Nat. Mach. Intell. | 药物设计中的多任务学习

Nat. Mach. Intell. | 药物设计中的多任务学习

今天为大家介绍的是来自Gisbert Schneider团队的一篇论文。多任务学习是一种机器学习范式,旨在通过利用多个任务之间的共享信息来增强预测模型的泛化能力。深度神经网络模型在各个领域取得的突破性成就,为化学科学的类似进步带来了希望。在本文中,作者提供了神经型应用于多任务学习计算机辅助药物设计的当前状态和未来潜力的见解。在药物发现的背景下,多任务学习的一个突出应用是进行蛋白质-配体结合亲和力预测。本文介绍了多任务学习的基本原则,并提出了一个框架,用于根据其架构来对多任务学习模型进行分类。

在单任务学习(STL)中,模型专注于预测实例与特定任务之间的关系,通常为每个任务单独训练一个模型,从而并行处理各自的预测任务。相比之下,多任务学习(MTL)通过一个统一的框架同时学习多个任务,这种方法通过共享信息增加了学习效率,有助于模型更好地从组合数据中提取知识。MTL的核心优势在于某些模型组件在不同任务中的共享,这种共享自然形成了正则化,从而增强了模型的泛化能力和整体性能。正则化通过在学习过程中引入约束或惩罚,帮助模型更平衡且准确地捕捉底层数据的模式。当多个任务具有相似性时,MTL能有效地在任务之间转移信息,提高预测的准确性。MTL的应用广泛,涵盖计算机视觉、生物信息学、语音识别和自然语言处理等多个领域。其可以构建为一种双输入预测模型,其中实例和任务对作为输入,输出为它们之间的关系。这种双输入框架的对称性使得实例和任务的角色可互换,增加了模型设计的灵活性。此外,MTL通过在不同任务间共享信息,不仅提高了预测效率,还增强了模型的泛化能力。
成对输入的MTL模型流程
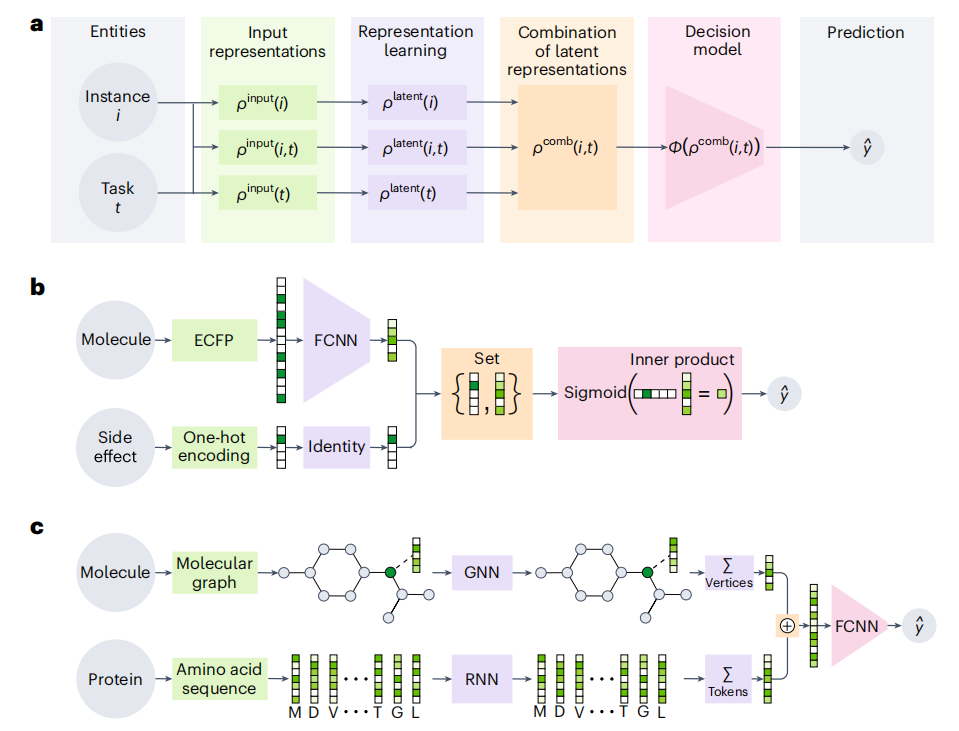
图 1
药物设计中使用的神经网络基础的MTL模型大多可以拆分为几个独立的模块,这些模块可以通过图1a中所示的双输入MTL模型流程来解释。这个流程的输入包括实例和任务的配对,分别用i和t表示。这些配对可以单独表示,例如ρinput(i)和ρinput(t),或者联合表示ρinput(i,t)。专门用于这一上下文的神经网络基础的表示学习模型旨在构建实例的潜在表征[ρlatent(i)]、任务的潜在表征[ρlatent(t)]或者两者的组合[ρlatent(i,t)]。这些潜在表征是基于相应的输入表征(ρinput)构建的。这些潜在表征随后合并成一个统一的实例-任务对的潜在表征[ρcomb(i,t)]。最后,这个组合表征通过一个决策模型ϕ输入,该决策模型的任务是预测实例和任务之间的关系,表示为。
图1b展示了一个利用扩展连接指纹(ECFP)对分子结构进行编码的模型预测过程。ECFP通过迭代或递归地收集分子结构的邻域信息以构建分子的表示形式,这些表示形式为使用多输出前馈卷积神经网络(FCNN)学习分子的潜在特征提供了基础。在这一模型中,副作用通常以单热向量的形式编码,并未进行深入的表征学习。副作用的指示是通过应用sigmoid函数到分子潜在表示的内积来计算的,最终得到分子潜在特征与副作用之间的关系表示。
图1c则展示了另一个模型,用于预测蛋白质与配体的结合亲和力。在此模型中,配体被表示为一个原子作为顶点、键作为边的分子图,而蛋白质则通过其氨基酸序列表示。图神经网络(GNN)和递归神经网络(RNN)分别用于学习顶点和标记的潜在表示。将这些潜在表示求和后,获得的分子和蛋白质的综合潜在表示输入到FCNN决策模型中,用以预测二者之间的结合亲和力。
输入数据的表示
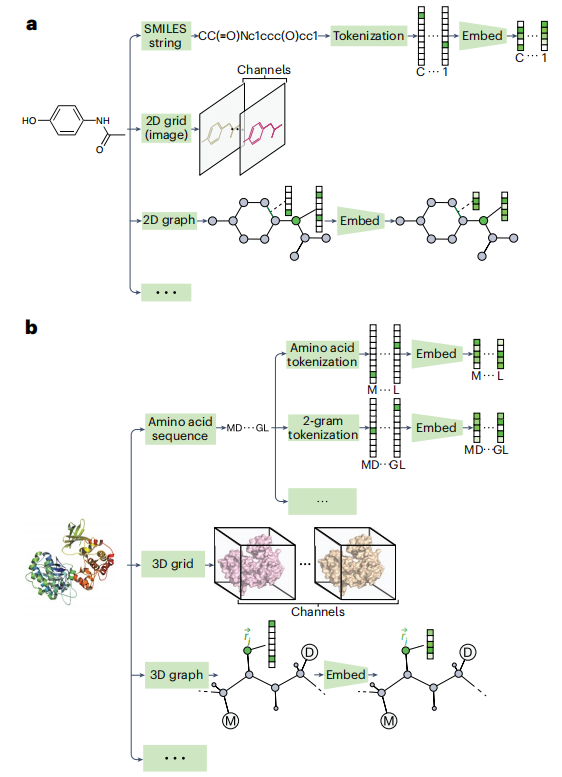
图 2
单热编码是一种广泛应用的技术,适用于表示分类元素,如在MTL药物设计中将蛋白质视为分类标签时。这种编码方法不仅有效地捕捉了任务或实例的分类属性,还便于模型分析和建模。常见的分子输入表示包括SMILES字符串、二维图像及二维特征图,如图2a所示。而蛋白质输入表示通常包括氨基酸序列、三维网格图和三维特征图,如图2b所示。
对于蛋白质与分子对的表示,共享的输入表示能够揭示蛋白质与配体之间的复杂相互作用,提供有价值的见解。这些表示方式利用X射线衍射等技术从蛋白质-配体复合物中获得的结构数据构建,得到相互作用指纹及三维网格图以及三维特征图。
表示学习
药物设计领域中,表示学习对于MTL至关重要。选择适当的表示模型密切依赖于输入数据的表现形式。以下是几种常用于药物设计的表示学习模型:
前馈卷积神经网络(FCNNs):应用于向量输入如分子指纹或描述符向量。通过神经切线核的核回归方法,FCNN的宽隐藏层提高了计算效率,并优化了传统模型训练过程。
自编码器(AEs):以自监督方式学习分子的潜在表示,可进行预训练或与其他模块一起端到端训练。
卷积神经网络(CNNs):用于网格输入表示,能够学习分子和蛋白质字符串的潜在表示,涵盖一维、二维及三维CNN。
递归神经网络(RNNs):专用于序列数据,如字符串,通过聚合方法(例如求和)获得序列的整体潜在表示。
变换器(Transformers):构建序列的潜在表示,功能类似于RNNs,例如用于氨基酸序列。
图神经网络(GNNs):学习图中顶点或边的潜在表示,并通过聚合(通常是求和)得到图的整体表示。
表示学习模型可通过两种堆叠方法组合以发挥互补优势:一是并行堆叠,即多个模型共享同一输入并合并输出;二是顺序堆叠,即一个模型的输出成为另一个模型的输入。在多模态学习中,例如,分子的字符串和图形表示可以并行处理并融合,以得到更全面的分子表示。
组合潜在表示与决策模型
在MTL中,有多种方法可以组合不同的表示学习模型,包括拼接、聚合、外积、身份机制和注意力机制。如图1b所示,在重新设计的多输出MTL模型中,多种潜在空间被融合成一个统一的集合。选择适当的决策模型需基于所需学习关系的数据类型(分类、序数或连续)及其概率分布(如正态分布、伯努利分布或分类分布)。在药物设计领域的MTL应用中,常见的决策模型包括线性模型、前馈卷积神经网络(FCNNs)和相似度测量方法。
MTL面临的一大挑战是如何平衡模型中各个任务的影响。任务权重在模型设计中至关重要,它通过特定的损失函数为不同任务的损失分配不同的权重,帮助模型为各个任务确定恰当的重要性。这种策略特别适用于任务重要性各异的情形。
编译 | 于洲
审稿 | 王建民
参考资料
Allenspach S, Hiss J A, Schneider G. Neural multi-task learning in drug design[J]. Nature Machine Intelligence, 2024, 6(2): 124-137.
腾讯云开发者
