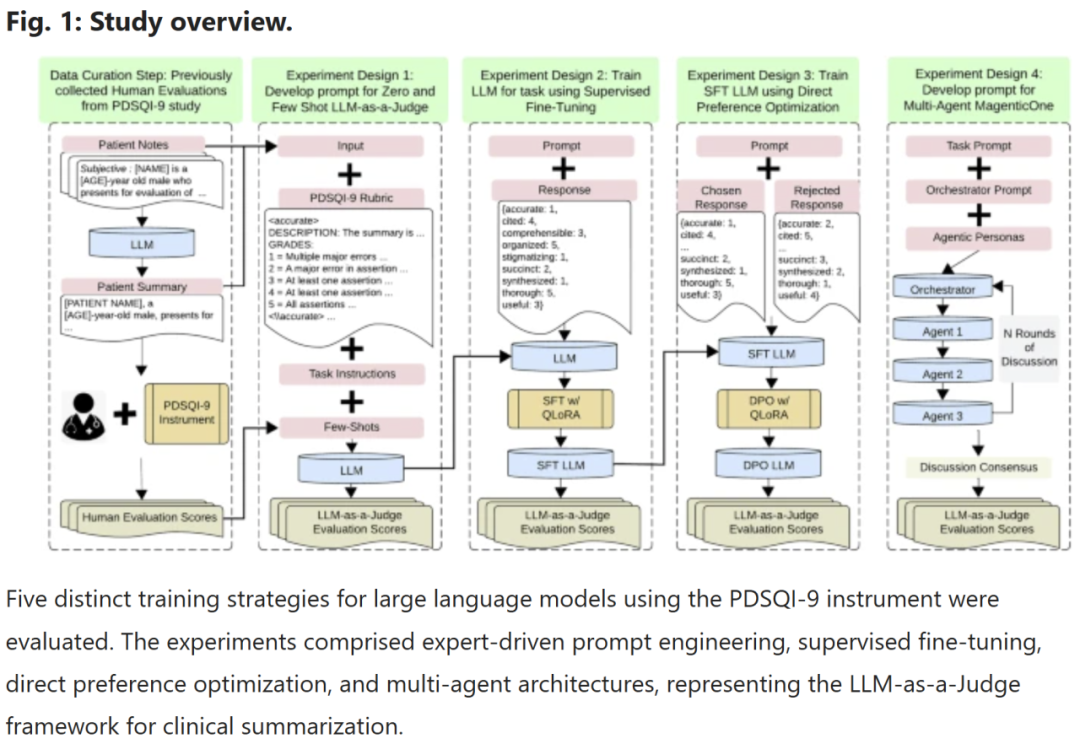
方法概述
研究人员基于PDSQI-9量表构建并验证了LLM-as-a-Judge框架。
- 评估对象:来自威斯康星大学健康系统的EHR多文档摘要,共200份(160训练,40测试)。
- 模型比较:包含开源与闭源LLM,如GPT-4o、GPT-o3-mini、Mixtral 8×22B、Llama 3.1 8B、DeepSeek R1等。
- 提示策略:测试零样本、少样本、监督微调(SFT)、直接偏好优化(DPO)及多智能体架构五种策略。
主要评估指标为与人工专家评分的组内相关系数(ICC),并通过中位数差异与非参数检验验证一致性。
结果
数据特征与实验设置
研究语料由200份真实门诊EHR摘要组成,涵盖五类专业:初级保健、外科、急诊/重症、神经科及其他专科。每位患者包含3至5次既往就诊记录,供LLM进行跨文档整合。训练与测试集在记录数量、词数、专科分布上无显著差异。每份摘要均由七位医生按PDSQI-9九项指标独立评分。
单一LLM评估性能
在单模型框架下,**GPT-o3-mini(5-shot)**表现最佳,ICC达0.818,与人工评估中位数差异为0。推理型模型(GPT-o3-mini、DeepSeek R1)在一致性上优于非推理型模型(GPT-4o、Llama 3.1 8B)。Mixtral 8×22B在零样本下已表现良好(ICC≈0.73),进一步微调收益有限。Llama 3.1 8B经SFT+DPO后性能提升显著(ICC由0.33增至0.56),表明小模型通过偏好优化仍具改进潜力。
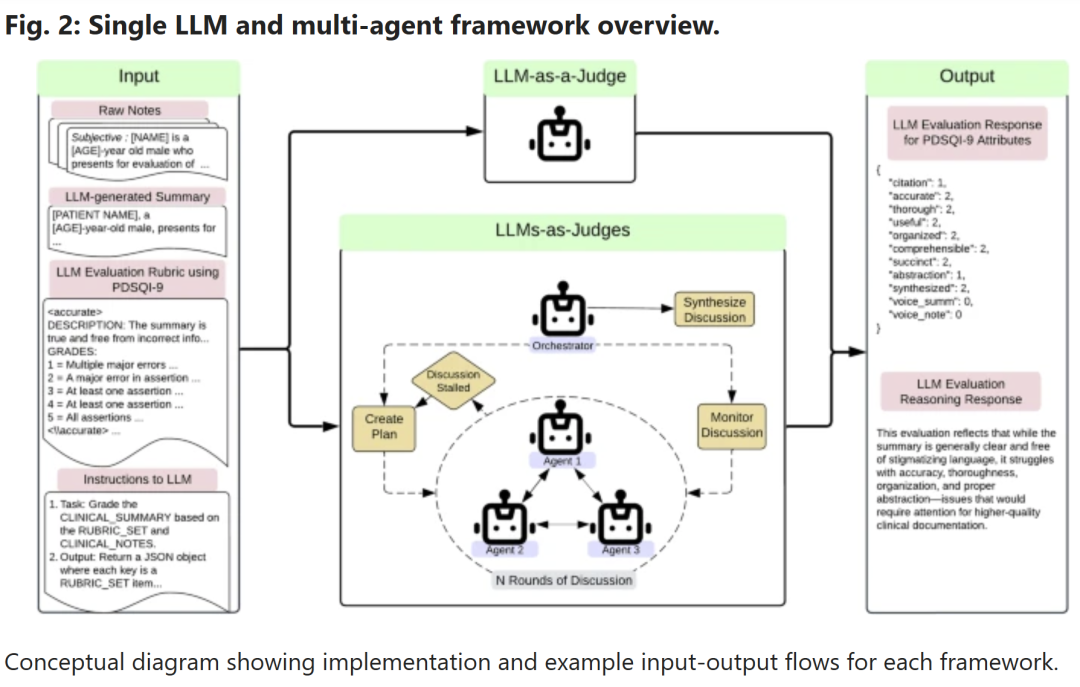
多智能体框架
研究还构建了基于微软AutoGen的多智能体框架(LLMs-as-Judges)。其中各代理(如“分析完美主义者”、“高效多任务者”、“协作医生”)以不同视角评分,由主控代理(orchestrator)整合结果。最佳多智能体配置(全部使用GPT-o3-mini)达ICC=0.768,虽略低于单模型,但能更真实反映人类评审的多样性。
跨任务验证
为检验可迁移性,研究在ProbSum 2023诊断摘要任务上进行交叉验证。GPT-o3-mini(5-shot)再次表现优异,ICC=0.710,显示其框架在不同任务与数据集上均具鲁棒性。
成本与时间效率
相比人工评估平均需600秒且成本约50美元,GPT-o3-mini单次评估仅需22秒,成本约0.05美元,实现了96%的时间节约与千倍成本优势。训练成本中,Mixtral 8×22B的SFT与DPO分别耗时24与60小时,使用两张H100 GPU。
误差与偏差分析
为排除模型偏好自身生成内容的风险,研究比较了不同源摘要的评估一致性,结果无显著偏差。推理型模型在“引用充分(Cited)”、“组织清晰(Organized)”与“综合性(Synthesized)”等维度与人工最一致。例如在“综合性”评分中,GPT-4o倾向打高分,而GPT-o3-mini能更细致地区分是否真正形成连贯临床判断,显示更接近专家推理逻辑。
讨论
研究验证了医疗领域中首个LLM-as-a-Judge自动评估框架,其评估结果与人类医生高度一致。GPT-o3-mini作为推理型模型,在准确性、一致性与速度方面均显著优于传统评估方式。
研究人员指出,LLM-as-a-Judge的关键在于:
- 可靠的评估量表设计(如PDSQI-9);
- 清晰的提示模板和评分准则;
- 合理的输出约束,确保格式和语义一致。
推理型模型在涉及复杂临床逻辑时表现突出,而多智能体框架虽提高多样性,却增加计算成本。小模型可通过偏好优化获得改进,但稳定性和细粒度区分能力仍有限。
未来方向包括:
- 在更大规模、多机构EHR数据中外部验证;
- 探索评估框架在医疗问答、报告生成等任务的应用;
- 构建生成–评估闭环系统,让评估模型实时反馈以优化生成质量,从而实现临床AI的自动质量控制。
整理 | DrugOne团队
参考资料
Croxford, E., Gao, Y., First, E. et al. Evaluating clinical AI summaries with large language models as judges. npj Digit. Med. 8, 640 (2025).
https://doi.org/10.1038/s41746-025-02005-2
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号