
在合并的文档中插入PieceInfo和ITextSharp
我有一个将几个PDF合并到一个PDF中的过程。效果很好。
在合并时,我希望在页面级别添加一个PieceInfo,以跟踪包含到该合并文件中的文档。
假设我按这个顺序有3个文档: Fester.pdf (2页)、Gomez.pdf (2页)和Lurch.pdf (1页)。合并之后,我将有5个页面,每个页面都有一个文件名为PieceInfo,该文件名来自。这样,如果我转到第4页,我就会知道该页面是从Gomez.pdf生成的。
在搜索过程中,我发现了这篇文章:使用iText库在pdf中插入隐藏摘要和我试图在我的过程中实现相同的内容。这个建议很好,但我不知道如何存储每页的信息。
这是我的代码:
public static byte[] MergeDocuments(DocumentCollection myCollection)
{
PdfImportedPage importedPage = null;
// Merged the document streams
using (MemoryStream stream = new MemoryStream())
{
// Create the iTextSharp document
iTextSharp.text.Document pdfDoc = new iTextSharp.text.Document();
// Create the PDF writer that listened to the document
PdfCopy pdfCopy = new PdfCopy(pdfDoc, stream);
if (pdfDoc != null && pdfCopy != null)
{
// Open the document and load content
pdfDoc.Open();
//Dictionary Entries
PdfName appName = new PdfName("MyKey");
PdfName dataName = new PdfName("Hash");
//Class to add and retrieve the PieceInfo data
DocumentPieceInfo dpi = new DocumentPieceInfo();
//Loop through my collection. The document class has the BinaryFile and FileName
foreach (Document doc in myCollection)
{
PdfReader reader = new PdfReader(doc.FileBinary);
if (reader != null)
{
int nPage = reader.NumberOfPages;
for (int n = 0; n < nPage; n++)
{
//Trying to add the PieceInfo
dpi.addPieceInfo(pdfCopy, appName, dataName, new PdfString(string.Format("Info Doc: {0}", doc.FileName)));
importedPage = pdfCopy.GetImportedPage(reader, n + 1);
pdfCopy.AddPage(importedPage);
}
// Close the reader
reader.Close();
}
}
if (pdfCopy != null)
pdfCopy.Close();
if (pdfDoc != null)
pdfDoc.Close();
byte[] arrOutput = stream.ToArray();
return arrOutput;
}
}
return null;
}以及对MKL解决方案的小改动,将输入更改为PDFCopy:
public void addPieceInfo(PdfCopy reader, PdfName app, PdfName name, PdfObject value)
{
//PdfDictionary catalog = reader.getCatalog();
PdfDictionary pieceInfo = reader.ExtraCatalog.GetAsDict(PIECE_INFO);
if (pieceInfo == null)
{
pieceInfo = new PdfDictionary();
reader.ExtraCatalog.Put(PIECE_INFO, pieceInfo);
}
PdfDictionary appData = pieceInfo.GetAsDict(app);
if (appData == null)
{
appData = new PdfDictionary();
pieceInfo.Put(app, appData);
}
PdfDictionary privateData = appData.GetAsDict(PRIVATE);
if (privateData == null)
{
privateData = new PdfDictionary();
appData.Put(PRIVATE, privateData);
}
appData.Put(LAST_MODIFIED, new PdfDate());
privateData.Put(name, value);
}上面的代码仅在最后一页中添加计件信息:(
页面PdfImportedPage对象有获得目录的方法吗?
如何在合并过程中包括每个页面级别的信息?在此之后,我如何从页面中获得pieceInfo?只是在书页上转圈?

回答 1
Stack Overflow用户
发布于 2016-01-06 01:42:07
请注意,/PieceInfo将在ISO-32000-2 (又名PDF2.0)中被废弃.作为另一种选择,您可以创建自己的键来添加自己的自定义数据。我在对如何检查pdf页面中是否存在巨型字符串问题的回答中解释了这一点。
您是在问页面PdfImportedPage对象有获得目录的方法吗?
这不是应该问的问题。如果您很好地学习我的回答,您会发现您需要访问页面字典。您可以将/PieceInfo条目(或自定义条目)添加到此页面字典中,然后再检索它。
public void createPdf(String filename) throws IOException, DocumentException {
PdfName marker = new PdfName("ITXT_PageMarker");
List<PdfReader> readers = new ArrayList<PdfReader>();
readers.add(new PdfReader(SRC1));
readers.add(new PdfReader(SRC2));
readers.add(new PdfReader(SRC3));
Document document = new Document();
PdfCopy copy = new PdfCopy(document, new FileOutputStream(filename));
document.open();
int counter = 0;
int n;
PdfImportedPage importedPage;
PdfDictionary pageDict;
for (PdfReader reader : readers) {
counter++;
n = reader.getNumberOfPages();
for (int p = 1; p <= n; p++) {
pageDict = reader.getPageN(p);
pageDict.put(marker, new PdfString(String.format("Page %s of document %s", p, counter)));
importedPage = copy.getImportedPage(reader, p);
copy.addPage(importedPage);
}
}
// close the document
document.close();
for (PdfReader reader : readers) {
reader.close();
}
}在本例中,我们在导入页面之前向页面字典添加了一个特殊的标记。因此,这个标记将被添加到合并的文档中:
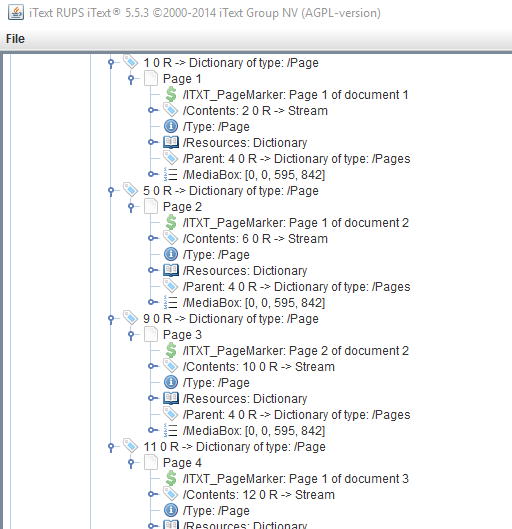
查看CustomPageDictKeyCreate示例,了解如何检索这些自定义标记:
public void check(String filename) throws IOException {
PdfReader reader = new PdfReader(filename);
PdfDictionary pagedict;
for (int i = 1; i < reader.getNumberOfPages(); i++) {
pagedict = reader.getPageN(i);
System.out.println(pagedict.get(new PdfName("ITXT_PageMarker")));
}
reader.close();
}请确保您的自定义密钥使用了第二个类名。iText已经为它的自定义二等键注册了ITXT前缀。这个前缀确保不同的公司不会为不同的目的使用相同的密钥。所有以ITXT开头的键都可以很容易地识别为iText组创建的密钥。ISO跟踪所有这些前缀以避免重复。在ISO中注册前缀是免费的。
https://stackoverflow.com/questions/34617914
复制









腾讯云开发者
