Yolo v3模型输出的角化澄清
我在keras中使用yolo v3模型,这个网络将我作为输出容器,形状如下:
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]所以我找到了这个链接
然后,我理解3个容器中每个容器的值255,我也理解有3个容器,因为有3个不同的图像缩放用于边界框的创建。
但是我不明白为什么在输出向量中有13 * 13个列表表示第一个缩放率,然后26 *26个列表表示第二个,然后是52 * 52个列表。
我无法找到一些很好的解释,所以我不能使用这个网络。如果有人知道我在哪里可以找到一些关于输出维度的信息,我会非常高兴。
编辑
是因为如果我把图像切成13段,考虑到每个部分都是物体的中心,我只能检测到13*13个物体吗?
回答 1
Stack Overflow用户
发布于 2019-07-19 07:15:11
YOLOv3有3个输出层。这个输出层在3个不同的尺度上预测盒坐标。YOLOv3还以这样的方式操作,将图像分割成单元格。根据您所看到的输出层,单元格的数量是不同的。
所以输出的数量是正确的,三个列表(因为有三个输出层)。您必须考虑YOLOv3是完全卷积的,这意味着输出层是宽度x高度x滤波器。看看第一个形状(1,13,13,255)。你知道255代表包围盒坐标&类别和信心,1代表批次大小。您现在不知道输出是conv2d,所以有问题的部分是13x13x13,这意味着您的输入图像将被划分为网格,对于网格中的每个单元将被预测为边界框坐标、类概率等。第二层操作在不同的尺度上,您的图像将被划分为网格26 x 26,第三层将您的图像划分为网格52 x 52,对于网格中的每个单元单元也将被预测为包围盒坐标。
它为什么有用?从实际的角度来看,想象一下那里有许多小鸽子集中在某个地方。当你只有一个13x13输出层时,所有这些鸽子都可以出现在一个网格中,所以你不会一个接一个地检测到它们。但是,如果你把你的图像分割成52x52个网格,你的细胞就会很小,更有可能检测到它们。对小对象的检测是对YOLOv2的投诉,所以这就是响应。
从更多的机器学习的角度。这是一个叫做特征金字塔的东西的实现。这一概念在Retina网络体系结构中得到推广。
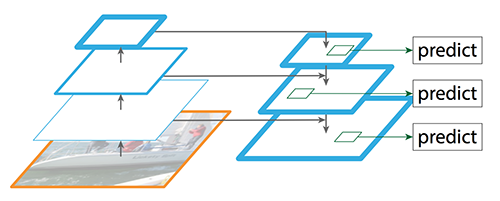
您可以处理输入图像,应用卷积、最大池等,直到某个时候,将此功能映射用作输出层的输入(在YOLOv3情况下为13x13)。比你的高级特征地图,这是用作输入的13x13层,并与特征映射与相应的大小(此特征映射将采取从网络的早期部分)。因此,现在您使用输出层的输入,升级的特性,沿着网络一路预处理,以及前面计算出来的特性。这就带来了更精确的结果。对于YOLOv3,您可以再一次将这些升级的特性与以前的特性连接起来,并将它们连接起来,并用作第三输出层的输入。
https://stackoverflow.com/questions/57112038
复制





相似问题
计量器上传错误记录
加载多个记录时出现撬动Gem问题
MarkLogic记录加载器问题
记录应用程序块不记录到文件
Launchctl加载后不工作/记录
领取专属 10元无门槛券
AI混元助手 在线答疑

洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
