
Map Reduce,reducer会自动排序吗?
提问于 2018-11-08 18:46:29
关于MapReduce编程环境的整体功能视图,我有一些不太清楚的地方。
考虑从一个(或多个)映射器中输出形式为(word,1)的1k个随机未排序单词。假设使用reducer,我想将它们都保存在一个巨大的排序文件中。它是如何工作的?我的意思是,归约器本身会自动对所有单词进行排序?reducer函数应该做什么?如果我只有一个内存和磁盘有限的减速器怎么办?

回答 1
Stack Overflow用户
发布于 2018-11-10 07:03:14
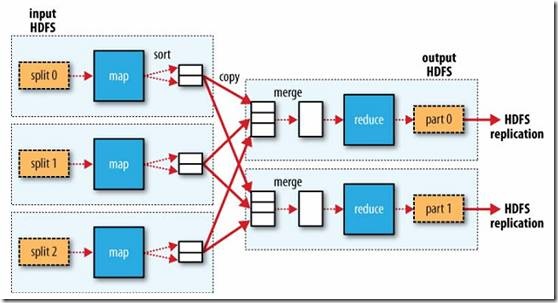
当reducer获得数据时,数据已经在映射端进行了排序。
过程是这样的
Map侧:
- 每个inputSplit都将由一个映射任务处理,映射输出的结果将临时放置在循环内存缓冲区 SHUFFLE 中。当缓冲区即将溢出(默认为缓冲区大小的80% )时,会在本地文件系统中创建一个溢出文件。
- 在写入磁盘之前,线程会先根据reduce任务的数量将数据分成相同数量的分区,即一个reduce任务对应一个分区的数据。以避免某些缩减任务被分配给大量数据,即使没有数据也是如此。实际上,每个分区中的数据都是排序的。如果此时设置了组合器,排序的结果将受到组合器operation.
- When的影响,本地任务输出最后一条记录,可能会有大量溢出文件,这些文件需要合并。在合并过程中,出于以下两个目的连续执行排序和组合操作: 1.最小化每次写入磁盘的数据量;2.在下一个复制阶段最小化网络传输的数据量。最后合并成一个经过分区和排序的文件。为了减少通过网络传输的数据量,您可以在此处压缩数据,只需将mapred.compress.map.out设置为true。
- 将数据从分区复制到相应的reduce任务。
减少侧:
1. 1.Reduce将从不同的map任务接收数据,并且从每个map发送的数据量是有序的。如果reduce端接受的数据量非常小,则将其直接存储在内存中。如果数据量超过缓冲区大小的特定比例,数据将被合并并写入磁盘。
- 随着溢出文件数量的增加,后台线程会将它们合并到一个更大、更有序的文件中。事实上,无论是Map端还是Reduce端,MapReduce反复执行排序合并operations.
- The合并过程会生成很多中间文件(写入磁盘),但MapReduce会将写入磁盘的数据尽量小,最后一次合并的结果不是写入磁盘,而是直接输入reduce函数。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53214246
复制











腾讯云开发者
