Nat. Mach. Intell. | 自回归等变网络实现无显式力计算的分子动力学

Nat. Mach. Intell. | 自回归等变网络实现无显式力计算的分子动力学

DrugAI
发布于 2026-05-08 19:55:17
发布于 2026-05-08 19:55:17
分子动力学(MD)模拟是现代科学研究中的核心工具,但其高昂的计算成本长期限制了可模拟的时间尺度与系统规模。传统方法需要在每个时间步中计算原子间作用力,并通过数值积分推进体系演化,因此通常只能使用极小时间步长。
在本研究中,研究人员提出了 TrajCast,一种基于自回归等变消息传递网络(autoregressive equivariant message-passing network)的新型框架。与传统机器学习势函数不同,TrajCast不再预测原子间力,而是直接预测体系下一时刻的原子位置与速度,从而摆脱了传统积分器对小时间步的依赖。
研究人员在小分子、晶体材料以及液体体系上验证了该方法。结果表明,TrajCast能够在结构、动力学和能量学性质上与传统MD高度一致,同时实现比传统MD大10–30倍的时间步长。更重要的是,该模型能够在零样本条件下泛化到训练数据之外的相空间区域,包括亚稳态和平衡外动力学过程,并仍保持良好的物理合理性。
在实际性能方面,TrajCast可为包含4,000多个原子的石英体系每天生成超过15 ns的轨迹数据,大幅超越传统模拟方法。研究人员认为,该框架有望显著推动材料发现与复杂物理过程研究。

分子动力学模拟广泛应用于蛋白折叠、材料相变、超冷液体以及非晶化等问题研究。其核心思想是通过数值积分牛顿运动方程,得到原子随时间变化的位置与速度轨迹。
然而,高精度MD模拟通常面临两个根本性瓶颈。首先,需要高成本电子结构计算以获得精确作用力;其次,由于积分误差会随时间步长快速累积,因此通常必须采用0.5–1 fs级别的微小时间步。即使借助现代GPU与并行计算,第一性原理MD仍难以扩展到大尺度和长时间过程。
近年来,机器学习势函数(MLIPs)显著加速了力的计算,例如NequIP、MACE等等变图神经网络方法能够在接近从头算精度下模拟更大体系。然而,这类方法本质上仍依赖传统积分器,因此无法突破小时间步限制。
与此同时,生成式AI方法开始被用于直接生成分子轨迹。例如Boltzmann生成器可以直接采样平衡构象,而Timewarp等模型则尝试自回归预测轨迹。但这些方法往往只能预测位置,缺乏速度信息,从而无法完整描述体系动力学。
基于这些问题,研究人员提出TrajCast,希望直接学习“运动本身”,而非学习力场。
方法
TrajCast的核心思想是:利用等变消息传递网络直接预测未来状态,而不显式计算作用力。
该模型输入当前时刻的原子位置、速度以及原子类型,并通过多个等变消息传递层学习局部原子环境之间的动态关系。与传统ML势不同,TrajCast并不输出势能或力,而是直接预测较长时间间隔Δt之后的新位置和新速度。
为了保证物理合理性,模型在预测过程中显式约束总线性动量与角动量守恒。同时,在长时间自回归生成中,研究人员引入CSVR恒温器,通过随机速度重标定维持体系温度稳定,并避免误差累积导致轨迹发散。
由于模型采用局部环境编码,因此具备良好的可扩展性和迁移能力,可以在小体系上训练,并推广到更大的系统。
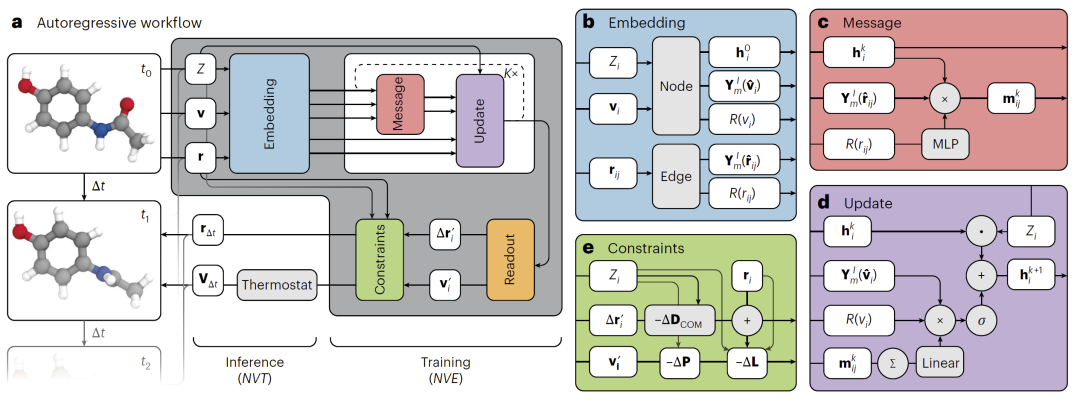
图1:TrajCast整体框架与自回归等变网络结构。
结果
小分子体系:对乙酰氨基酚(Paracetamol)
研究人员首先在气相对乙酰氨基酚分子上测试TrajCast。模型仅使用10,000个训练构象,并采用7 fs预测步长,相当于传统MD时间步的14倍。
结果显示,TrajCast生成的振动态密度(VDOS)与传统MD几乎完全一致,各元素频率峰高度重合,且不存在传统大步长积分中常见的频率漂移问题。
在能量分布方面,TrajCast生成轨迹与Boltzmann分布高度吻合,说明其能够正确恢复体系热力学特征。
研究人员进一步分析了分子自由能面(FES),特别关注两个二面角ψ₁与ψ₂控制的构象翻转。尽管训练集中从未出现某些翻转构象,TrajCast仍然能够在自回归过程中成功生成这些状态,并准确恢复自由能势垒。这表明模型具有超出训练分布的泛化能力。
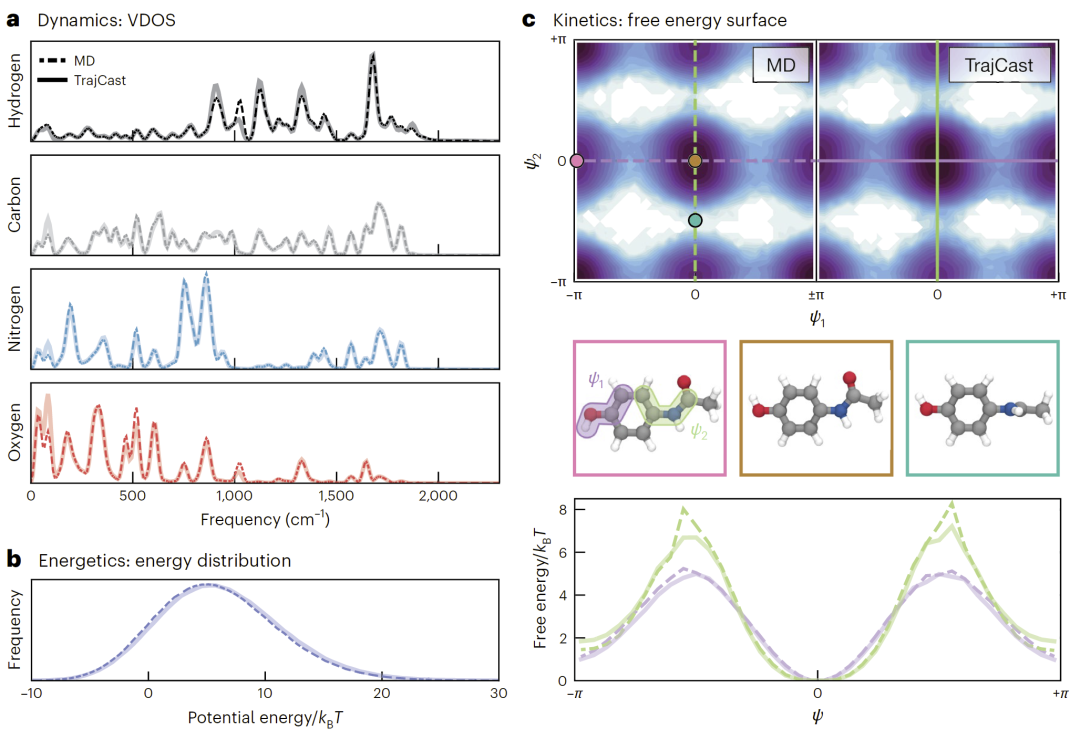
图2:TrajCast与传统MD在对乙酰氨基酚动力学和自由能面上的比较。
晶体体系:α-石英(Quartz)
随后,研究人员将TrajCast扩展到凝聚态材料——晶体α-石英。由于晶格中原子运动更加受限,模型能够进一步增大预测时间步长至30 fs,相当于传统MD的30倍。
在长达15 ns的轨迹中,TrajCast生成的振动态密度与参考MD高度一致,VDOS重叠度超过0.95。同时,其势能分布与MD几乎完全重合,说明模型能够准确捕捉晶体振动与热力学行为。
更重要的是,该方法表现出极高的可扩展性。研究人员在包含约4,300个原子的石英超晶胞中实现了每天近20 ns轨迹生成速度,而传统MACE模型通常只能达到约1 ns/天。
研究人员认为,这种能力对于研究低缺陷浓度材料和长时间尺度晶体动力学具有重要意义。
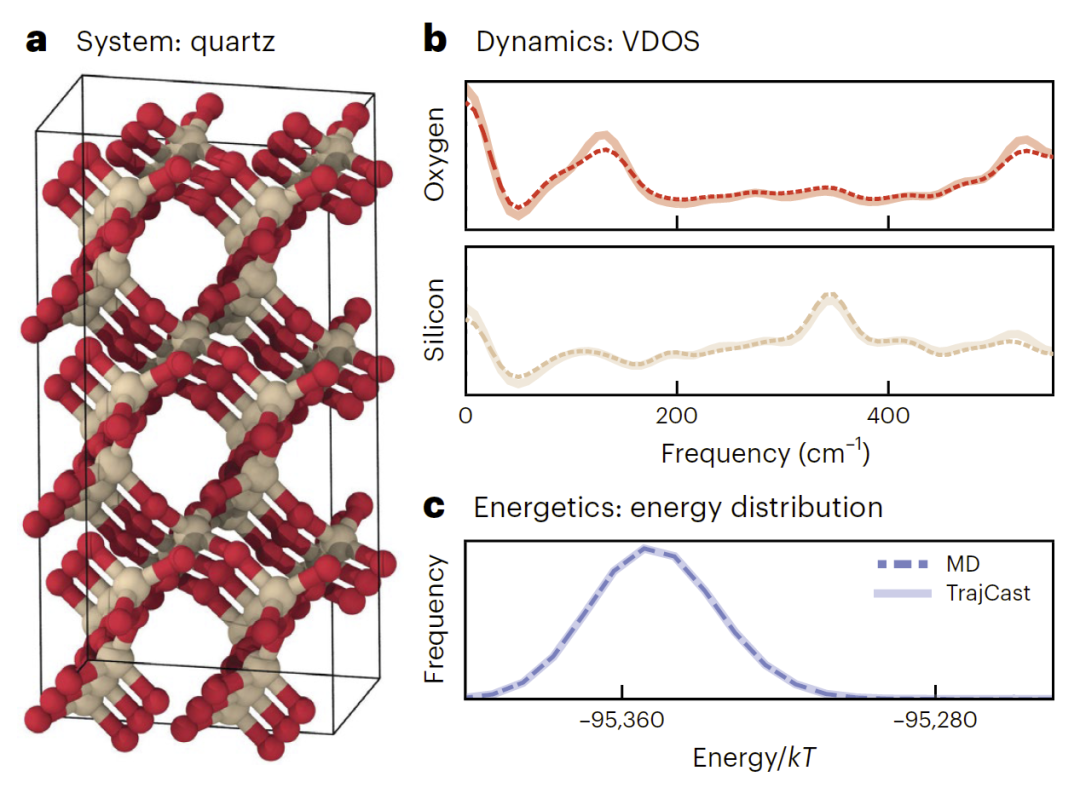
图3:TrajCast在晶体石英中的结构与能量学验证。
液体体系:体相水(Bulk Water)
在液态水体系中,研究人员使用64个水分子训练模型,并采用5 fs预测时间步长。虽然步长低于石英体系,但仍是传统MD的10倍。
结果显示,TrajCast在整个频率范围内准确恢复了氧和氢的振动态密度,说明其同时正确描述了分子内高频振动与分子间低频运动。
在均方位移(MSD)分析中,TrajCast与MD在短时间尺度高度一致,并给出了接近的扩散系数。这说明模型不仅能够恢复静态结构,还能够准确预测液体输运性质。
此外,在径向分布函数(RDF)分析中,各元素组合的结构峰位置与高度均与MD高度吻合,仅在O–O分布中出现轻微欠结构化现象。
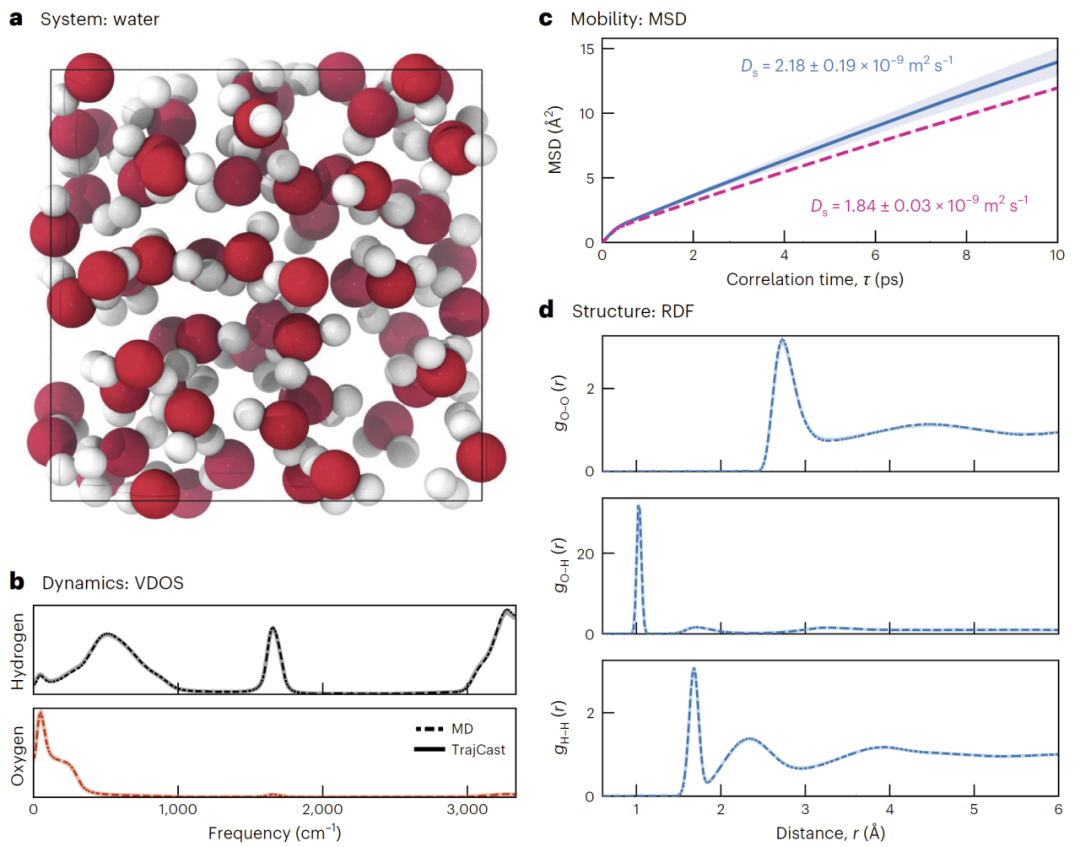
图4:TrajCast在液态水中的动力学与结构性质验证。
零样本泛化:超淬火玻璃态水
为了测试模型是否能够泛化到训练数据之外的相空间,研究人员进行了一个极具挑战性的实验:利用仅在室温液态水上训练的模型,预测水在冷却过程中形成超淬火玻璃态(HGW)的过程。
在从300 K冷却至180 K的过程中,TrajCast生成的所有轨迹均保持稳定,没有出现发散。模型预测的扩散系数与参考MD在整个温度范围内高度一致,并成功捕捉了约210 K附近出现的动力学冻结现象。
同时,氧–氧径向分布函数在不同温度下与MD几乎无法区分。研究人员进一步利用平移序参数τ与取向序参数Q分析结构变化,发现TrajCast与MD在τ–Q平面中沿相同路径演化。
这说明TrajCast不仅能够恢复平衡液体行为,还能够准确模拟玻璃化等复杂非平衡过程。
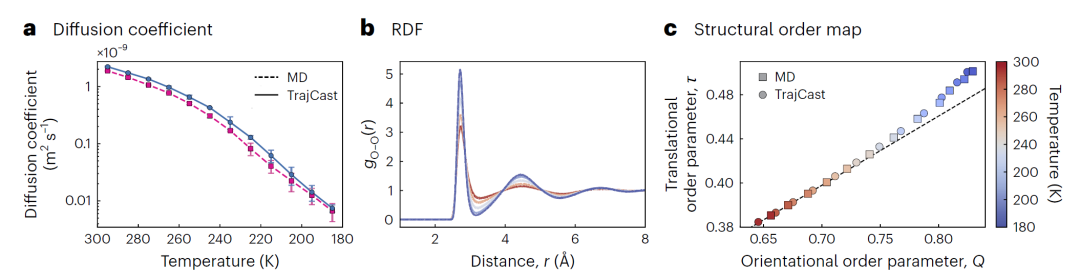
图5:TrajCast零样本预测玻璃态水形成过程。
可扩展性与数据效率
研究人员系统分析了预测步长与训练数据量对模型性能的影响。
结果表明,随着预测步长增加,速度误差会逐渐增大,但不同体系对误差容忍度不同。例如石英体系即使在较大误差下仍保持稳定,而液态水则更容易因误差累积而失稳。
在数据效率方面,TrajCast表现尤为突出。研究人员发现,其学习曲线缩放指数明显优于传统ML势函数。这意味着TrajCast能够从较少数据中学习更多动力学信息。
实际上,该模型仅需数百皮秒训练数据即可达到较高精度,而许多生成式轨迹模型通常需要数百纳秒训练数据。
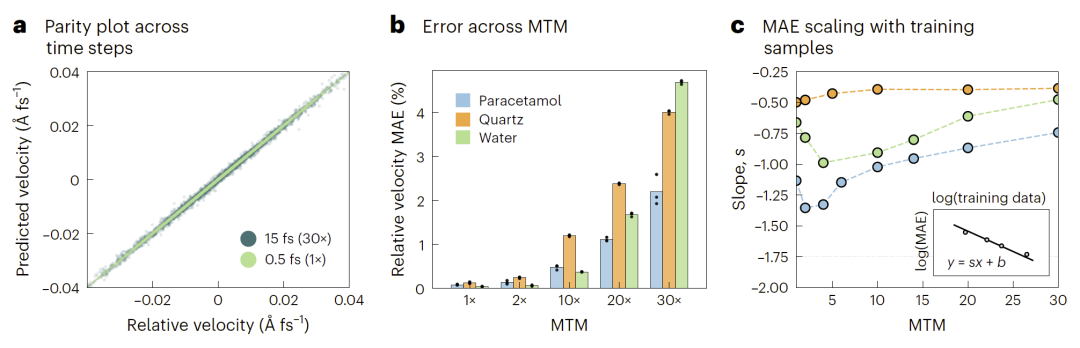
图6:预测时间步与训练数据量对TrajCast性能的影响。
讨论
本研究提出了一种“无力场”的分子动力学新范式。与传统方法不同,TrajCast不再通过作用力积分推进体系,而是直接学习原子运动轨迹,从而突破了传统积分器对小时间步的限制。
研究人员认为,该方法最大的优势在于同时兼顾了速度、精度与可扩展性。通过引入速度信息和等变结构,模型能够恢复完整相空间动力学,并准确预测时间相关性质。
更重要的是,TrajCast展示出超出训练分布的泛化能力。例如,在从未见过玻璃态结构的情况下,模型仍成功预测了超冷水玻璃化过程。这表明其不仅是在“记忆轨迹”,而是真正学习了体系动力学规律。
不过,研究人员也指出了一些局限。目前TrajCast仍采用固定预测步长,并且由于不显式计算力,因此难以直接获得压力等力相关性质。此外,当前工作主要基于经典力场数据,未来仍需进一步扩展到第一性原理MD数据。
总体而言,TrajCast代表了AI驱动MD模拟的重要方向:从“学习势能面”转向“直接学习运动”。研究人员认为,这种方法有望大幅推进长时间尺度、多尺度以及复杂非平衡过程模拟,并可能成为未来分子动力学基础模型的重要组成部分。
整理 | DrugOne团队
参考资料
Thiemann, F.L., Reschützegger, T., Esposito, M. et al. Force-free molecular dynamics through autoregressive equivariant networks. Nat Mach Intell (2026).
https://doi.org/10.1038/s42256-026-01227-7

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号