
iText PdfSmartCopy正在创建重复字体
提问于 2018-11-05 09:21:17
我使用iText (5.5.12) PdfSmartCopy将两个文件合并在一起,这些文件具有嵌入、未设置的字体(并且碰巧是在同一台机器上生成的,因此我知道它们指的是相同的字体),希望最终结果只有一个字体副本。
但是,我发现合并后的结果中嵌入了两次字体。
下面是我使用的代码:
String[] srcs = ...
Document document = new Document();
PdfCopy copy = new PdfSmartCopy(document, new FileOutputStream(result));
document.open();
for (int i = 0; i < srcs.length; i++) {
PdfReader reader = new PdfReader(srcs[i]);
copy.addDocument(reader);
copy.freeReader(reader);
reader.close();
}
document.close();这是相关文件上的pdffonts输出:
输入文件1:
name type encoding emb sub uni object ID
------------------------------------ ----------------- ---------------- --- --- --- ---------
TimesNewRomanPSMT CID TrueType Identity-H yes no yes 14 0输入文件2:
name type encoding emb sub uni object ID
------------------------------------ ----------------- ---------------- --- --- --- ---------
TimesNewRomanPSMT CID TrueType Identity-H yes no yes 11 0输出文件:
name type encoding emb sub uni object ID
------------------------------------ ----------------- ---------------- --- --- --- ---------
TimesNewRomanPSMT CID TrueType Identity-H yes no yes 3 0
TimesNewRomanPSMT CID TrueType Identity-H yes no yes 25 0
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-11-07 07:36:15
与你的假设相反
两个具有嵌入、未设置的字体的文件
字体是子设置的,不同的是。
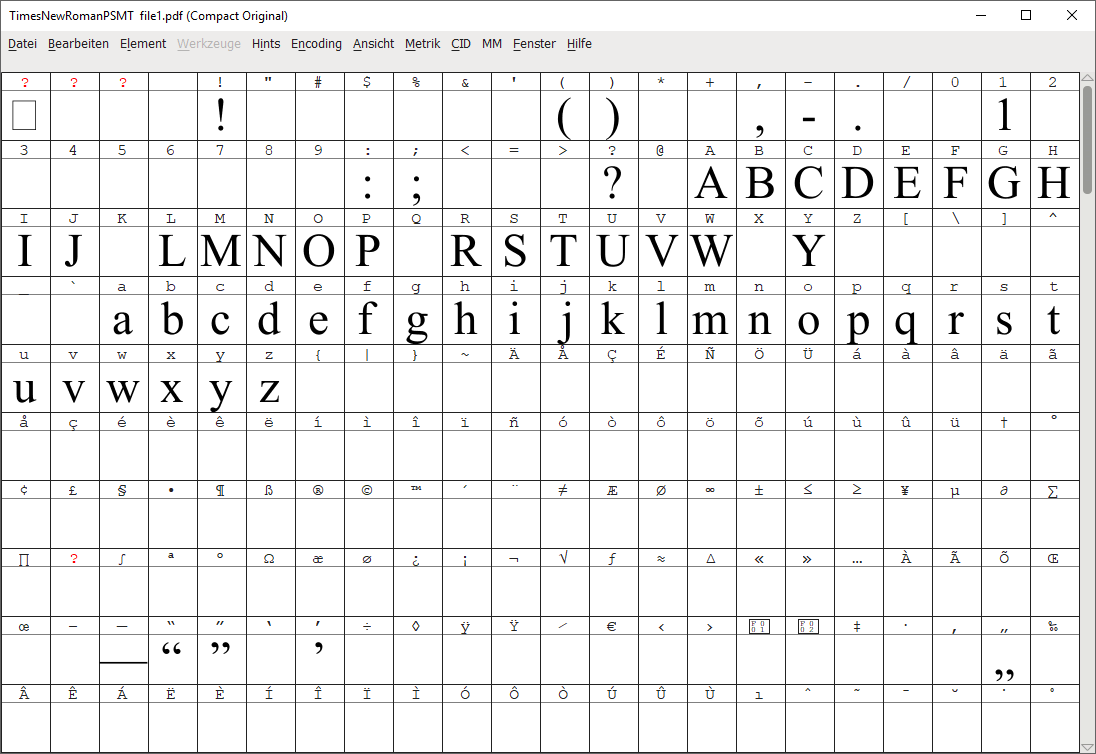
来自file1.pdf:
来自file2.pdf:
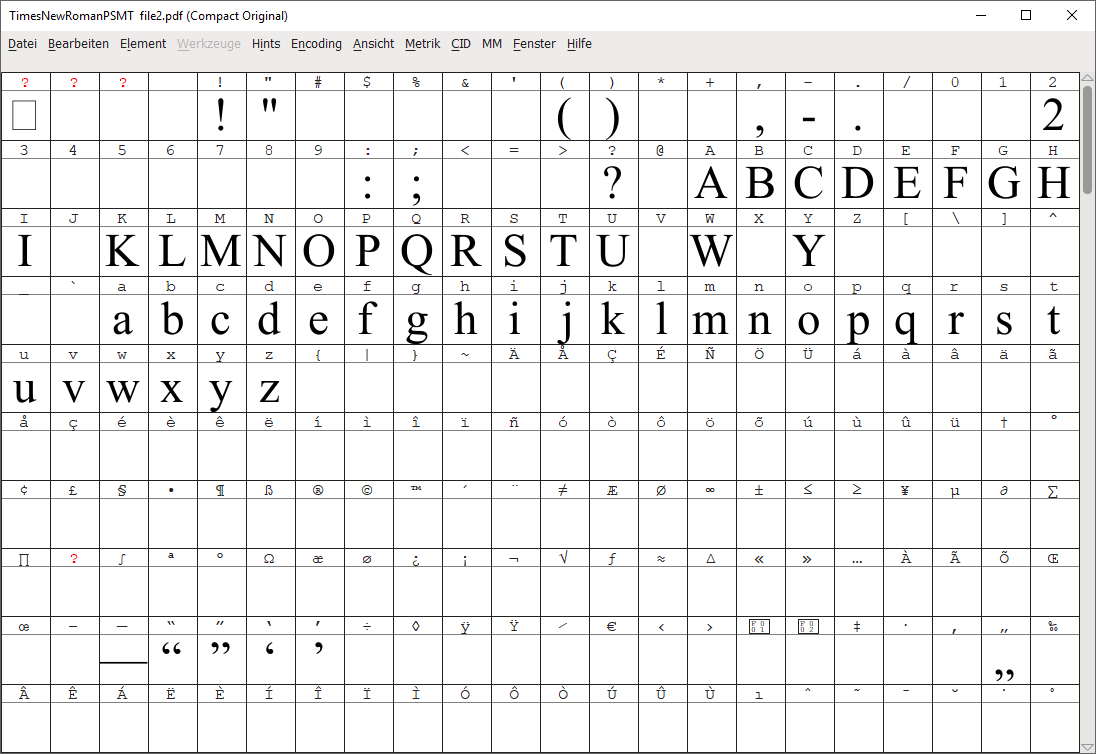
如您所见,在文件1中有一个非空的字形,而在文件2中没有,反之亦然。
因此,这些字体是不相同的,而且PdfSmartCopy没有正确地替换另一个字体。
我假设pdffonts没有将它们识别为子集,因为它们没有被正确标记为子集字体,特别是它们的名称没有必要的子集标记,并且它们没有在字体子集中定义的字符名的可选CharSet列表。因此,字体不仅没有被设置,而且设置也是错误的。
因此,不要将错误的假设归咎于pdffonts,而应归咎于创建输入文件的PDF生成器。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53159196
复制相关文章






点击加载更多


腾讯云开发者
