
不进行排序,直接按升序枚举数字的因子?
是否有一个有效的算法来枚举数n的因子,按升序排列,而不排序?我所说的“有效率”是指:
- 该算法从n的素幂因式分解开始,避免了对因子的蛮力搜索.
- 该算法的运行时复杂度为O(d log₂d)或更高,其中d是n的除数。
- 算法的空间复杂度为O(d)。
- 该算法避免了排序操作。也就是说,这些因素是按顺序产生的,而不是按顺序产生的,然后再排序。尽管使用简单的递归方法进行枚举,然后排序是O(d log₂d),但排序所涉及的所有内存访问都要付出很大的代价。
一个微不足道的例子是n= 360 = 2×3 2×3 d=24因子:{ 1、2、3、4、5、6、8、9、10、12、15、18、20、24、30、36、40、45、60、72、90、120、180、360 }。
更严重的例子是:n=2782825124061323733823382308832000= 2⁸×3⁴×5×7 2 2×11 2 2 2×13 2×17×19×2 3×2 9×31×31×41×4 7×4 3×5 7×6 7×71×73×79,它具有明显的⁸因子(在这里明显太多)。顺便说一句,这个数字的因素最多,最多可达2^128。
我可以发誓,几周前我看到了这种算法的描述和示例代码,但现在我似乎找不到它了。它使用了一些魔术,在输出列表中为每个素因子维护一个前代索引列表。(更新:我把要素生成与汉明数字混淆了,后者的操作方式类似。)
更新
最后,我使用了一个在运行时为O(d)的解决方案,它具有极低的内存开销,可以就地创建O(d)输出,并且比我所知道的任何其他方法都要快得多。我已经发布了这个解决方案作为答案,用C源代码。它是另一个贡献者威尔·奈斯在Haskell提出的一个漂亮算法的一个经过高度优化的简化版本。我选择了Will的答案作为接受的答案,因为它提供了一个非常优雅的解决方案,它与最初声明的所有需求相匹配。

回答 4
Stack Overflow用户
发布于 2015-05-01 18:01:54
我们可以合并倍数流,这样就没有重复了。
从list [1]开始,对于每个唯一的素因子p,我们用p迭代地乘以列表(其中k是p的多重性),以获得k新列表,并将它们与传入的列表合并。
在哈斯克尔
ordfactors n = -- <----------------------<---<---<-----\
foldr g [1] -- g (19,1) (g (7,1) (g (3,2) (g (2,3) [1])))
. reverse -- [(19,1),(7,1),(3,2),(2,3)] ^
. primePowers -- [(2,3),(3,2),(7,1),(19,1)] |
$ n -- 9576 --->--->--->----/
where
g (p,k) xs = mergeAsTree
. take (k+1) -- take 3 [a,b,c,d..] = [a,b,c]
. iterate (map (p*)) -- iterate f x = [x, y, z,...]
$ xs -- where { y=f x; z=f y; ... }
{- g (2,3) [1] = let a0 = [1]
a1 = map (2*) a0 -- [2]
a2 = map (2*) a1 -- [4]
a3 = map (2*) a2 -- [8]
in mergeAsTree [ a0, a1, a2, a3 ] -- xs2 = [1,2,4,8]
g (3,2) xs2 = let b0 = xs2 -- [1,2,4,8]
b1 = map (3*) b0 -- [3,6,12,24]
b2 = map (3*) b1 -- [9,18,36,72]
in mergeAsTree [ b0, b1, b2 ] -- xs3 = [1,2,3,4,6,8,9,12,...]
g (7,1) xs3 = mergeAsTree [ xs3, map (7*) xs3 ] -- xs4 = [1,2,3,4,6,7,8,9,...]
g (19,1) xs4 = mergeAsTree [ xs4, map (19*) xs4 ]
-}
mergeAsTree xs = foldi merge [] xs -- [a,b] --> merge a b
-- [a,b,c,d] --> merge (merge a b) (merge c d)
foldi f z [] = z
foldi f z (x:xs) = f x (foldi f z (pairs f xs))
pairs f (x:y:t) = f x y : pairs f t
pairs _ t = tfoldi安排二进制S (前提是在合并的流中没有重复项,以便进行流线化操作) 像树一样用于速度;而foldr则以线性方式工作。
primePowers n | n > 1 = -- 9576 => [(2,3),(3,2),(7,1),(19,1)]
map (\xs -> (head xs,length xs)) -- ^
. group -- [[2,2,2],[3,3],[7],[19]] |
. factorize -- [2,2,2,3,3,7,19] |
$ n -- 9576 --->--->--->---/group是一个标准函数,它在列表中将相邻的等号组合在一起,而factorize是一种众所周知的试用除法算法,它以不递减的顺序生成一个数字的素因子:
factorize n | n > 1 = go n (2:[3,5..]) -- 9576 = 2*2*2*3*3*7*19
where -- produce prime factors only
go n (d:t)
| d*d > n = [n]
| r == 0 = d : go q (d:t)
| otherwise = go n t
where
(q,r) = quotRem n d
factorize _ = [](.)是一个函数式复合运算符,将其右侧的参数函数的输出链接为其左侧的输入。它(和$)可以被朗读为"of“。
Stack Overflow用户
发布于 2015-05-11 19:39:27
这个答案给出了一个C实现,我认为它是最快、最节省内存的。
算法概述。--该算法基于Will Ness在另一个答案中引入的自下而上的合并方法,但进一步简化了以使正在合并的列表在内存中的任何位置都不存在。每个列表的head元素被修饰并保存在一个小数组中,而列表中的所有其他元素都是根据需要动态构建的。这种使用“幻影列表”的-figments来想象运行中的代码--大大减少了内存占用,以及内存的读写量,还改善了空间局部性,从而大大提高了算法的速度。每个级别的因素都被直接写入输出数组中的最后休息位置。
其基本思想是利用数学归纳法对素数幂因式分解生成因子.例如:
- 若要产生360的因数,则计算72的因数,然后乘以相关的5的幂,在这种情况下是{1,5}。
- 若要产生72的因数,则计算8的因数,然后乘以相关的3的幂,在这种情况下是{1, 3,9}。
- 若要产生8的因数,则基情况1乘以相关的2的幂,在这种情况下是{1, 2,4,8}。
因此,在每个归纳步骤中,在现有的因子集和素数集之间计算一个笛卡儿积,并通过乘法将结果降回整数。
下面是数字360的一个例子。从左到右显示的是内存单元格;一行表示一个时间步骤。时间被表示为垂直向下流动。
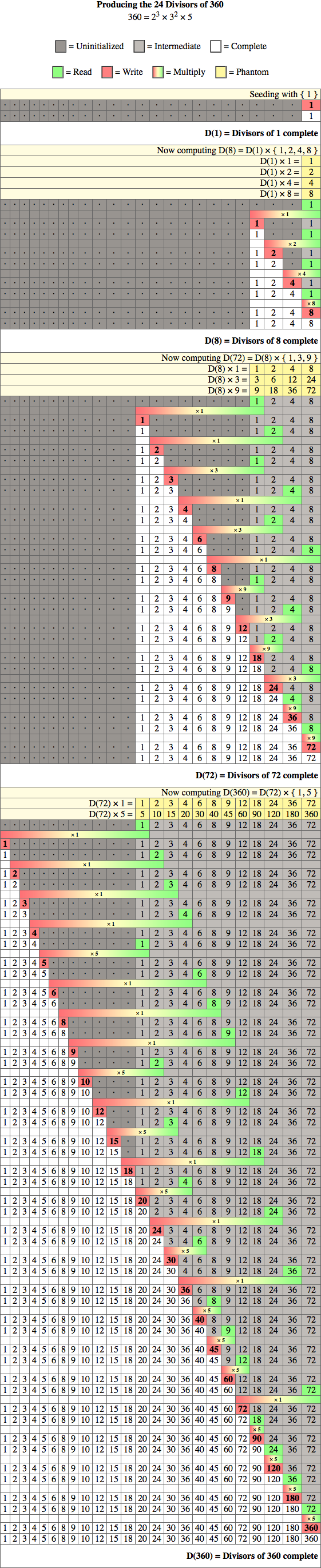
空间复杂度。临时数据结构产生的因子非常小:只使用O(log₂(n))空间,其中n是生成因子的个数。例如,在C中此算法的128位实现中,333,939,014,887,358,848,058,068,063,658,770,598,400 (其基-2对数为≈127.97)这样的数字分配5.1GB来存储其318、504、960个因素的列表,但只需增加360个字节的额外开销即可生成该列表。对于任何128位数,最多都需要大约5 KB的开销.
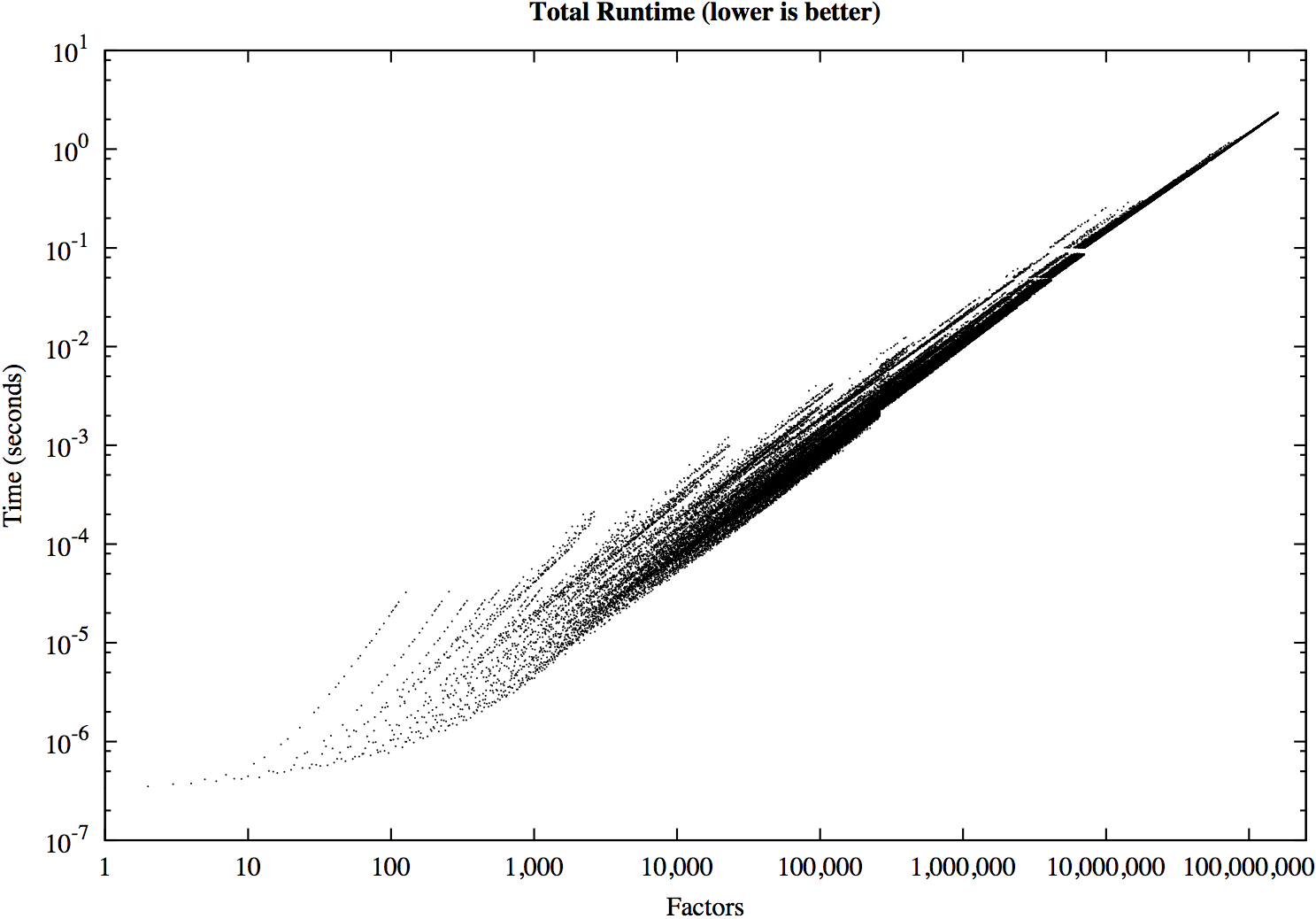
运行时复杂性。运行时完全依赖于素幂因式分解的指数(例如,素数签名)。为了获得最好的结果,最大指数应该先处理,最小指数应该最后处理,这样运行时在最后阶段被低复杂度的合并所主导,而在实践中往往是二进制合并。渐近运行时为O(c( n ) d(n)),其中d(n)是n的除数,c(n)是依赖于n的素签名的常数,即每个与素数签名相关的等价类都有不同的常数。由小指数主导的素数签名具有较小的常数;由大指数主导的素数签名具有较大的常数。因此,运行时复杂性是由素数签名组成的。
图。运行时性能在3.4GHz上进行了描述。因特尔核心i7采样的n值为66,591,具有d(n)因子的唯一d(n)高达1.6亿。图中n的最大值是14,550,525,518,294,259,162,294,162,737,840,640,000,,在2.35秒内产生159,744,000个因子。
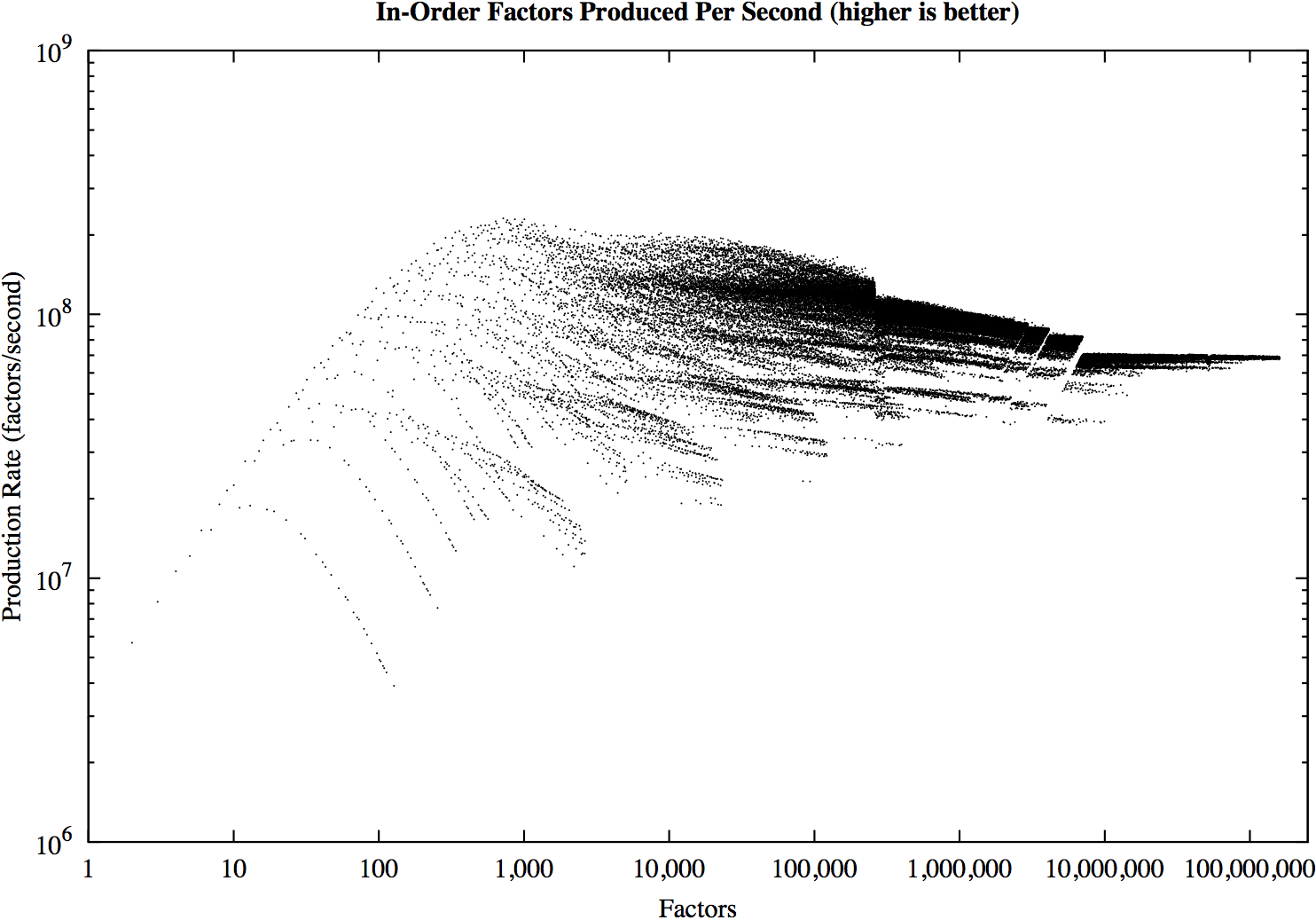
每秒产生的排序因子的数量实质上是上述的反演。在数据中,按素数签名进行聚类是显而易见的。性能还受到L1、L2和L3缓存大小以及物理RAM限制的影响。
源代码。下面所附的是C编程语言(特别是C11)中的一个工作程序。它已经在x86-64上使用Clang/LLVM进行了测试,尽管它也应该与GCC一起很好地工作。
/*==============================================================================
DESCRIPTION
This is a small proof-of-concept program to test the idea of generating the
factors of a number in ascending order using an ultra-efficient sortless
method.
INPUT
Input is given on the command line, either as a single argument giving the
number to be factored or an even number of arguments giving the 2-tuples that
comprise the prime-power factorization of the desired number. For example,
the number
75600 = 2^4 x 3^3 x 5^2 x 7
can be given by the following list of arguments:
2 4 3 3 5 2 7 1
Note: If a single number is given, it will require factoring to produce its
prime-power factorization. Since this is just a small test program, a very
crude factoring method is used that is extremely fast for small prime factors
but extremely slow for large prime factors. This is actually fine, because
the largest factor lists occur with small prime factors anyway, and it is the
production of large factor lists at which this program aims to be proficient.
It is simply not interesting to be fast at producing the factor list of a
number like 17293823921105882610 = 2 x 3 x 5 x 576460797370196087, because
it has only 32 factors. Numbers with tens or hundreds of thousands of
factors are much more interesting.
OUTPUT
Results are written to standard output. A list of factors in ascending order
is produced, followed by runtime required to generate the list (not including
time to print it).
AUTHOR
Todd Lehman
2015/05/10
*/
//-----------------------------------------------------------------------------
#include <inttypes.h>
#include <limits.h>
#include <stdbool.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdarg.h>
#include <string.h>
#include <ctype.h>
#include <time.h>
#include <math.h>
#include <assert.h>
//-----------------------------------------------------------------------------
typedef unsigned int uint;
typedef uint8_t uint8;
typedef uint16_t uint16;
typedef uint32_t uint32;
typedef uint64_t uint64;
typedef __uint128_t uint128;
#define UINT128_MAX (uint128)(-1)
#define UINT128_MAX_STRLEN 39
//-----------------------------------------------------------------------------
#define ARRAY_CAPACITY(x) (sizeof(x) / sizeof((x)[0]))
//-----------------------------------------------------------------------------
// This structure encode a single prime-power pair for the prime-power
// factorization of numbers, for example 3 to the 4th power.
#pragma pack(push, 8)
typedef struct
{
uint128 p; // Prime.
uint8 e; // Power (exponent).
}
PrimePower; // 24 bytes using 8-byte packing
#pragma pack(pop)
//-----------------------------------------------------------------------------
// Prime-power factorization structure.
//
// This structure is sufficient to represent the prime-power factorization of
// all 128-bit values. The field names ω and Ω are dervied from the standard
// number theory functions ω(n) and Ω(n), which count the number of unique and
// non-unique prime factors of n, respectively. The field name d is derived
// from the standard number theory function d(n), which counts the number of
// divisors of n, including 1 and n.
//
// The maximum possible value here of ω is 26, which occurs at
// n = 232862364358497360900063316880507363070 = 2 x 3 x 5 x 7 x 11 x 13 x 17 x
// 19 x 23 x 29 x 31 x 37 x 41 x 43 x 47 x 53 x 59 x 61 x 67 x 71 x 73 x 79 x
// 83 x 89 x 97 x 101, which has 26 unique prime factors.
//
// The maximum possible value of Ω here is 127, which occurs at n = 2^127 and
// n = 2^126 x 3, both of which have 127 non-unique prime factors.
//
// The maximum possible value of d here is 318504960, which occurs at
// n = 333939014887358848058068063658770598400 = 2^9 x 3^5 x 5^2 x 7^2 x 11^2 x
// 13^2 x 17 x 19 x 23 x 29 x 31 x 37 x 41 x 43 x 47 x 53 x 59 x 61 x 67 x 71 x
// 73 x 79.
//
#pragma pack(push, 8)
typedef struct
{
PrimePower f[32]; // Primes and their exponents.
uint8 ω; // Count of prime factors without multiplicity.
uint8 Ω; // Count of prime factors with multiplicity.
uint32 d; // Count of factors of n, including 1 and n.
uint128 n; // Value of n on which all other fields depend.
}
PrimePowerFactorization; // 656 bytes using 8-byte packing
#pragma pack(pop)
#define MAX_ω 26
#define MAX_Ω 127
//-----------------------------------------------------------------------------
// Fatal error: print error message and abort.
void fatal_error(const char *format, ...)
{
va_list args;
va_start(args, format);
vfprintf(stderr, format, args);
exit(1);
}
//------------------------------------------------------------------------------
uint128 uint128_from_string(const char *const str)
{
assert(str != NULL);
uint128 n = 0;
for (int i = 0; isdigit(str[i]); i++)
n = (n * 10) + (uint)(str[i] - '0');
return n;
}
//------------------------------------------------------------------------------
void uint128_to_string(const uint128 n,
char *const strbuf, const uint strbuflen)
{
assert(strbuf != NULL);
assert(strbuflen >= UINT128_MAX_STRLEN + 1);
// Extract digits into string buffer in reverse order.
uint128 a = n;
char *s = strbuf;
do { *(s++) = '0' + (uint)(a % 10); a /= 10; } while (a != 0);
*s = '\0';
// Reverse the order of the digits.
uint l = strlen(strbuf);
for (uint i = 0; i < l/2; i++)
{ char t = strbuf[i]; strbuf[i] = strbuf[l-1-i]; strbuf[l-1-i] = t; }
// Verify result.
assert(uint128_from_string(strbuf) == n);
}
//------------------------------------------------------------------------------
char *uint128_to_static_string(const uint128 n, const uint i)
{
static char str[2][UINT128_MAX_STRLEN + 1];
assert(i < ARRAY_CAPACITY(str));
uint128_to_string(n, str[i], ARRAY_CAPACITY(str[i]));
return str[i];
}
//------------------------------------------------------------------------------
// Compute sorted list of factors, given a prime-power factorization.
uint128 *compute_factors(const PrimePowerFactorization ppf)
{
const uint128 n = ppf.n;
const uint d = (uint)ppf.d;
const uint ω = (uint)ppf.ω;
if (n == 0)
return NULL;
uint128 *factors = malloc((d + 1) * sizeof(*factors));
if (!factors)
fatal_error("Failed to allocate array of %u factors.", d);
uint128 *const factors_end = &factors[d];
// --- Seed the factors[] array.
factors_end[0] = 0; // Dummy value to simplify looping in bottleneck code.
factors_end[-1] = 1; // Seed value.
if (n == 1)
return factors;
// --- Iterate over all prime factors.
uint range = 1;
for (uint i = 0; i < ω; i++)
{
const uint128 p = ppf.f[i].p;
const uint e = ppf.f[i].e;
// --- Initialize phantom input lists and output list.
assert(e < 128);
assert(range < d);
uint128 *restrict in[128];
uint128 pe[128], f[128];
for (uint j = 0; j <= e; j++)
{
in[j] = &factors[d - range];
pe[j] = (j == 0)? 1 : pe[j-1] * p;
f[j] = pe[j];
}
uint active_list_count = 1 + e;
range *= 1 + e;
uint128 *restrict out = &factors[d - range];
// --- Merge phantom input lists to output list, until all input lists are
// extinguished.
while (active_list_count > 0)
{
if (active_list_count == 1)
{
assert(out == in[0]);
while (out != factors_end)
*(out++) *= pe[0];
in[0] = out;
}
else if (active_list_count == 2)
{
// This section of the code is the bottleneck of the entire factor-
// producing algorithm. Other portions need to be fast, but this
// *really* needs to be fast; therefore, it has been highly optimized.
// In fact, it is by far most frequently the case here that pe[0] is 1,
// so further optimization is warranted in this case.
uint128 f0 = f[0], f1 = f[1];
uint128 *in0 = in[0], *in1 = in[1];
const uint128 pe0 = pe[0], pe1 = pe[1];
if (pe[0] == 1)
{
while (true)
{
if (f0 < f1)
{ *(out++) = f0; f0 = *(++in0);
if (in0 == factors_end) break; }
else
{ *(out++) = f1; f1 = *(++in1) * pe1; }
}
}
else
{
while (true)
{
if (f0 < f1)
{ *(out++) = f0; f0 = *(++in0) * pe0;
if (in0 == factors_end) break; }
else
{ *(out++) = f1; f1 = *(++in1) * pe1; }
}
}
f[0] = f0; f[1] = f1;
in[0] = in0; in[1] = in1;
}
else if (active_list_count == 3)
{
uint128 f0 = f[0], f1 = f[1], f2 = f[2];
uint128 *in0 = in[0], *in1 = in[1], *in2 = in[2];
const uint128 pe0 = pe[0], pe1 = pe[1], pe2 = pe[2];
while (true)
{
if (f0 < f1)
{
if (f0 < f2)
{ *(out++) = f0; f0 = *(++in0) * pe0;
if (in0 == factors_end) break; }
else
{ *(out++) = f2; f2 = *(++in2) * pe2; }
}
else
{
if (f1 < f2)
{ *(out++) = f1; f1 = *(++in1) * pe1; }
else
{ *(out++) = f2; f2 = *(++in2) * pe2; }
}
}
f[0] = f0; f[1] = f1, f[2] = f2;
in[0] = in0; in[1] = in1, in[2] = in2;
}
else if (active_list_count >= 3)
{
while (true)
{
// Chose the smallest multiplier.
uint k_min = 0;
uint128 f_min = f[0];
for (uint k = 0; k < active_list_count; k++)
if (f[k] < f_min)
{ f_min = f[k]; k_min = k; }
// Write the output factor, advance the input pointer, and
// produce a new factor in the array f[] of list heads.
*(out++) = f_min;
f[k_min] = *(++in[k_min]) * pe[k_min];
if (in[k_min] == factors_end)
{ assert(k_min == 0); break; }
}
}
// --- Remove the newly emptied phantom input list. Note that this is
// guaranteed *always* to be the first remaining non-empty list.
assert(in[0] == factors_end);
for (uint j = 1; j < active_list_count; j++)
{
in[j-1] = in[j];
pe[j-1] = pe[j];
f[j-1] = f[j];
}
active_list_count -= 1;
}
assert(out == factors_end);
}
// --- Validate array of sorted factors.
#ifndef NDEBUG
{
for (uint k = 0; k < d; k++)
{
if (factors[k] == 0)
fatal_error("Produced a factor of 0 at index %u.", k);
if (n % factors[k] != 0)
fatal_error("Produced non-factor %s at index %u.",
uint128_to_static_string(factors[k], 0), k);
if ((k > 0) && (factors[k-1] == factors[k]))
fatal_error("Duplicate factor %s at index %u.",
uint128_to_static_string(factors[k], 0), k);
if ((k > 0) && (factors[k-1] > factors[k]))
fatal_error("Out-of-order factors %s and %s at indexes %u and %u.",
uint128_to_static_string(factors[k-1], 0),
uint128_to_static_string(factors[k], 1),
k-1, k);
}
}
#endif
return factors;
}
//------------------------------------------------------------------------------
// Print prime-power factorization of a number.
void print_ppf(const PrimePowerFactorization ppf)
{
printf("%s = ", uint128_to_static_string(ppf.n, 0));
if (ppf.n == 0)
{
printf("0");
}
else
{
for (uint i = 0; i < ppf.ω; i++)
{
if (i > 0)
printf(" x ");
printf("%s", uint128_to_static_string(ppf.f[i].p, 0));
if (ppf.f[i].e > 1)
printf("^%"PRIu8"", ppf.f[i].e);
}
}
printf("\n");
}
//------------------------------------------------------------------------------
int compare_powers_ascending(const void *const pf1,
const void *const pf2)
{
const PrimePower f1 = *((const PrimePower *)pf1);
const PrimePower f2 = *((const PrimePower *)pf2);
return (f1.e < f2.e)? -1:
(f1.e > f2.e)? +1:
0; // Not an error; duplicate exponents are common.
}
//------------------------------------------------------------------------------
int compare_powers_descending(const void *const pf1,
const void *const pf2)
{
const PrimePower f1 = *((const PrimePower *)pf1);
const PrimePower f2 = *((const PrimePower *)pf2);
return (f1.e < f2.e)? +1:
(f1.e > f2.e)? -1:
0; // Not an error; duplicate exponents are common.
}
//------------------------------------------------------------------------------
int compare_primes_ascending(const void *const pf1,
const void *const pf2)
{
const PrimePower f1 = *((const PrimePower *)pf1);
const PrimePower f2 = *((const PrimePower *)pf2);
return (f1.p < f2.p)? -1:
(f1.p > f2.p)? +1:
0; // Error; duplicate primes must never occur.
}
//------------------------------------------------------------------------------
int compare_primes_descending(const void *const pf1,
const void *const pf2)
{
const PrimePower f1 = *((const PrimePower *)pf1);
const PrimePower f2 = *((const PrimePower *)pf2);
return (f1.p < f2.p)? +1:
(f1.p > f2.p)? -1:
0; // Error; duplicate primes must never occur.
}
//------------------------------------------------------------------------------
// Sort prime-power factorization.
void sort_ppf(PrimePowerFactorization *const ppf,
const bool primes_major, // Best false
const bool primes_ascending, // Best false
const bool powers_ascending) // Best false
{
int (*compare_primes)(const void *, const void *) =
primes_ascending? compare_primes_ascending : compare_primes_descending;
int (*compare_powers)(const void *, const void *) =
powers_ascending? compare_powers_ascending : compare_powers_descending;
if (primes_major)
{
mergesort(ppf->f, ppf->ω, sizeof(ppf->f[0]), compare_powers);
mergesort(ppf->f, ppf->ω, sizeof(ppf->f[0]), compare_primes);
}
else
{
mergesort(ppf->f, ppf->ω, sizeof(ppf->f[0]), compare_primes);
mergesort(ppf->f, ppf->ω, sizeof(ppf->f[0]), compare_powers);
}
}
//------------------------------------------------------------------------------
// Compute prime-power factorization of a 128-bit value. Note that this
// function is designed to be fast *only* for numbers with very simple
// factorizations, e.g., those that produce large factor lists. Do not attempt
// to factor large semiprimes with this function. (The author does know how to
// factor large numbers efficiently; however, efficient factorization is beyond
// the scope of this small test program.)
PrimePowerFactorization compute_ppf(const uint128 n)
{
PrimePowerFactorization ppf;
if (n == 0)
{
ppf = (PrimePowerFactorization){ .ω = 0, .Ω = 0, .d = 0, .n = 0 };
}
else if (n == 1)
{
ppf = (PrimePowerFactorization){ .f[0] = { .p = 1, .e = 1 },
.ω = 1, .Ω = 1, .d = 1, .n = 1 };
}
else
{
ppf = (PrimePowerFactorization){ .ω = 0, .Ω = 0, .d = 1, .n = n };
uint128 m = n;
for (uint128 p = 2; p * p <= m; p += 1 + (p > 2))
{
if (m % p == 0)
{
assert(ppf.ω <= MAX_ω);
ppf.f[ppf.ω].p = p;
ppf.f[ppf.ω].e = 0;
while (m % p == 0)
{ m /= p; ppf.f[ppf.ω].e += 1; }
ppf.d *= (1 + ppf.f[ppf.ω].e);
ppf.Ω += ppf.f[ppf.ω].e;
ppf.ω += 1;
}
}
if (m > 1)
{
assert(ppf.ω <= MAX_ω);
ppf.f[ppf.ω].p = m;
ppf.f[ppf.ω].e = 1;
ppf.d *= 2;
ppf.Ω += 1;
ppf.ω += 1;
}
}
return ppf;
}
//------------------------------------------------------------------------------
// Parse prime-power factorization from a list of ASCII-encoded base-10 strings.
// The values are assumed to be 2-tuples (p,e) of prime p and exponent e.
// Primes must not exceed 2^128 - 1 and must not be repeated. Exponents must
// not exceed 2^8 - 1, but can of course be repeated. The constructed value
// must not exceed 2^128 - 1.
PrimePowerFactorization parse_ppf(const uint pairs, const char *const values[])
{
assert(pairs <= MAX_ω);
PrimePowerFactorization ppf;
if (pairs == 0)
{
ppf = (PrimePowerFactorization){ .ω = 0, .Ω = 0, .d = 0, .n = 0 };
}
else
{
ppf = (PrimePowerFactorization){ .ω = 0, .Ω = 0, .d = 1, .n = 1 };
for (uint i = 0; i < pairs; i++)
{
ppf.f[i].p = uint128_from_string(values[(i*2)+0]);
ppf.f[i].e = (uint8)strtoumax(values[(i*2)+1], NULL, 10);
// Validate prime value.
if (ppf.f[i].p < 2) // (Ideally this would actually do a primality test.)
fatal_error("Factor %s is invalid.",
uint128_to_static_string(ppf.f[i].p, 0));
// Accumulate count of unique prime factors.
if (ppf.ω > UINT8_MAX - 1)
fatal_error("Small-omega overflow at factor %s^%"PRIu8".",
uint128_to_static_string(ppf.f[i].p, 0), ppf.f[i].e);
ppf.ω += 1;
// Accumulate count of total prime factors.
if (ppf.Ω > UINT8_MAX - ppf.f[i].e)
fatal_error("Big-omega wverflow at factor %s^%"PRIu8".",
uint128_to_static_string(ppf.f[i].p, 0), ppf.f[i].e);
ppf.Ω += ppf.f[i].e;
// Accumulate total divisor count.
if (ppf.d > UINT32_MAX / (1 + ppf.f[i].e))
fatal_error("Divisor count overflow at factor %s^%"PRIu8".",
uint128_to_static_string(ppf.f[i].p, 0), ppf.f[i].e);
ppf.d *= (1 + ppf.f[i].e);
// Accumulate value.
for (uint8 k = 1; k <= ppf.f[i].e; k++)
{
if (ppf.n > UINT128_MAX / ppf.f[i].p)
fatal_error("Value overflow at factor %s.",
uint128_to_static_string(ppf.f[i].p, 0));
ppf.n *= ppf.f[i].p;
}
}
}
return ppf;
}
//------------------------------------------------------------------------------
// Main control. Parse command line and produce list of factors.
int main(const int argc, const char *const argv[])
{
bool primes_major = false;
bool primes_ascending = false;
bool powers_ascending = false;
PrimePowerFactorization ppf;
// --- Parse prime-power sort specifier (if present).
uint value_base = 1;
uint value_count = (uint)argc - 1;
if ((argc > 1) && (argv[1][0] == '-'))
{
static const struct
{
char *str; bool primes_major, primes_ascending, powers_ascending;
}
sort_options[] =
{
// Sorting criteria:
// ----------------------------------------
{ "ep", 0,0,0 }, // Exponents descending, primes descending
{ "Ep", 0,0,1 }, // Exponents ascending, primes descending
{ "eP", 0,1,0 }, // Exponents descending, primes ascending
{ "EP", 0,1,1 }, // Exponents ascending, primes ascending
{ "p", 1,0,0 }, // Primes descending (exponents irrelevant)
{ "P", 1,1,0 }, // Primes ascending (exponents irrelevant)
};
bool valid = false;
for (uint i = 0; i < ARRAY_CAPACITY(sort_options); i++)
{
if (strcmp(&argv[1][1], sort_options[i].str) == 0)
{
primes_major = sort_options[i].primes_major;
primes_ascending = sort_options[i].primes_ascending;
powers_ascending = sort_options[i].powers_ascending;
valid = true;
break;
}
}
if (!valid)
fatal_error("Bad sort specifier: \"%s\"", argv[1]);
value_base += 1;
value_count -= 1;
}
// --- Prime factorization from either a number or a raw prime factorization.
if (value_count == 1)
{
uint128 n = uint128_from_string(argv[value_base]);
ppf = compute_ppf(n);
}
else
{
if (value_count % 2 != 0)
fatal_error("Odd number of arguments (%u) given.", value_count);
uint pairs = value_count / 2;
ppf = parse_ppf(pairs, &argv[value_base]);
}
// --- Sort prime factorization by either the default or the user-overridden
// configuration.
sort_ppf(&ppf, primes_major, primes_ascending, powers_ascending);
print_ppf(ppf);
// --- Run for (as close as possible to) a fixed amount of time, tallying the
// elapsed CPU time.
uint128 iterations = 0;
double cpu_time = 0.0;
const double cpu_time_limit = 0.10;
uint128 memory_usage = 0;
while (cpu_time < cpu_time_limit)
{
clock_t clock_start = clock();
uint128 *factors = compute_factors(ppf);
clock_t clock_end = clock();
cpu_time += (double)(clock_end - clock_start) / (double)CLOCKS_PER_SEC;
memory_usage = sizeof(*factors) * ppf.d;
if (++iterations == 0) //1)
{
for (uint32 i = 0; i < ppf.d; i++)
printf("%s\n", uint128_to_static_string(factors[i], 0));
}
if (factors) free(factors);
}
// --- Print the average amount of CPU time required for each iteration.
uint memory_scale = (memory_usage >= 1e9)? 9:
(memory_usage >= 1e6)? 6:
(memory_usage >= 1e3)? 3:
0;
char *memory_units = (memory_scale == 9)? "GB":
(memory_scale == 6)? "MB":
(memory_scale == 3)? "KB":
"B";
printf("%s %"PRIu32" factors %.6f ms %.3f ns/factor %.3f %s\n",
uint128_to_static_string(ppf.n, 0),
ppf.d,
cpu_time/iterations * 1e3,
cpu_time/iterations * 1e9 / (double)(ppf.d? ppf.d : 1),
(double)memory_usage / pow(10, memory_scale),
memory_units);
return 0;
}Stack Overflow用户
发布于 2015-05-01 16:50:16
简而言之:重复地从堆中提取下一个最小的因子,然后将该因子的每一个倍数推回仍然是n的因子。使用一个技巧来避免重复出现,这样堆的大小就不会超过d。时间复杂度是O(kd log d),其中k是不同的素因子的数目。
我们利用的关键性质是,如果x和y都是n的因子,且y= x*p对于某个因子p >= 2 --也就是说,如果x的素因子是y的素因子的一个适当的子集合,那么x
第一次尝试:复制慢的东西
首先描述一个生成正确答案的算法,但也会产生许多重复的答案,这将是很有帮助的:
- 设置prev = NULL。
- 将1插入堆H中。
- 从H中提取堆t的顶部,如果堆为空,请停止。
- 如果t == prev,则转到3. 编辑:固定
- 输出t.
- 设置prev = t.
- 对于n:的每个不同素数因子p
- 如果n% ( t*p ) == 0(即t*p仍然是n的一个因子),则将t*p推到H上。
- 去3号。
上述算法唯一的问题是可以多次生成相同的因子。例如,如果n= 30,则因子15将被生成为因子5的子因子(通过乘以素数因子3)和因子3的子因子(乘以5)。一种方法是注意到,当副本到达堆的顶部时,必须在连续块中读出,因此您可以简单地检查堆的顶部是否等于公正提取的值,如果是这样,则继续提取和丢弃它。但更好的办法是可能的:
在源头杀死副本
一个因子x可以产生多少种方式?首先考虑x不包含多重性> 1的素因子的情况。在这种情况下,如果它包含m个不同的素因子,那么在以前的算法中,会有m-1“父”因子作为“子”生成它--这些父母中的每一个都由m个素因子的某个子集组成,其余的素因子是被添加到子算法中的一个。(如果x有一个重数大于1的素因子,那么实际上就有m个父母。)如果我们有一种方法来决定这些父母中的一位是“被选中的父母”,而这条规则产生了一个测试,可以在父母被弹出时应用于每个父母,那么我们就可以避免在一开始就创建任何重复。
我们可以使用以下规则:对于任意给定的x,选择缺少x的m个最大因子的潜在父元素y。这就形成了一条简单的规则:父y产生子x的当且仅当x= y*p的某个p大于或等于y中的任何素数。这很容易测试:按递减顺序遍历素因子,为每个因子生成子元素,直到我们碰到一个已经除以y的素因子。在前面的例子中,父3将产生15,但父5不会产生15 (因为3< 5) --因此15实际上只生成一次。对于n= 30,完整的树看起来如下:
1
/|\
2 3 5
/| \
6 10 15
|
30
请注意,每个因素都准确地生成一次。
新的无重复算法如下:
- 将1插入堆H中。
- 从H中提取堆t的顶部,如果堆为空,请停止。
- 输出t.
- 对于n的每个不同素数因子p的递减顺序:
- 如果n% ( t*p ) == 0(即t*p仍然是n的一个因子),则将t*p推到H上。
- 如果t%p == 0(即t已经包含p作为因子),则停止。
- 去2号。
https://stackoverflow.com/questions/29992904
复制














腾讯云开发者
