J. Chem. Inf. Model. | 能否快速学习使用Transformer模型“翻译”生物活性分子?

J. Chem. Inf. Model. | 能否快速学习使用Transformer模型“翻译”生物活性分子?

DrugOne
发布于 2023-09-19 14:37:00
发布于 2023-09-19 14:37:00
编译 | 曾全晨 审稿 | 王建民
今天为大家介绍的是来自Anton V. Sinitskiy团队的一篇论述transformer模型在分子建模上能力的论文。在药物设计中,对药物分子的化学空间进行有意义的探索是一项极具挑战性的任务,这是由于分子可能的修改方式呈现组合爆炸的情况。在这项工作中,作者使用Transformer模型来解决这个问题,Transformer模型是一种最初用于机器翻译的机器学习(ML)模型类型。通过训练Transformer模型使用来自公共ChEMBL数据集的相似生物活性分子对,作者使其能够学习有关分子的药物化学上有意义且与上下文相关的转化,包括那些在训练集中不存在的转化方式。通过对Transformer模型在ChEMBL亚集上对COX2、DRD2或HERG蛋白靶点结合的配体的性能进行回顾性分析,作者证明尽管模型在训练过程中没有看到任何对应蛋白靶点活性的配体,但模型仍能生成与大多数活性配体相同或高度相似的结构。此项工作表明,在药物设计中从已知对某个蛋白靶点活性的分子“翻译”到对同一靶点具有活性的新型分子时,人类专家可以轻松快速地使用Transformer模型,而这些模型最初是用于将一种自然语言的文本翻译成另一种语言的。
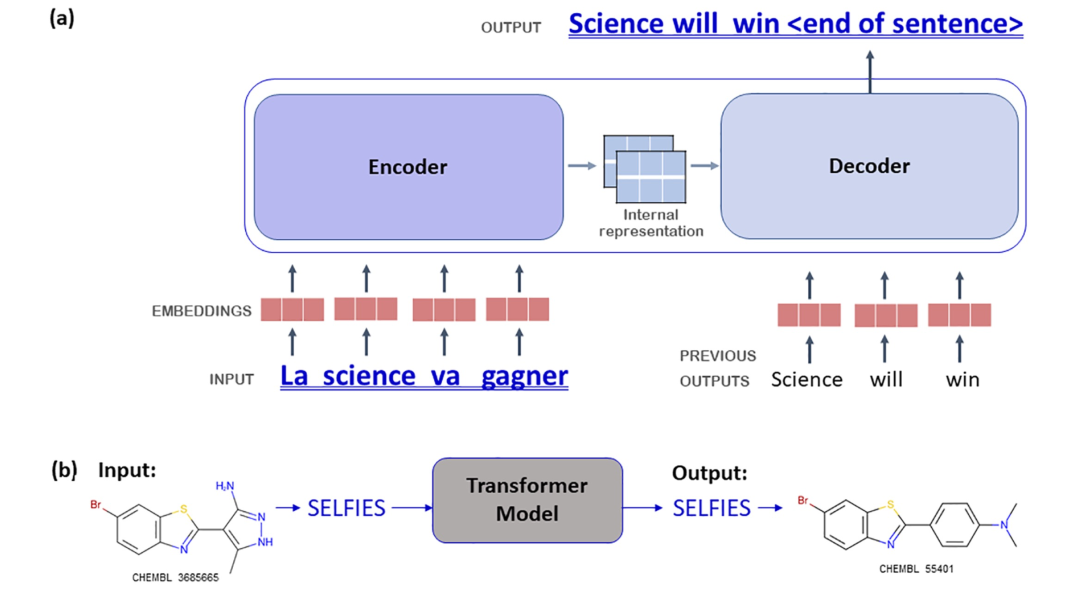
图 1
小分子药物发现的一个关键组成部分是扩大活性化合物的范围,即设计、合成和测试对某个蛋白靶点具有活性的候选化合物,当已经知道一些对该靶点具有活性的化合物("hits")时。成功的药物发现项目应该生成一组多样化的活性化合物,以提高药效并降低吸收、分布、代谢、排泄和毒性(ADMET)方面的风险。由于多种原因,扩大活性化合物的范围一直是一项艰巨的任务,包括化学上有意义的生物活性分子的可能修改方式呈现组合爆炸、需要确保新化合物的合成可及性,这通常将可能的修改限制为R基的轻微变化,以及分子结构与药物优化相关的多个性质之间的复杂关系。在这项工作中,作者使用Transformer模型来实现这一目标。Transformer模型最初在2017年提出,用于自然语言之间的翻译(图1a),并因其在机器翻译以及广义上可定义为“翻译”问题的各种任务上的成功应用而受到广泛关注,包括化学反应结果的预测和蛋白质结构预测。特别是,将Transformer模型应用于活性扩展的思想将其视为已知对某个靶点具有活性的分子“翻译”成对同一靶点应该具有活性(最好是更活性)的新型分子的过程(图1b)。
实验结果
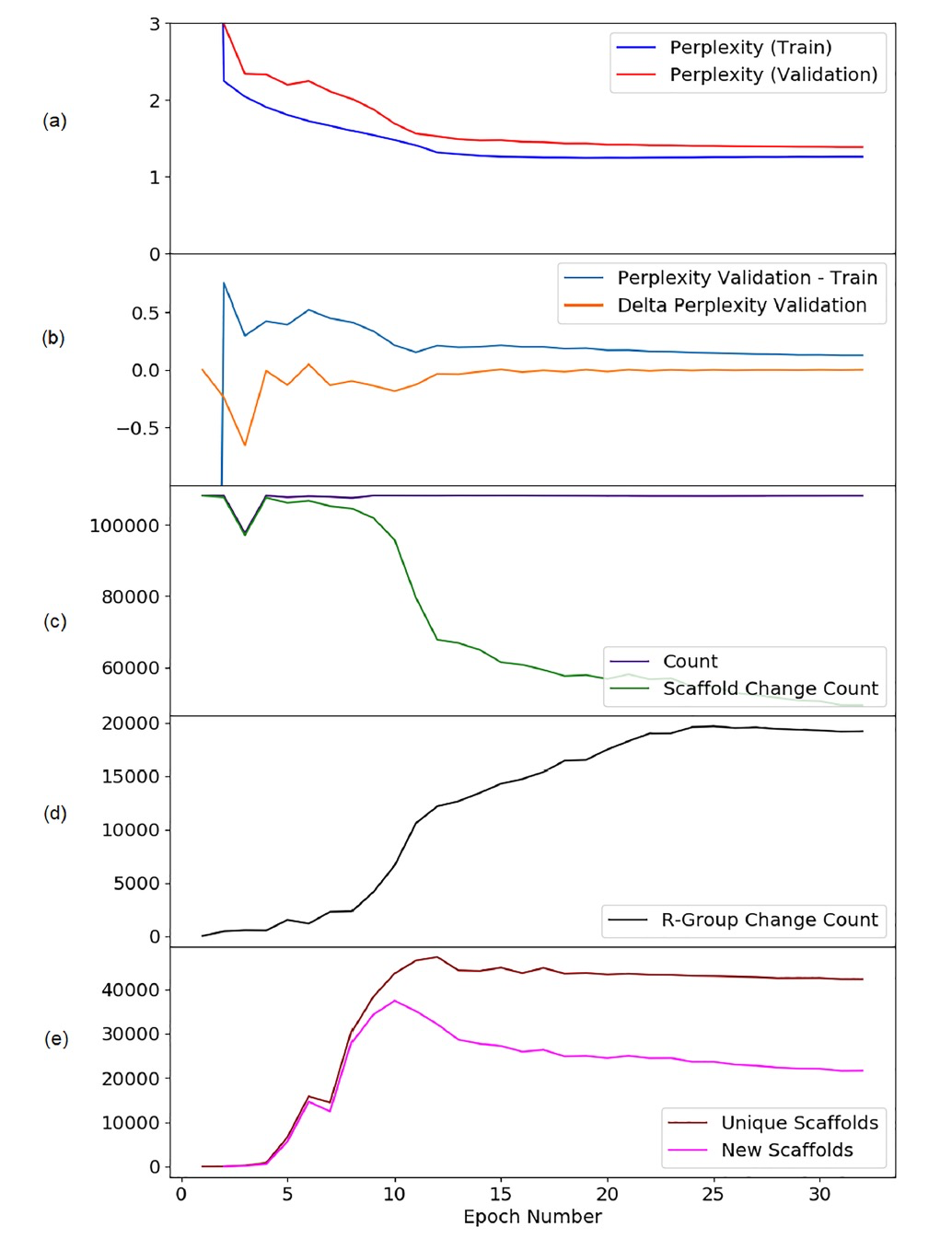
图 2
作者首先探讨的问题是在训练过程中,Transformer模型的常见信息理论评分与模型输出的化学评分之间的关系。在这项工作中,作者使用perplexity评分作为前者的代表;对于后者,作者计算了输出中生成的分子的总数、骨架变化转化的数量、R基团变化转化的数量、独特骨架的数量以及输出中的新骨架的数量。从训练perplexity(图2a)可以看出,在经过10到12个epoch后应该停止训练。为了方便观察,作者还绘制了当前epoch验证集和训练集困惑度之间的差异(图2b,“Perplexity Validation−Train”),以及当前和先前训练epoch中验证集perplexity的差异(图2b,“Delta Perplexity Validation”)。显然,经过10到12个epoch后,验证Perplexity稳定下来。然而,需要注意的是,这里不适用早停准则,因为即使在第32个epoch附近,验证Perplexity仍然非常缓慢地下降,使用这个准则即使在这样晚的阶段也不会停止训练。
值得注意的是,在训练的相同阶段(第10至12个epoch),我们观察到模型的化学评分模式发生了定性变化。虽然在各个epoch中生成的分子的总数保持几乎不变(“count”,图2c),但模型所采取的分子转化类型发生了变化。在第10至12个epoch之前,输出分子的骨架通常与相应的输入分子的骨架不同(“scaffold change count”,图2c),而在第10至12个epoch之后,生成的分子越来越多地具有与相应的输入分子相同的骨架,并且分子转化限于骨架装饰的改变(“R-group change count”,图2d)。此外,在第10至12个epoch中,生成的分子的最大多样性得到了实现,这通过生成分子的独特骨架数或相对于输入集的新骨架数来衡量(图2e)。在随后的epoch中,生成的新骨架数和影响骨架的转化比例减少,而简单转化(“R-group change”)的数量增加,作者将其解释为机器学习模型的过拟合现象。
因此,perplexity作为一种常见的基于信息理论的得分,在解决活性扩展任务时是适用的,并且可以用来替代化学评分,这在训练这种Transformer模型时具有更大的方法学便利性。
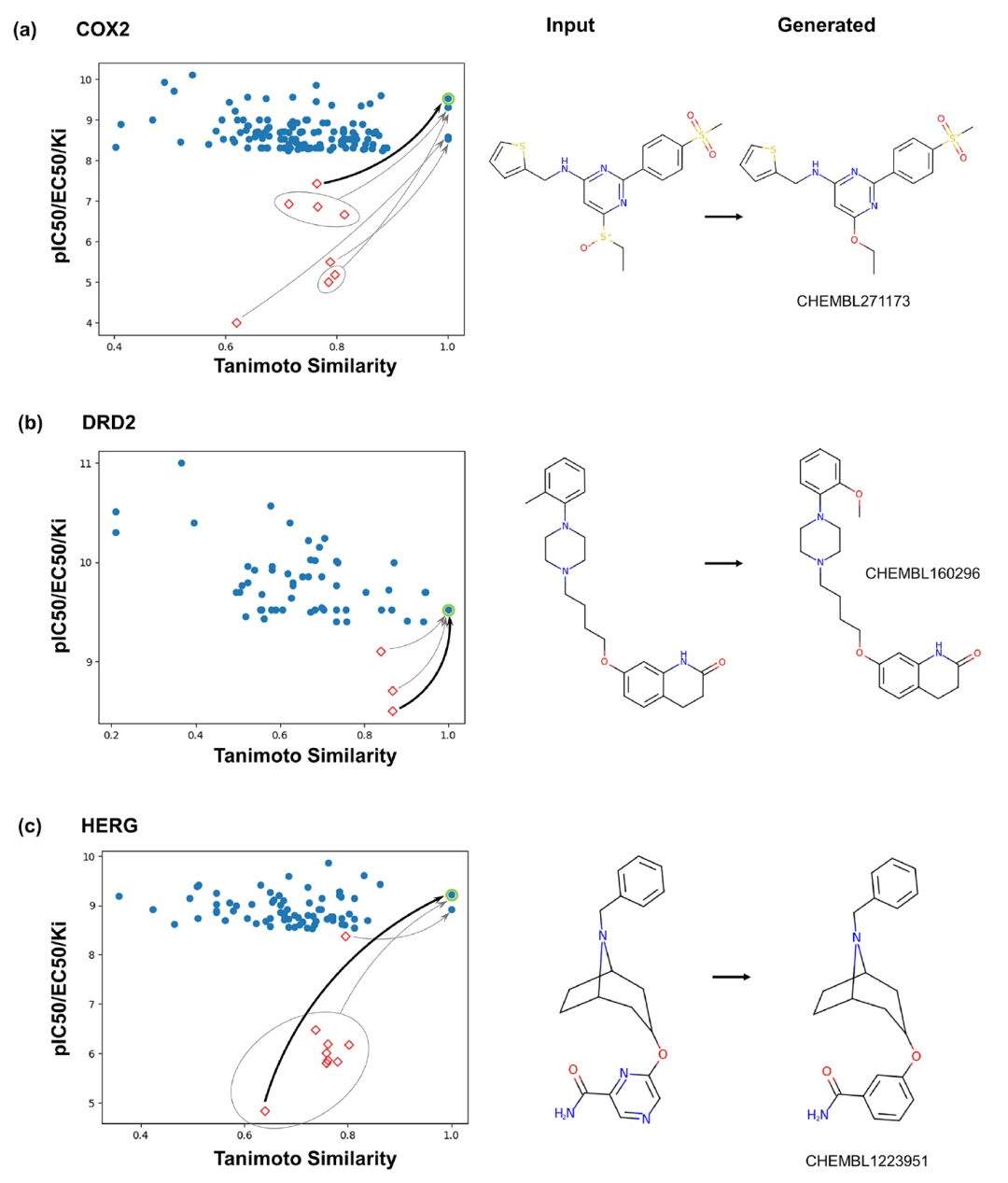
图 3
通过针对几个蛋白靶点进行回顾性分析,针对具有ChEMBL中可用的活性数据的几个蛋白靶点,即环氧合酶-2(COX2)、多巴胺D2受体(DRD2)和人类ether-a-go-go相关钾通道(HERG)蛋白,作者模拟了将Transformer模型应用于实际药物设计项目的情况。需要注意的是,HERG蛋白通常被视为药物设计中的抗靶标,因为它会引起严重的心脏副作用,但在这项工作中,作者将其视为一个靶标,以便可以在一个大型的公共分子数据集上测试所提出的方法。作者选择了这三个蛋白靶点,是因为可以获取到针对这些靶点的大量小有机分子的公共数据。因此,针对这三个蛋白靶点,作者训练了一个独立的机器学习模型,该模型没有看到针对给定靶点的活性分子。
接下来,对于每个靶蛋白,作者将其配体集合分成两个子集,基于配体的活性(根据靶标的pIC50、pEC50或pKi值)。95%的分子子集被用作Transformer模型的输入(“输入子集”),其中包括活性较弱和中等的配体,而5%最活跃的配体则形成了用于评分输出分子的“测试子集”。两个子集之间的边界位于几个纳摩尔(对于COX2和HERG)或亚纳摩尔(对于DRD2)范围内。通过这个95:5的划分,作者将生成的结构与最活跃的分子进行比较;在实际应用中,可以使用所有100%已知的活性分子作为输入,而不仅仅是95%。
需要注意的是,目标特异性信息仅包含在ML模型的输入中,而不用于训练ML模型本身。在实际应用中,这是一个重要的优势,因为不需要重新训练ML模型来对新的蛋白靶点进行预测头开始重新训练模型,以确保训练集不包括针对给定靶标的活性分子,以进行方法验证的目的)。
令人惊讶的是,这些针对特定靶标的模型竟然能够生成不仅仅是合理的分子结构,还能生成一些高活性配体对应于这三个蛋白靶点,或者至少为这些配体提供了一些想法(图3)。一些生成的分子与已知的高活性配体完全重合(图3中具有Tanimoto相似度等于1的蓝色点),而其他一些生成的分子与已知的活性分子略有差异(具有Tanimoto相似度约为0.8-0.9的蓝色点:它们通常仅在-Cl、-OH、-CH3基团等方面与测试子集中的高活性分子略有不同)。
为了说明活性变化的程度,作者在散点图中添加了关于用于预测输出分子的输入分子的信息,这些输入分子与测试集中的某个分子完全重合(图3中的红色菱形;为避免图表过于拥挤,未显示其他所有的输入分子)。输入分子和输出分子之间的配对关系用箭头表示(一些输入分子会生成相同的输出分子)。对于所有三个蛋白靶点,从高纳摩尔级活性的配体中预测出亚纳摩尔级活性的配体(在HERG的情况下,甚至是从高微摩尔级活性的配体中预测出)。
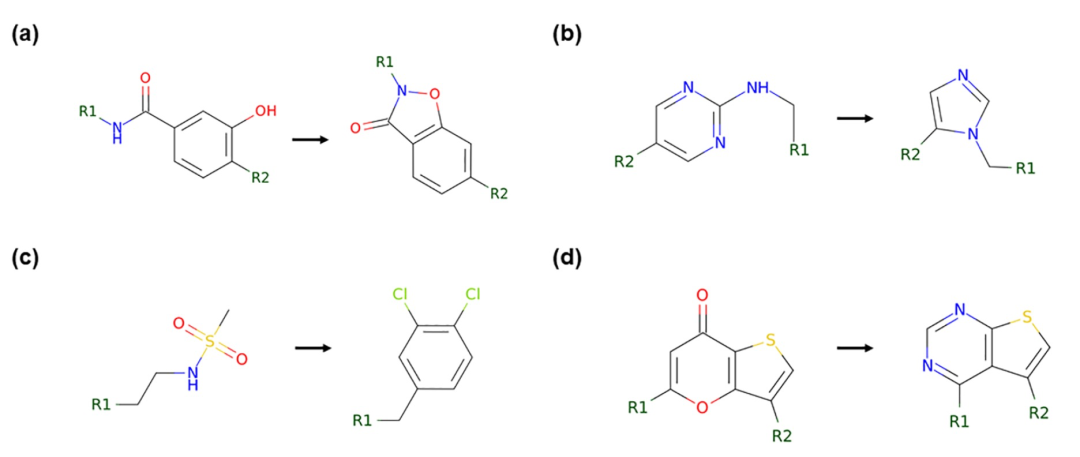
图 4
Transformer模型可以为活性扩展生成新颖的分子转化。由于在图3中展示的转化能够生成针对给定蛋白靶点的高活性分子,这些转化可以用传统的匹配分子对(Matched Molecular Pairs,MMP)方法进行识别,作者希望评估所提出的方法超越MMP的能力。因此,作者首先生成了针对在ChEMBL分子的训练子集中的所有MMP转化规则(以SMIRKS的形式表示);预期地,其中最常见的是单个原子(H、F、Cl等)或简单基团(甲基、甲氧基、乙基等)的添加或替换。然后将相同的过程应用于生成由Transformer机器学习模型(经过10个epoch的训练和过滤截断值为50)输出的分子与来自验证子集的输入分子之间的所有合理的SMIRKS。作者发现了1086个SMIRKS,表示Transformer模型发明的非明显的、药物化学水平的分子转化,这些转化不在训练子集中的MMP转化集合中(图4)。在许多情况下,这些新颖的转化可以用领域熟悉的广泛类别解释,例如通过环形成对分子的刚性化(图4a),R基团的置换(图4c),或者在保持关键药效团模式的情况下的杂环替换(图4b和4d)。
结论
Transformer模型可以成为药物设计中活性扩展的强大工具。作者使用Transformer模型为几个蛋白靶标(COX2、DRD2和HERG)生成了许多新颖的分子,这些分子与已知的高活性配体完全一致,或者在结构上非常接近它们(例如,仅仅替换一个原子或添加/删除一个甲基基团)。Transformer模型在生成依赖上下文的合理化学修饰生物活性分子方面超越了MMP。使用perplexity作为评估语言模型预测质量的常见信息理论基础得分,简化了针对活性扩展这一特定任务的Transformer模型的训练,因为perplexity与化学得分相关,并且可以代替化学得分使用。最后,作者证明了这种活性扩展方法的门槛较低,这个结论可能会推动进一步在高效的基于机器学习的药物设计方面取得进展。
参考资料
Tysinger, E. P., Rai, B. K., & Sinitskiy, A. V. (2023). Can We Quickly Learn to “Translate” Bioactive Molecules with Transformer Models?. Journal of Chemical Information and Modeling, 63(6), 1734-1744.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-19 00:01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号