
sql delete重复了1列的行
提问于 2009-10-30 06:38:36
我有一个microsoft sql 2005 db表,其中整行没有重复,但有一列是重复的。
1个aaa
1 bbb
1个ccc
2个abc
2定义
如何删除第一列重复的行中除1之外的所有行?
为了澄清,我需要去掉第二行、第三行和第五行。

回答 6
Stack Overflow用户
回答已采纳
发布于 2009-10-30 07:00:21
在sql server 2005中尝试以下查询
WITH T AS (SELECT ROW_NUMBER()OVER(PARTITION BY id ORDER BY id) AS rnum,* FROM dbo.Table_1)
DELETE FROM T WHERE rnum>1Stack Overflow用户
发布于 2009-10-30 06:43:47
让我们称它们为id和Col1列。
DELETE myTable T1
WHERE EXISTS
(SELECT * FROM myTable T2
WHERE T2.id = T1.id AND T2.Col1 > T1.Col1) 编辑:正如Andomar所指出的,上面并没有消除完全重复的情况,即id和Col1在不同的行中是相同的。这些问题可以按如下方式处理:
(注:以上查询为generic SQL,以下内容适用于MSSQL2005及更高版本)
它使用 (CTE)特性以及ROW_NUMBER()函数来生成一个独特的行值。它本质上与上面的构造相同,除了它现在使用具有真正独特的标识符键的“表”(CTE主要类似于表)。
注意,通过删除"AND T2.Col1 = T1.Col1",我们产生了一个查询,它可以在单个查询中处理两种类型的副本(仅Id副本以及Id和Col1副本),即以与Hamadri的解决方案类似的方式(他/她的CTE中的分区与此解决方案中的子查询的目的相同,基本上完成了相同数量的工作)。根据情况,可能更可取的是,在性能方面或其他方面,分两个步骤处理这种情况。
WITH T AS
(SELECT ROW_NUMBER() OVER (ORDER BY id, Col1) AS rn, id, Col1 FROM MyTable)
DELETE T AS T1
WHERE EXISTS
(SELECT *
FROM T AS T2
WHERE T2.id = T1.id AND T2.Col1 = T1.Col1
AND T2.rn > T1.rn
) Stack Overflow用户
发布于 2009-10-30 06:44:16
DELETE tableName as ta
WHERE col2 NOT IN (SELECT MIN(col2) FROM tableName AS t2 GROUP BY col1)确保sub select返回要保留的行。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/1648337
复制相关文章




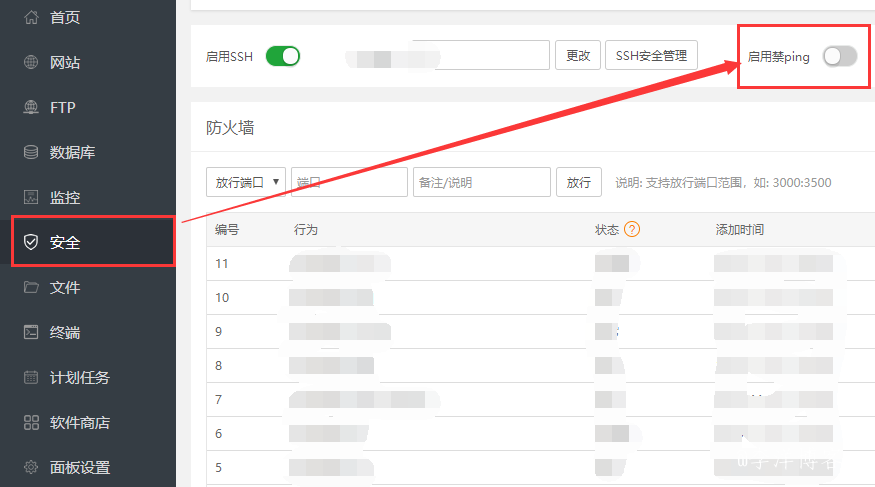
![CentOS7修改IP地址后无法ping通问题记录[通俗易懂]](https://ask.qcloudimg.com/http-save/yehe-8223537/749ff71e8a96bcd2aa3d78acb4cddf73.jpeg)


腾讯云开发者
