强化学习赋能视觉-语言-动作模型:进展、机制与前景综述


摘要
视觉-语言-动作(Vision-Language-Action, VLA)模型作为具身智能的核心范式,正推动机器人及自动驾驶向通用决策系统演进。然而,传统监督微调(SFT)依赖高质量演示数据、泛化能力有限、难以适应动态环境等瓶颈日益凸显。强化学习(RL)技术通过引入目标驱动、环境交互与奖励信号,为突破VLA模型的上限提供了关键路径。
图1.图片来源于网络
VLA模型的瓶颈与RL的赋能契机
VLA模型通过预训练(大规模视觉语言数据)与监督微调(机器人演示数据)获得多模态理解与动作生成能力。但其落地面临三大核心挑战:
- 数据依赖与质量困境:SFT严重依赖大量高质量、一致性的人类演示数据,采集成本高昂且易受噪声影响。
- 泛化能力不足:在分布外场景(新物体、新布局、新任务目标)或长程多步骤任务中,纯模仿学习策略易失效。
- 缺乏主动优化与闭环反馈:SFT本质为开环模仿,模型无法根据动作结果自我修正,难以实现安全探索与目标对齐。
强化学习的核心价值在于:
- 奖励驱动优化:替代被动模仿,通过设计/学习奖励函数引导模型主动优化策略。
- 高效利用交互数据:从环境试错中学习,降低对演示数据的依赖,尤其擅长处理次优或稀疏奖励场景。
- 提升鲁棒性与适应性:在交互中学习应对状态扰动与任务变化,增强模型在开放世界的泛化能力。
RL优化VLA模型的核心技术路径
2025年的研究聚焦于高效、安全、可扩展的RL-VLA融合范式,涌现出以下关键方向:
1. 高效微调框架:离线-在线协同与一致性策略
ConRFT (Reinforced Fine-Tuning via Consistency Policy):提出两阶段微调框架。
- 离线阶段:融合行为克隆(BC)与Q学习(如CPQL),利用少量演示数据稳定策略与价值函数初始化。
- 在线阶段:引入基于一致性策略的微调目标,并结合人机交互环(HIL) 实现安全探索。实验表明,仅需45-90分钟在线交互微调,即可在8个真实任务上达到96.3% 平均成功率,较SFT提升144%。
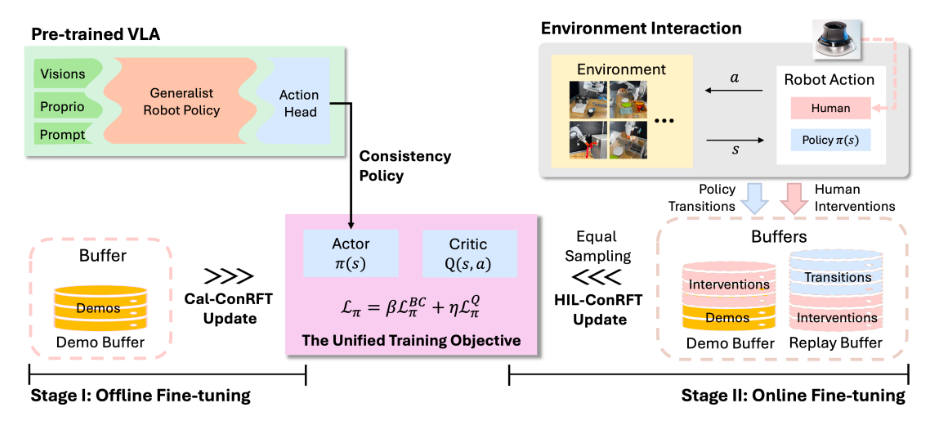
图1 ConRFT框架
RIPT-VLA (Interactive Post-Training):开创性提出在传统预训练+SFT后增加第三阶段—互动式后训练。
- 机制:模型在环境中执行多轮尝试,仅接收二元(成功/失败)反馈。通过动态采样留一出优势估计 (Dynamic Sampling LOO-PPO),对比同一任务下不同尝试轨迹的优势,无需复杂奖励函数或价值模型。
- 效能:显著提升数据效率与泛化。轻量模型QueST平均提升21.2%;大型OpenVLA-OFT达97.5% SOTA成功率;极端情况下,仅用1个演示样本+15次迭代,任务成功率从4%飙升至97%。跨场景泛化实验中,成功率提升最高达93.7个百分点。
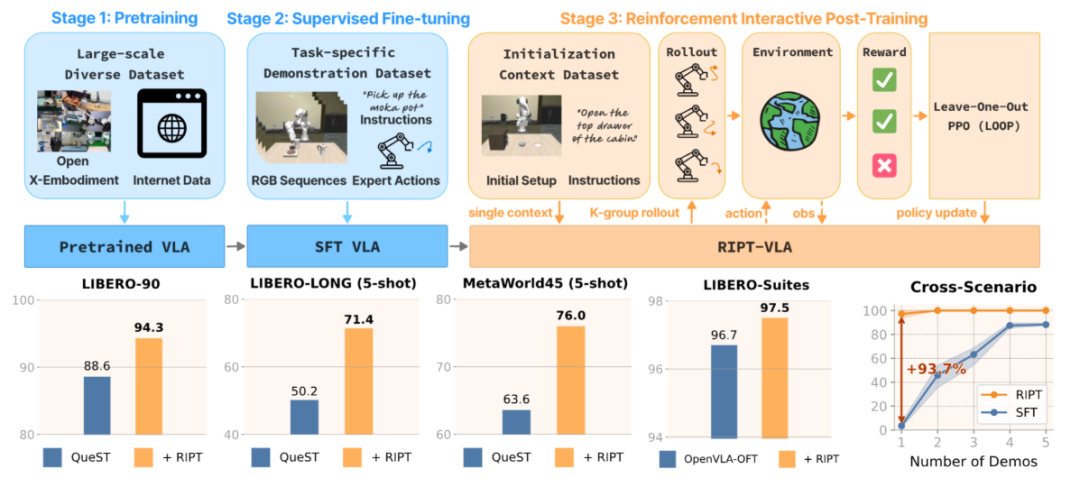
图2 RIPT-VLA框架
2. 奖励工程与偏好对齐:从稀疏反馈到密集指导
ReinboT:密集奖励预测:针对长视界操作任务,提出将任务自动分解为子目标序列,并设计包含4要素的密集奖励函数:
- 子目标达成(本体/像素/特征点匹配)
- 任务进度
- 行为平滑度(抑制抖动)
- 任务完成,
该奖励引导VLA模型预测最大化累积回报(ReturnToGo)的动作,显著提升操作鲁棒性与稳定性。
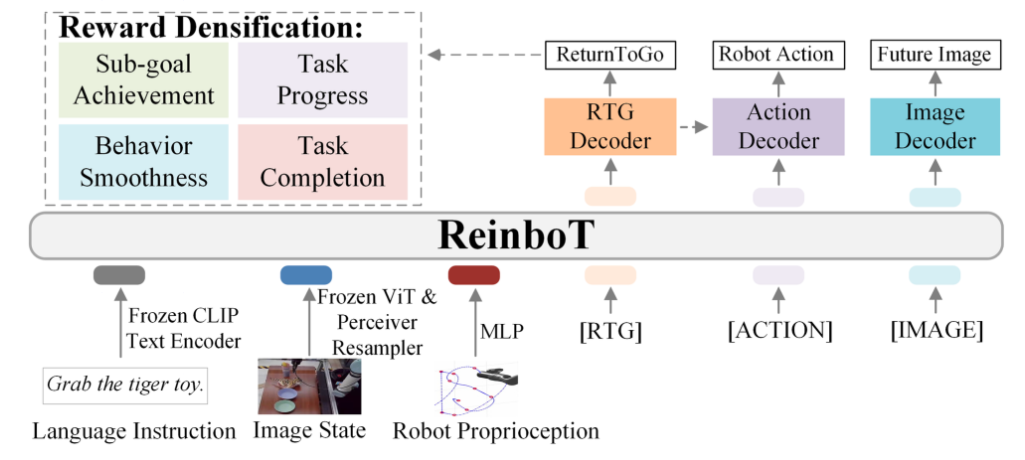
图3 端到端的ReinboT框架
GRAPE (Generalizing Robot Policy via Preference Alignment):通过轨迹级偏好优化 (TPO) 实现与任意目标(安全、效率、任务完成度)的对齐。
- 利用大型视觉语言模型分解任务阶段并合成偏好数据;
- 采用改进的DPO损失进行轨迹级偏好学习;
- 支持迭代式在线对齐,持续提升泛化能力。
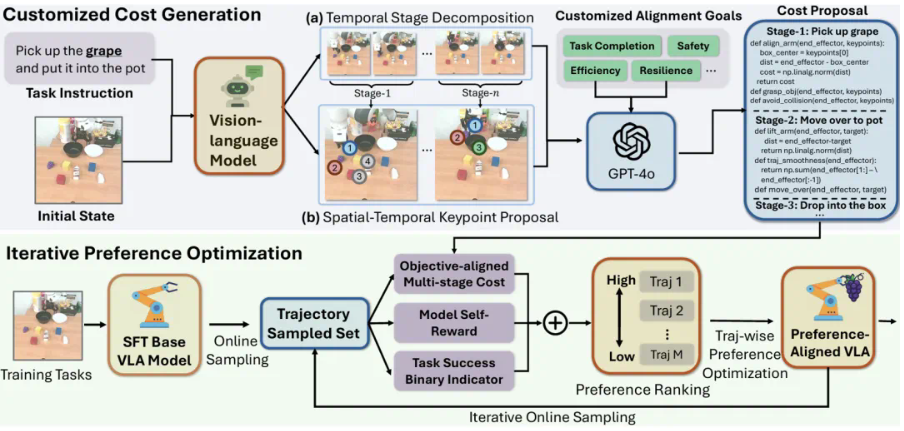
图4 GRAPE框架
3. 架构创新与训练稳定性保障
V-Triune (MiniMax):首个面向VLM后训练的统一视觉RL框架,解决感知与推理任务无法联合优化的问题。核心创新:
- 样本级数据格式化:支持自定义奖励与验证器。
- 验证器级奖励解耦:异步计算感知/推理任务奖励。
- 动态IoU奖励:分阶段调整阈值,优化定位精度训练。基于此训练的Orsta模型在MEGA-Bench Core上性能提升高达+14.1%。
- 稳定训练技术:普遍采用冻结ViT骨干、过滤伪图像Token、构建随机化CoT提示池等技术,解决联合训练中的梯度爆炸与指标波动问题。
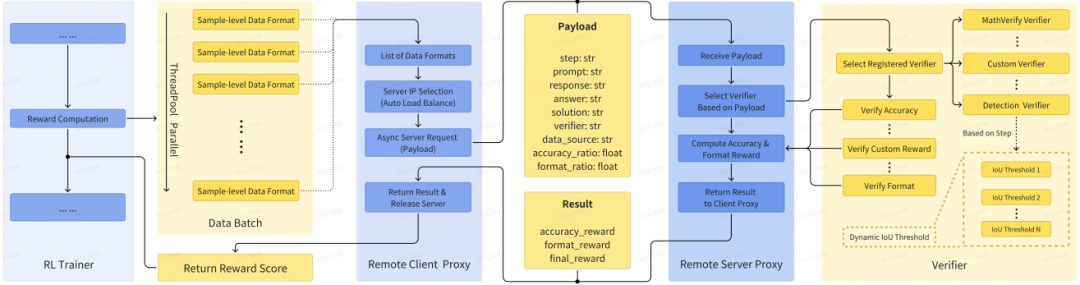
图5 V-Triune框架
4. 世界模型与云端-车端协同
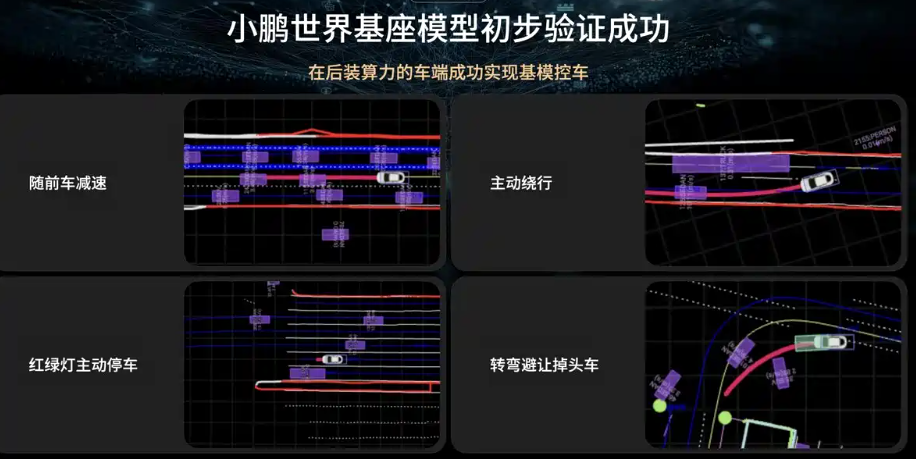
- 小鹏汽车“世界基座模型”:研发720B参数VLA基座模型,验证VLA的Scaling Law效应。强调强大基座是RL激发上限的前提,并构建云端RL训练框架(数据达2亿Clips)。通过云端蒸馏将大模型能力迁移至车端,突破车端算力限制。
- 世界模型作为训练场:小鹏、理想等布局世界模型,模拟环境状态与智能体响应,为VLA提供安全的闭环训练环境,支持在线强化学习和持续进化。
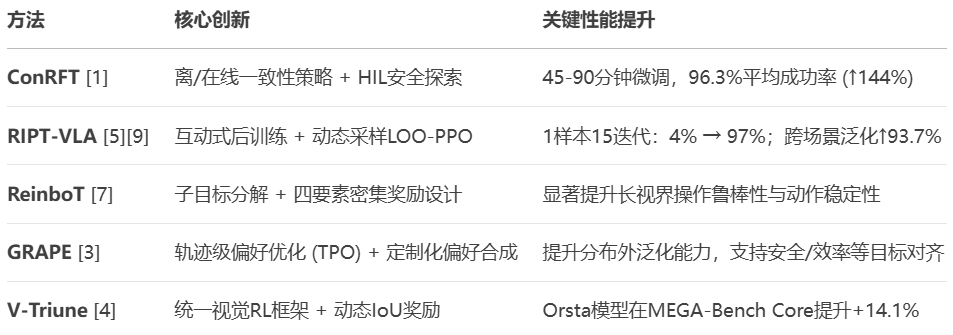
图6. 2025年代表性RL-VLA方法核心创新与性能对比
从实验室到产业落地
机器人操控:RL赋能的VLA在LIBERO、MetaWorld等基准上普遍将成功率提升至90%+,尤其在长程任务和少样本场景优势显著。
自动驾驶:
理想汽车VLA司机模型结合RLHF与世界模型仿真,计划2026年落地城市道路。

小鹏汽车基于云端大模型蒸馏+车端VLA,实现“后装算力控车”。
挑战与未来方向
尽管成果显著,RL-VLA融合仍面临严峻挑战:
1. 奖励设计普适性:手工设计密集奖励(如ReinboT)复杂且需领域知识;稀疏/二元奖励虽简单(如RIPT)但可能限制复杂任务性能。方向:结合LLM自动生成奖励、探索无奖励RL。
2. 安全与探索平衡:真实世界交互成本高且风险大。方向:世界模型仿真、可信安全约束策略、人机协作探索(如ConRFT的HIL)。
3. 异构数据协同:如何高效融合离线演示、在线交互、偏好数据及多任务数据仍需探索。
4. 系统级整合:实现“大脑”(VLM)与“小脑”(底层控制)的端到端训练与闭环推理仍处早期。
5. 计算成本:训练超大VLA基座模型及在线RL对算力要求极高。方向:更高效RL算法、分布式训练优化。
总结
2025年,强化学习已成为释放VLA模型潜力的关键引擎。通过高效微调框架(ConRFT, RIPT)、创新奖励机制(ReinboT, GRAPE)、统一训练架构(V-Triune) 及云端-世界模型支持,RL显著提升了VLA的样本效率、任务性能、泛化能力与目标对齐性,并推动其在机器人、自动驾驶等领域的快速落地。未来研究需着力解决奖励普适性、安全保障、系统整合与计算效率等核心挑战,以实现VLA驱动的通用具身智能体的终极愿景。
参考文献
1. ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy. Chen et al. arXiv:2502.05450 (2025).
2. GRAPE: Generalizing Robot Policy via Preference Alignment. Zhang et al. arXiv:2411.19309 (2024/25).
3. V-Triune: MiniMax’s Unified Visual RL Framework for VLM Post-Training. Yan et al. arXiv:2505.18129 (2025).
4. RIPT-VLA: Interactive Post-Training for Vision-Language-Action Models. Tan et al. arXiv:2505.XXXXX (2025).
5. ReinboT: Amplifying Robot Visual-Language Manipulation with RL. (Institution: Zhejiang Univ. & Westlake Univ.) (2025).
相关阅读:2024年度历史文章大汇总
特别提醒:有意购买智元灵犀系列和宇树系列产品的朋友,以及需要人形机器人二次开发的朋友,后台发送“人形机器人”获取我的联系方式哦,也欢迎交流。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
腾讯云开发者
