深度学习主流方法概述


深度学习是基础学习机制,简单来说,深度学习是机器学习的一个子集,通过构建包含多个处理层(即“深度”)的神经网络模型,来自动从海量数据中学习更抽象、更高层级的特征,从而让机器具备“理解”和“决策”的能力。
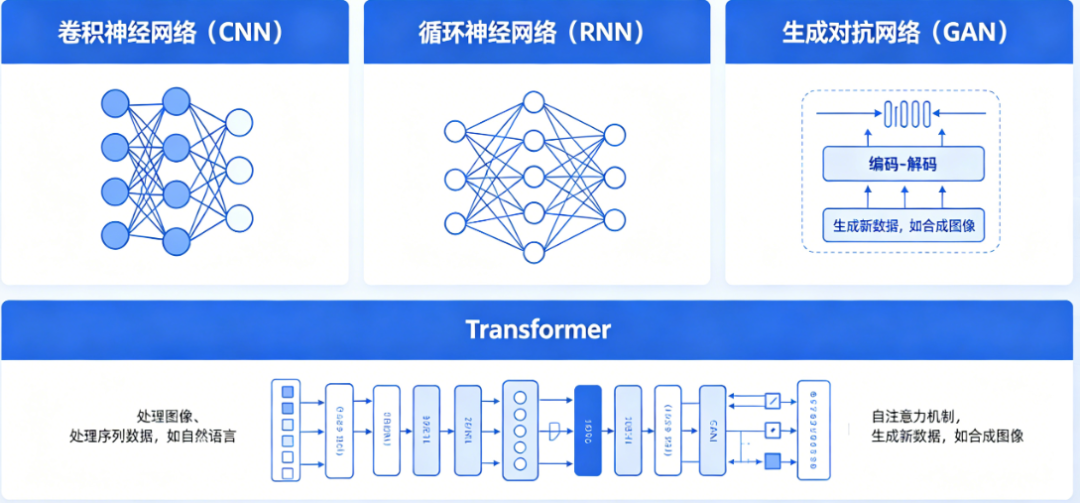
主流的深度学习方法按照核心任务分了三类进行对比:
核心任务 | 核心网络架构 | 核心理念 | 主要应用场景 | 与VLA/清洁机器人的联系 |
|---|---|---|---|---|
提取特征“理解世界” | 卷积神经网络 (CNN) | 通过卷积核提取图像的局部空间特征,逐层构建对全局的理解。 | 图像识别、物体检测、图像分割等。 | 视觉感知: 处理摄像头图像,识别污渍等,是VLA模型的视觉基础。 |
循环神经网络 (RNN) 及其变体 (LSTM, GRU) | 通过“记忆”状态来处理序列数据,捕捉时间上的依赖关系。 | 语音识别、机器翻译、股票预测等。 | 时序建模: 分析连续的力反馈数据、预测机械臂的运动轨迹。 | |
Transformer & 自注意力机制 | 通过“注意力”机制并行计算序列中所有元素间的关系,能更好地捕捉长距离依赖。 | 现代VLA模型的基石、自然语言处理、大规模预训练模型。 | VLA模型核心: 正是你项目中VLA模型(如SmolVLA、OpenVLA)所依赖的基础架构。 | |
生成数据“创造世界” | 生成对抗网络 (GAN) | 通过生成器和判别器两个网络的相互博弈,以假乱真地生成数据。 | 图像生成、风格迁移、数据增强等。 | 数据增强: 可以生成不同形态或污渍的合成图像,用于扩充训练数据。 |
变分自编码器 (VAE) | 学习数据的潜在概率分布,并能从这个分布中采样,生成新的、多样化的数据。 | 图像生成、异常检测、数据压缩等。 | 异常检测: 学习“干净”的分布,若机器人感知到不符合此分布的图像或力信号,则可判断为异常或脏污。 | |
智能决策“行动世界” | 深度强化学习 (DRL) | 将深度学习的感知能力与强化学习的决策能力结合,在复杂环境中通过试错学习最优策略。 | 机器人控制、游戏AI (AlphaGo)、自动驾驶。 | 闭环控制与技能优化: 正如我们之前讨论的,用于微调清洁动作、学习复杂曲面上的柔性跟随策略。 |
高效学习“举一反三” | 迁移学习 (Transfer Learning) | 将一个任务(源任务)上学到的知识,应用到另一个不同但相关的任务(目标任务)上,加速新任务的学习。 | 几乎所有深度学习的落地项目,特别是数据稀缺的场景。 | 快速部署: 这是微调的理论基础。在通用VLA模型上,用你的清洁数据进行微调,就是迁移学习的典型应用。 |
PART 01
深度学习核心方法解析
卷积神经网络 (CNN) —— 视觉感知
CNN通过模拟人类视觉系统的分层处理机制,能够自动从图像中提取特征,通过独特的“卷积”和“池化”操作,在有效减少参数量的同时,保留了对平移、缩放等变化的不变性,因此在图像相关的任务上表现卓越。
循环神经网络 (RNN) 与 Transformer —— 序列处理
RNN : 其核心是一个“循环”结构,能够将过去的信息传递到当前的计算中,因此天生适合处理如语音、文本、时间序列等具有先后顺序的数据,但它在处理长序列时容易出现“遗忘”或“梯度消失”的问题。
Transformer : 它抛弃了RNN的顺序处理模式,完全依赖“自注意力”机制。这使其能并行处理整个序列,并直接捕捉任意两个元素之间的关系,极大地提升了对长距离依赖的建模能力和计算效率。
生成对抗网络 (GAN) 与 变分自编码器 (VAE) —— 创造新数据
两者都属于生成模型,旨在学习训练数据的分布,并生成与原始数据相似但全新的样本。
GAN : 由一个“伪造者”(生成器)和一个“鉴别者”(判别器)相互博弈,最终生成器能创造出以假乱真的数据。
VAE : 它学习将输入数据编码成一个概率分布(如正态分布),然后从这个分布中随机采样解码,从而生成多样化的新数据。
深度强化学习 (DRL) —— 从试错中学会决策
DRL的核心是让一个“智能体”(Agent)在与环境的交互中,通过尝试不同动作并观察获得的奖励或惩罚,来学习“什么状态下该做什么动作”的最优策略。它为机器人赋予了在真实世界中自主学习和执行复杂任务的能力。
PART 02
总结
深度学习的核心在于 层级化的自动特征提取 ,通过不同架构的设计,来解决不同性质的问题。在我们讨论的清洁机器人项目中,一个典型的AI系统(比如VLA模型)会组合运用这些方法:
- 用 CNN 或 Transformer 来处理视觉输入(看见)。
- 用 Transformer 作为VLA的主干网络来融合信息并做出初步决策(“理解”并“规划”动作)。
- 最终,由 深度强化学习(DRL) 来精细地执行和控制机械臂(“执行”清洁动作),完成整个智能闭环。
这些方法各有侧重,但最终的目标都是让机器能更好地“理解、创造和行动”。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号