LLM 的幻觉到底是什么,有什么办法解决?

LLM 的幻觉到底是什么,有什么办法解决?

NewBeeNLP
发布于 2024-02-28 13:52:48
发布于 2024-02-28 13:52:48
作者 | Conqueror712 整理 | NewBeeNLP https://zhuanlan.zhihu.com/p/682697588
大家好,这里是NewBeeNLP。今天分享关于大模型的幻觉现象。

省流版:幻觉是指模型生成的信息可能或 不准确 ,目前的办法只能 缓解 不能根除。
一、幻觉简介
LLM 时常会出现一些神奇的现象—— 幻觉 Hallucination ,在 AI 领域,幻觉是指模型生成的信息可能 不真实 或 不准确 ,这是一个常见的问题,而 Truthfulness 指的是模型输出的 真实性 或者叫 可靠性 ,显然如果模型输出的真实性越高,那么出现幻觉的概率就是越低的。
下面展示了 LLM 常见的几个衡量指标,今天我们主要来关注一下可靠性中的 幻觉 :
- 可靠性
- Misinformation 错误信息
- Hallucination 幻觉
- Inconsistency 矛盾
- Miscalibration 校准误差
- Sycophancy 谄媚
- 安全性
- 公平性
- 抗滥用性
- 可解释性和推理性
- 遵守社会规范
- 稳健性
二、可靠性的五个方面
Misinformation 错误信息
定义 :我们在这里将 Misinformation 定义为是由 LLM 无意生成的,而不是故意生成来对用户造成伤害的,因为 LLM 缺乏提供事实正确信息的能力。另外,我们可能会直观的认为 LLM 只会在有挑战性的问题上犯错,但事实上,有时 LLM 即使对于简单的问题也无法提供正确的答案,至少在没有复杂的 Prompt 设计的情况下是这样的,这也一定程度上说明了好的 Prompt 设计的重要性,所以让我们耐心的向 LLM 提问吧(笑)。
原因 :虽然 LLM 产生不真实答案的原因没有一个公认的原因,但存在一些猜测:
- 原生性问题 :因为训练数据不会完美,所以错误信息很可能已经存在,甚至可能在互联网的传播上得到强化
- 共现诱导 :大量实体的共现是从 LLM 中提取的不正确知识的原因之一,举个例子,小明和小红经常出现在同一篇文章里,模型可能会认为小明和小红是情侣,然而实际情况并不是这样
- 罕见知识 :LLM 在记忆不常见的实体和关系不太精确,如果利用检索到的外部非参数知识来预测不常见的事实的话会更好,在这时,检索模型比语言模型效果好
- 模型之间亦有差别 :对于 LLM 是否可以通过提示中提供的信息更新他们记忆的事实,有些模型可以,而有些不行
Hallucination 幻觉
定义 :LLM 可以信心满满地生成毫无意义或不忠实于所提供的源内容的内容,这在 LLM 中被称为幻觉。在心理学文献中,类似的现象被称为虚构,即无意欺骗的错误记忆,有时是由脑损伤引起的。请注意,幻觉和错误信息之间是有区别的:
- 错误信息大多意味着错误或有偏见的答案,通常可能是由于 错误的信息输入 引起的
- 但幻觉可能由 与源内容相冲突的捏造内容 (内在幻觉)或 无法从现有来源验证 (外在幻觉)组成。
原因 :梅开二度,产生幻觉的确切原因尚不清楚,不过也同样有一些猜测:
- 数据不匹配 :可能是由源训练数据和测试数据之间的不匹配或分布偏移引起。一些 NLP 任务自然需要源输入文本和目标参考之间存在一些不匹配,例如 Chat 风格的开放域对话。当 LLM 的置信度被错误校准时,幻觉也可能发生,这通常是由于缺乏人类监督、对齐示例覆盖率低以及监督数据本身固有的模糊性造成的
- 训练机制 :此外,幻觉可能是由潜在的训练机制引起的,包括但不限于对下一个标记进行采样时引入的随机性、编码和解码中的错误、不平衡分布的训练偏差以及对记忆信息的过度依赖等
评估与检测 :评估和检测幻觉仍然是一个正在进行的领域,常见的评估任务有:
- 文本摘要 :LLM 输出与参考文本之间的标准文本相似度是一个简单的指标,例如 ROUGE 和 BLEU
- QA :LLM 回答问题,我们计算 LLM 答案和真实答案之间的文本相似度
- 分类器 :训练真实性分类器来标记 LLM 输出
- 人工评估 :人工评估仍然是最常用的方法之一,这没得说
解决方法 :减轻幻觉也没有一种定式说应该如何解决最好,目前有的方法例如:
- 提高训练数据质量 :构建更可靠的数据集和数据清理
- 基于不同的任务在 RLHF 中使用不同的奖励 :在 Chat 中,Alignment 的奖励是生成的模板与从输入中提取的槽值对之间的差异。在文本摘要中,通过结合 ROUGE 和多项选择完形填空得分来设计奖励,以减少摘要文本中的幻觉。
- 外部知识库 :显然,利用外部知识库辅助检索也可以有不错的效果
Inconsistency 矛盾
定义 :LLM 可能无法向不同用户、不同会话中的同一用户,甚至同一对话的会话内的聊天中提供相同且一致的答案,这就是矛盾,想必大家都遇到过。
原因 :帽子戏法,不一致的确切原因尚不清楚,但 随机性 肯定发挥了作用,包括但不限于:
- 采样 token
- 模型更新
- 平台内隐藏操作
- 硬件规格的随机性
这表明 LLM 在 推理能力 方面可能仍然落后,这要求用户在 Prompt 时小心谨慎,从而提高了使用 LLM 获得正确答案的门槛。此外,训练数据中令人困惑和相互矛盾的信息肯定是原因之一,由此产生的不确定性增加了对下一个标记进行采样时的随机性产生输出。
解决方法 :关于如何提高 LLM 的 alignment 已经有一些讨论:
- 使用由不同输入表示的模型输出定义的一致性损失来调节模型训练
- 强制 LLM 自我提高一致性的另一种技术是通过 思维链 (COT)它鼓励 LLM 为其最终答案提供逐步解释
Miscalibration 校准误差
定义 :LLM 由于其固有的局限性,导致对缺乏客观答案的主题和不确定性的领域可能会表现出过度自信,这是应当警惕的。这种过度自信表明模型对知识库缺乏认识,从而导致自信但错误的回答。
原因 :大四喜最终还是没有出现,这种过度自信的问题部分源于 训练数据的性质 ,训练数据通常包含了互联网数据中固有的两极分化观点。
解决方法 :
- 有一种针对 Chat 模型的校准方法,鼓励这些模型在提供不正确的响应时表达较低的置信度
- 还有一种将标准神经网络中的 Softmax 输出重新调整的方法
然而,这些校准方法通常会带来权衡,对校准 Transformer 的实证研究表明,尽管域外任务略有改善,但域内性能却恶化了。对于 LLM,我们其实有两种方法来 计算不确定性 :
- 首先,如下图所示,LLM 在有针对性的 Prompt 时,确实可以以文本形式输出自己的置信度

- 其次,我们也可以通过以下方式获取 LLM 的置信度:token 的 logits,尽管某些平台可能不允许用户访问它们,例如 ChatGPT 和 GPT-4
- Alignment 步骤有助于遏制过度自信,这些研究强调教学模式以语言表达不确定性,提供一种柔和且经过校准的偏好来传达不确定性。例如上图所示的那个例子,然而,这种方法需要精炼的人工标签信息来进行微调和开发新的训练机制,这些机制可以正确地利用这些信息
- 一种新兴的机制可以帮助模型轻松 放弃 回答问题,这是选择性分类器的作用。这些模型可以提供诸如我不知道答案或作为人工智能模型,我无法回答之类的响应,特别是当任务超出其领域时。通常,选择性分类会使用分类器的 Softmax 输出来预测高确定性样本的结果,并放弃低确定性样本的结果
- 此外,在各种 NLP 任务中使用 保形预测 方法提供了有希望的进步。这些努力,与域外检测策略以及通过事后缩放和微调改进模型校准的方法相结合,共同表明,尽管 LLM 通常校准不佳,但这些挑战可以可以通过更先进的方法部分解决
Sycophancy 谄媚
定义 :LLM 可能倾向于通过再次确认用户的误解和既定信念来奉承用户。当用户挑战模型的输出或反复强迫模型遵守时,这是一个特别明显的现象。下图是一个好笑的例子,尽管模型最初进行了正确的计算,但它会退回到用户暗示和坚持的错误计算:

原因 :请注意,谄媚与回答错误的原因不同:
- 谄媚主要是因为我们对 LLM 的教学微调太多,以至于无法让他们服从用户的真实意图,以至于违背事实和真理
- 另一方面,由于模型内部缺乏逻辑或推理,并且与用户提示的内容无关,可能会出现不一致
- 此外,这还可能是由于训练数据中现有的阿谀奉承的评论和陈述造成的,这也可以归因于有时对 LLM 的过多指示,要求其提供帮助且不冒犯人类用户
- 再者,RLHF 阶段有可能促进并强制执行人类用户的确认,在 Alignment 过程中,LLM 会被输入友好的例子,这些例子可以被解释为对人类用户的阿谀奉承
因此,对现有 RLHF 算法的一个重要改进是平衡阿谀奉承的程度和与人类用户一致的程度之间的权衡。
三、减少幻觉的方法
这里只是给出常见的几种方法,并不是所有方法
数据处理阶段
- 数据质量和多样性 :选择高质量、多样性和平衡的数据集进行训练。这包括从多个来源收集数据,以及确保数据覆盖了各种主题和领域
- 数据清洗 :在训练模型之前,对数据进行清洗和预处理,以去除错误、偏见和不相关的信息
- 数据标注 :对数据进行标注,以提供关于信息真实性的额外信息。例如,可以标注数据中的事实是否正确,或者是否包含误导性的信息
训练阶段
- 模型微调 :在特定任务或数据集上进一步训练模型,以改善模型在特定上下文中的表现
- 模型结构和参数选择 :选择或设计适合任务的模型结构,并调整模型的参数,以优化模型的性能
- 模型集成 :训练多个模型,并结合它们的输出,以提高输出的真实性
- 有限状态约束 FST :使用约束解码,将输入的 FSA x 与一个特殊的 FST T 进行合成,用于编码所有可能的分段决策,并将其投影到输出带中,以获得输出空间的确定性有限状态自动机
后处理阶段
- 后处理和过滤 :在模型生成输出后,使用各种策略来过滤或修改输出,以提高其真实性
- 模型解释和可视化 :理解模型的决策过程,以帮助识别可能的问题并改进模型
- 用户反馈 :收集用户对模型输出的反馈,并使用这些反馈来改进模型
- Levenshtein 事后对齐算法 :我们使用它将生成的字符串与参考字符串进行对齐,在 LLM 没有精确重新创建输入时,可以消除一些不流畅的文本
- Web 检索确认
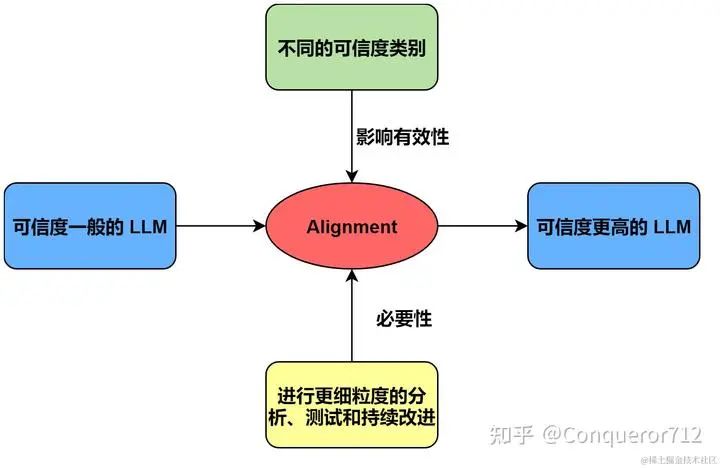
另外,一般来说,进行更多 Alignment 的模型在整体可靠性方面往往表现更好。不过 Alignment 的有效性也会因所考虑的不同可靠性类别而异,这凸显了进行更细粒度的分析、测试和持续改进 Alignment 的重要性,我们可以用一张图来表示:
四、相关讨论
幻觉的来源
有人认为,幻觉来源于预训练和 SFT(有监督微调),因为我们希望模型尽可能的能回答我们的问题,尽管他们可能回答的不对,由此带来的三个负面影响是:
- 模型在回答的时候,不知道自己可以回答 我不知道 或者表达不确定性
- 模型有时不愿意去提出质疑,它认为 肯定回答 是数据任务的一部分
- 模型有时会 陷入谎言 之中。如果模型已经犯了一个错误,那么它会认为自己应该继续回答下去
行为克隆 是强化学习领域的一个术语,意思是监督微调或最大化似然,其目的是完成给定 Prompt 的最大化似然或最大化对数概率。如果用行为克隆来训练模型,比如使用人类编写的正确答案或使用 ChatGPT 的输出进行训练,那么即使用 100 个正确的答案进行克隆,由于模型缺乏所有相关的事实,仍然是在教会模型产生幻觉。
如果你使用行为克隆来训练模型,那么无法避免出现幻觉问题,同时也会出现相反的问题,即如果你想训练模型在某些情况下回答 我不知道 ,那么它可能会隐瞒实际上已经知道的信息。
例如,如果标注者不知道答案,他们可能会将我不知道列为目标答案,但实际上网络可能已经有了答案,你只是在训练模型隐瞒信息。
因此,行为克隆或监督学习的问题在于: 正确的目标实际上取决于神经网络中包含了哪些知识,而这对于收集数据或进行实验的人来说是未知的。 所以,除非你有一种方法来查看模型中的内容,否则无法使用行为克隆训练出真实可信的模型。
如果尝试用监督学习数据集来训练另一个模型,也会遇到同样的问题。
例如,许多人正在使用 ChatGPT 的输出来微调开源基础语言模型。微调后,这些模型的表现很好。但如果仔细查看事实准确性,你会发现它们存在一些问题,并且经常会编造信息。不过这只是我预测的结果,还有待实验证实。
强化学习
有人认为, 强化学习 可以解决这个问题,部分幻觉仅因为模型陷入想要 给出完整答案 的模式或不知道如何表达不确定性而产生,因此这类幻觉很好解决。比如可在训练模型时给出一些表明 我不知道 、 我的知识截止于某某日期 的示范,或者给出一些质疑用户提问的范例,这样模型至少能够表达不确定性,而如何掌握这个 度 ,就是强化学习要解决的问题(本质上和训练狗狗没有区别),当模型给出一个答案,如果是非常自信的正确答案,将得到高额奖励;如果是模糊的正确答案,将得到稍差的奖励;如果是无信息的答案,例如我不知道,将得到一些惩罚;如果是模糊的错误答案和完全错误的答案,将得到更多的惩罚。这基本是一个适当的评分规则,能够激励模型给出自信的答案,如果它对错误答案过于自信,就会给出相应惩罚。
实际上,有一个被设置为 TriviaQA 模式的实验,TriviaQA 是一个流行的问答数据集,它包含了一系列常识问题,这个实验使用了一种基本的问答格式来引导模型回答问题,如果你只在正确答案上进行行为克隆,那么模型对所有问题都会给一个回答,但往往会包含一些错误答案。因为我们从未告诉它输出 我不知道 这样的答案,若遇到不知道的问题,它只能进行猜测而不会说 我不知道 。在对答案进行行为克隆时,只需要少量训练后模型就达到一定的准确率和对数损失,但这种训练只是在教模型它应该试图输出正确答案,模型实际上没有从这种微调中学习很多新知识,学到的只是问题格式及其处理方式。
某种程度上,我们可以通过解析计算来得出正确的奖励行为,即错误答案的惩罚与正确答案的奖励之间的差异。最优奖励行为可以简单理解成确定某种阈值,譬如当列表中排在最前的选项有超过 50% 的概率时就回答,否则就不回答。如果我们将奖励函数用于强化学习,模型就会学到最佳阈值行为,就像模型已经了解最佳策略。因此,如果使用强化学习微调模型,就可以让它做同样的事情,即使它并没有真正查看到这些概率。
如果你问 ChatGPT 一个技术问题,可能会得到正确、错误或具有误导性的答案,让标注者来判断答案是否有误往往行不通。所以需要让人们对回答进行排序,并说出哪个更好而不是最好。人们必须根据错误的严重程度来判断模型给出的答案,这在很大程度上取决于上下文。举一个编程的例子:模型写了 100 行代码,只有一个地方的参数写错了,这种情况下我宁愿让它给出这个答案,也不愿让它回答不知道,因为我至少可以在其基础上运行和调试。但是在其他情况下,这种错误可能是一个大问题。
事实上,ChatGPT 已经使用了一种常见的奖励机制——人工标注的排序序列,如下是示意图:
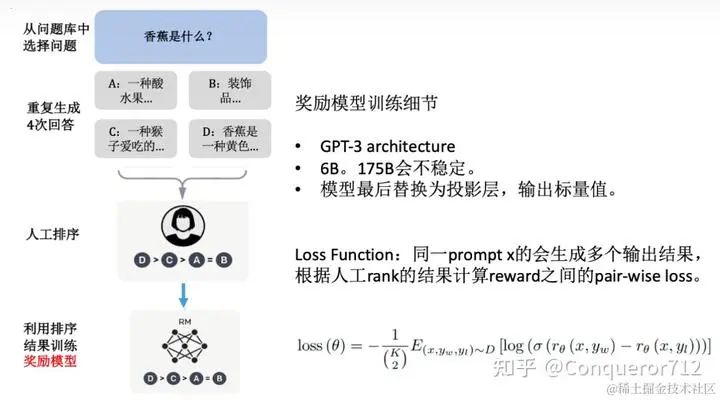
这样做的好处想必不用多说,一个是节约人力成本,另一个是防止个体差异。
然而,模型并没有就事实错误的严重程度和错误的模糊程度施以正确的惩罚,所以可以说,基于排名的奖励模型没有很好地解决这个问题。此外,标注者的错误肯定也有很多。有时标注者没有足够的信息来做出正确的标注,人类无法始终正确地进行排名,比如有些问题可能涉及到用户计算机上的某些代码库,标注者就无法访问。
综上所述,现在的方法都是尽可能地缓解幻觉,而不能根除幻觉,更有效的方法有待进一步研究,让我们拭目以待。
本文参考资料
[1]
1] [TRUSTWORTHY LLMS: A SURVEY AND GUIDELINE FOR EVALUATING LARGE LANGUAGE MODELS’ ALIGNMENT, Research, August 9, 2023: https://arxiv.org/pdf/2308.05374.pdf
[2]
2] [Large Language Models Help Humans Verify Truthfulness – Except When They Are Convincingly Wrong, October 2023: https://link.zhihu.com/?target=http%3A//arxiv.org/pdf/2310.12558.pdf
[3]
3] [Long-Form Speech Translation through Segmentation with Finite-State Decoding Constraints on Large Language Models, 23 Oct 2023: https://link.zhihu.com/?target=http%3A//arxiv.org/pdf/2310.13678.pdf
[4]
4] [https://juejin.cn/post/7229891752647950394: https://juejin.cn/post/7229891752647950394
[5]
5] [https://zhuanlan.zhihu.com/p/655152338: https://zhuanlan.zhihu.com/p/655152338
[6]
6] [https://zhuanlan.zhihu.com/p/595579042: https://zhuanlan.zhihu.com/p/595579042
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号