西藏和海南,同一个因素效果完全相反

西藏和海南,同一个因素效果完全相反

renhai
发布于 2026-06-08 15:11:51
发布于 2026-06-08 15:11:51
海拔越高,结核病越多。听上去合理,因为高原缺氧、医疗条件差、交通不便。但如果把同样的逻辑用到海南,结论完全反过来了:在海南,地形起伏更大的地方,结核病反而更少。
🏔️ 西藏
西藏 3D 地形
西藏平均海拔 4000m+,海拔范围 110~8844m,面积 122.8 万 km²
🌴 海南
海南 3D 地形
海南平均海拔 168m,海拔范围 0~1867m,面积 3.54 万 km²
同一个因素,方向完全相反。
这不是论文的 bug,而是现实世界的真实模样。传统的回归分析假设「一个因素只有一个效果」,但在中国这种地理条件差异巨大的地方,这种假设经常翻车。2025 到 2026 年,三个中国研究团队各自用空间回归方法回答了不同的问题,每一次都撞上了同一面墙:全局模型给出的答案是错的,至少是不完整的。
1. 为什么同一个变量,西藏和海南方向相反?
2025 年底,一篇发表在 International Journal of Health Geographics[1] 的论文用 MGWR 模型分析了中国 31 个省份的结核病发病率。
MGWR 是什么?先不管这个名字,记住一件事:它能让模型在不同地方用不同的系数或者同一个因素在不同省份可以有不同甚至相反的影响力。
研究团队从一堆指标里筛出了 7 个关键变量:**海拔、地形起伏度、降水、人均可支配收入、人口密度、高等教育在校人数、高等教育毕业生数。**然后分别用三种方法跑:
模型 | R² |
|---|---|
OLS(普通最小二乘) | 0.61 |
GWR(地理加权回归) | 0.87 |
MGWR(多尺度地理加权回归) | 0.94 |
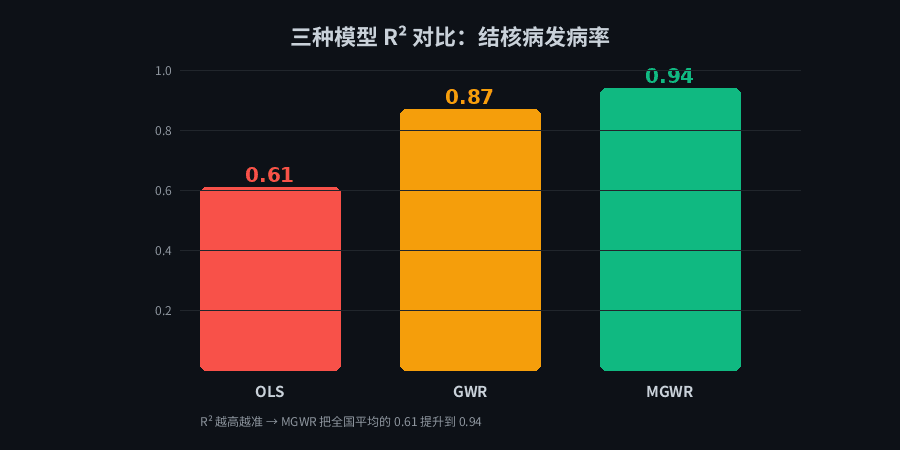
三种模型 R² 对比:OLS 0.61、GWR 0.87、MGWR 0.94
R² 是什么?简单说就是模型猜得准不准。0.61 意味着只能解释 61% 的变化,0.94 意味着几乎全猜对了。
OLS 把全国当成一个整体,给地形起伏度算出一个「平均系数」。MGWR 允许每个省份有自己的系数。结果出来了:
- 西藏:地形起伏度系数 +0.65。起伏越大,发病率越高。道理说得通——地形起伏大的地方交通困难、医疗资源匮乏。
- 海南:地形起伏度系数 -0.16。起伏越大,发病率反而越低。海南海拔整体低,起伏大的地方是山区,人口稀疏,传播机会少。
MGWR 模型下,同一个变量在不同省份的系数方向完全相反。
📐 地形起伏度是什么?它是衡量一个区域内地表高低差异大小的指标。数值大 = 这个地方山高谷深、起伏剧烈;数值小 = 这个地方地势平缓。西藏的起伏度远大于海南(高原 vs 热带低地),所以同一个变量 +0.65 和 -0.16 的含义完全不同。
同样叫「地形起伏度」——在西藏,起伏越大的地方发病越多(+0.65);在海南,起伏越大的地方发病反而越少(-0.16)。你拿一个全国平均值来指导政策,在西藏会低估问题,在海南会高估问题。
这篇论文还做了 2005-2020 年的长时间序列验证,MGWR 的 R² 依然稳定在 0.889。这不是某一年的巧合,是一个持续存在的空间规律。
2. 上海通勤:地铁站影响几公里,企业密度影响全城
第二个案例贴近每个上海打工人的日常。
2026 年,上海理工大学和上海市城乡建设交通发展研究院的研究团队用手机信令数据分析通勤距离。他们拿到了 2021 年 5 月某一周的 77.8 万条早高峰通勤记录。论文发表在 Land[2]。
上海的平均通勤距离已经超过 9.5 公里。这个数字背后,哪些因素在起作用?
MGWR 发现了一个反直觉的现象:同一个指标"企业密度",在不同地方的作用完全相反。
打个比方:
- 你住在浦东,家门口就有一堆公司(居住地企业密度高)→ 你走路就能上班,通勤距离很短。系数 -0.213,意思是企业密度每增加一档,通勤距离缩短 0.213 公里。
- 但如果你在陆家嘴上班(就业地企业密度高)→ 全上海的人都想来这里上班,通勤距离反而更长。系数 +0.172,意思是企业密度每增加一档,通勤距离增加 0.172 公里。
同一个"企业密度",在你家门口是好事(缩短通勤),在你上班的地方是坏事(拉长通勤)。 如果只看全市平均系数,这两个效应会互相抵消,结论变成"企业密度对通勤没影响"——但实际上影响大得很,只是方向不同。
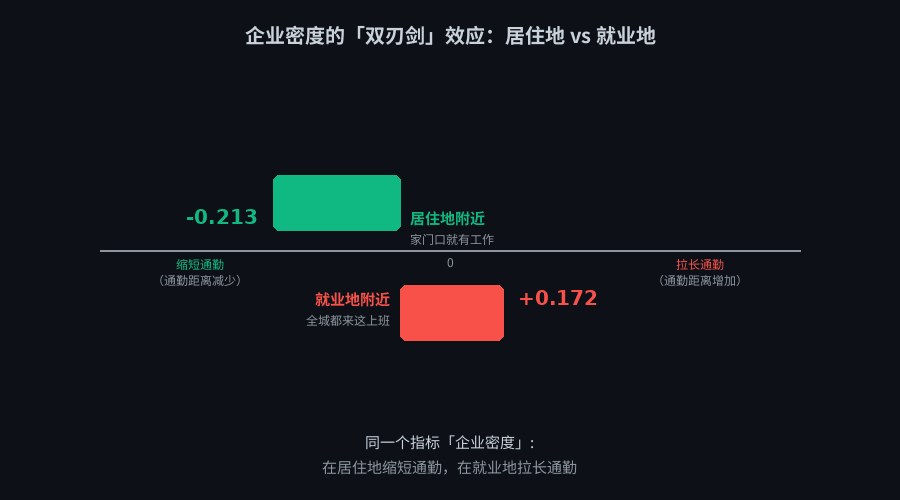
企业密度的「双刃剑」效应
「家门口有工作」和「全城都来这工作」用的是同一个指标——企业密度。一个缩短通勤,一个拉长通勤。
如果只看全局平均系数,这两个效应会互相抵消,结论变成「企业密度对通勤没影响」。实际上影响大得很,只是方向不同。地铁站的影响被企业密度的大范围信号淹没了——这就是为什么 MGWR 比 GWR 更适合这种场景:不同变量的影响范围差了好几倍,用同一把尺子量不准。
3. 四川 GDP:卫星灯光看不到高原的穷
第三个案例回答一个很实际的问题:如果官方 GDP 数据不公开到县级,能不能用卫星数据估?
2026 年,一篇发表在 MDPI Applied Sciences[3] 的论文用夜间灯光数据估算四川 183 个县的 GDP。思路很直觉——灯越亮的地方经济越活跃。
但只用夜间灯光跑 GWR,R² 只有 0.662。
为什么不准?这要从卫星灯光的工作原理说起。
卫星拍摄夜间灯光时,它看到的是人造光源的亮度——路灯、写字楼、商场、住宅区的灯光。但高原地区有几个天然劣势:
- 人口稀疏:川西高原很多地方每平方公里不到 10 个人,灯光源本身就少
- 海拔高、空气稀薄:大气散射弱,灯光向上传播时衰减更快
- 气候寒冷:夜间活动少,灯光源更少
所以高原地区灯光暗,不是因为经济"差到那个程度",而是人口密度和生活方式决定了灯光源本来就少。卫星灯光对成都平原这种人口密集、商业活跃的地方很好使,但对川西高原就是个"半瞎子"——它能拍到灯光,但灯光亮度和经济活动之间的关系被稀疏的人口稀释了。
于是研究团队加了土地利用、海拔、降水、人口密度、POI、交通可达性等多源数据,再跑一次 GWR。R² 飙到 0.882。
模型 | R² |
|---|---|
仅夜间灯光 GWR | 0.66 |
多源数据 GWR | 0.88 |
全局 OLS | 0.80 |
一个有意思的空间格局浮现出来:GDP 高值集中在成都平原及相邻走廊,低值主导川西高原。各因素的空间差异很明显:
- 海拔和降水在川西高原是最强的抑制因素,但在成都平原几乎不影响 GDP。
- 交通可达性和人口密度在盆地核心区是增长引擎,在丘陵密集区反而因为拥堵变成了约束。
全局 OLS 给出一个「平均答案」:海拔越高 GDP 越低。但 GWR 说,在成都平原附近海拔几乎不影响 GDP,而在川西高原,海拔是决定性因素。
这个案例的教训是:用单一数据源估算经济活动,在地理条件单一的地方还行,在四川这种盆地+高原的地方会系统性失准。 不是模型不行,是数据维度不够。
4. 三个案例的共同点
回到开头的问题。
三个案例,三个完全不同的话题——公共卫生、城市通勤、经济估算——但撞上了同一面墙:全局模型假设整个研究区域内的关系是均匀的。 地形对结核病的影响全国一样,企业密度对通勤的影响全城一样,海拔对 GDP 的影响全省一样。
这个假设在中国几乎不成立。西部高原和东部沿海、南方湿热和北方干冷、一线城市和县域农村——同一个因素在不同地方的表现可以天差地别。
GWR 让每个地方有自己的系数,MGWR 更进一步——让不同变量在不同空间尺度上起作用。地铁站距离是局部因素(几公里),就业密度是全局因素(跨区级),用同一个带宽分析它们本来就不合理。
这不代表全局分析没用。OLS 给出的整体趋势仍有参考价值。但如果你要制定具体措施——在哪里建流动医疗队、怎么规划地铁线路、哪些县该优先投资——你需要知道因素在那个地方、那个尺度上的真实影响力,而不是一个被全国平均稀释过的数字。
上一篇:犯罪率高的地方房价更贵?七个数据反直觉的真相[4]——七个国外案例讲了同一件事。
ArcGIS Pro 教程笔记:全市一套公式估不准房价——GWR和随机森林怎么选[5]——跟着教程走一遍 GWR、MGWR、FBCR 的实操。
参考链接
[1] https://link.springer.com/article/10.1186/s12942-025-00435-5
[2] https://www.mdpi.com/2073-445X/15/5/705
[3] https://www.mdpi.com/2076-3417/16/8/3868
[4] /blog/arcpy-tutorial/spatial-regression-counterintuitive-findings/
[5] /blog/arcpy-tutorial/gwr-tutorial2-plain/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号