
在长字符串中查找给定单词之前的\n号
提问于 2019-01-21 07:07:34
我有根很长的绳子:
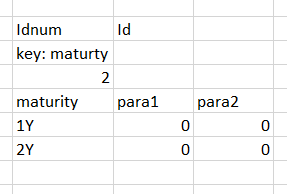
string = 'Idnum\rId\nkey: maturity\n2\nmaturity\rpara1\rpara2\n1Y\r0\r0\n2Y\r0\r0'现在,我想知道单词\n (在字符串中是唯一的,我们可以看到答案是2)之前的\nmaturity数。
这是这个问题的动机,如果你不能理解我下面说的话,就忽略它,专注于上面的问题。
我想使用pandas阅读data (我不确定data的结构,可能是csv):
并使用以下语法:
value = pandas.read_csv(data, sep = '\t', skiprows = 3).set_index('maturity') 在3之前跳过第一个maturity行以获得表,如下所示:

因此,我需要找出maturity的行号,以确定应该跳过的行数。但我只知道data
data.getvalue() = 'Idnum\rId\nkey: maturity\n2\nmaturity\rpara1\rpara2\n1Y\r0\r0\n2Y\r0\r0'(\n正在改变线路,\r正在改变单元格)。因此,我必须在\n之前天真地找到maturity的数量,以确定原始表(或data)中maturity的行号。
因此,如果您熟悉上述结构,请告诉我如何在maturity中找到data的行号。

回答 1
Stack Overflow用户
回答已采纳
发布于 2019-01-21 07:11:12
一种方法是:
- 首先,使用‘\n成熟度’分隔符作为
split字符串,并接受第一个字符串(因此,第一个找到项的左边)。 - 而不是使用
count来计算“\n‘s”的数量。
未经测试:
string = 'Idnum\rId\nkey: maturity\n2\nmaturity\rpara1\rpara2\n1Y\r0\r0\n2Y\r0\r0'
stringUntilMaturity = string.split('\nmaturity')[0]
counts = stringUntilMaturity.count('\n')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54292729
复制相关文章




点击加载更多


腾讯云开发者
