前提条件
步骤1:创建 SQL 作业
1. 登录 流计算 Oceanus 控制台,进入某一工作空间后,单击左侧导航作业管理。
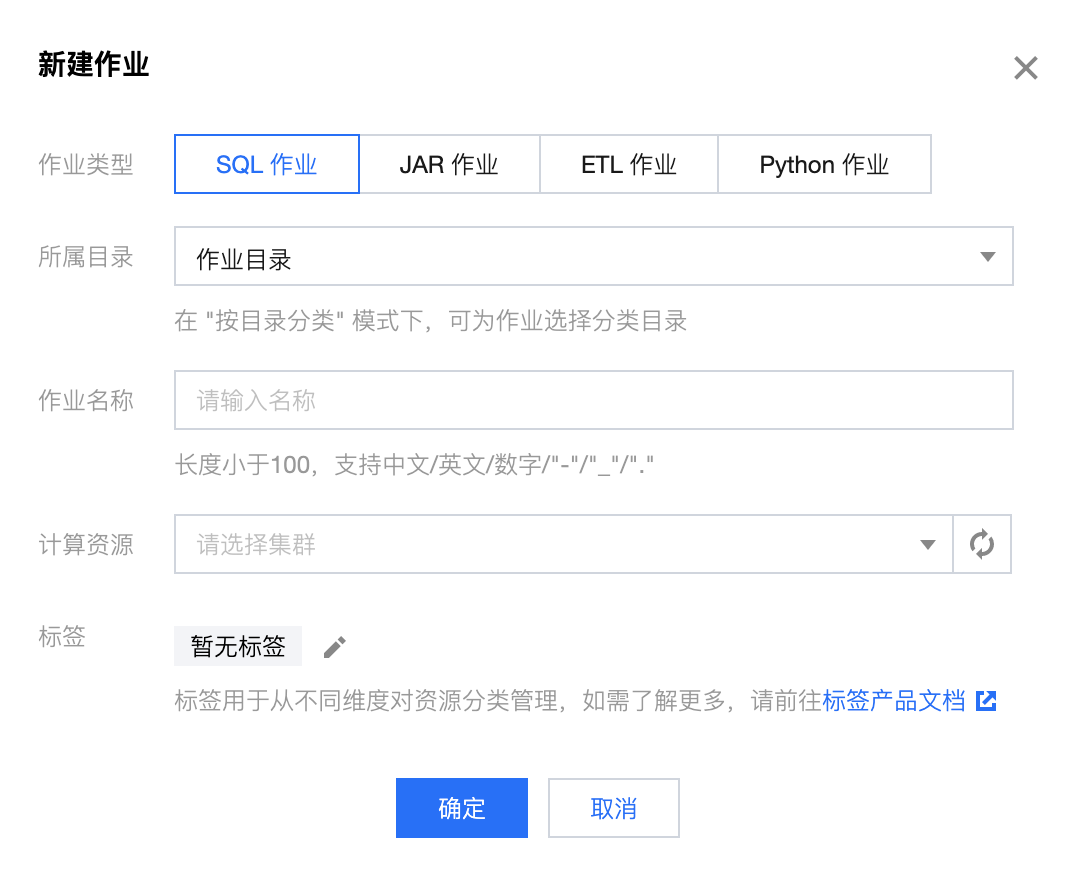
2. 进入作业管理页面,单击新建 > 新建作业,作业类型选中 SQL 作业,输入作业名称,并选择一个运行中的集群,新建的 SQL 作业将运行于此集群。
3. 单击确定后,即成功创建作业。
步骤2:流计算服务委托授权
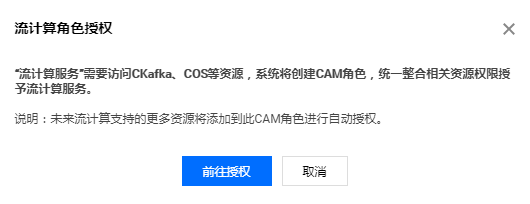
步骤3:编写 SQL 语句
授权完成后,可在开发调试的代码编辑框中输入 SQL 语句,可无需另外准备数据快速创建作业。示例语句具体执行的内容如下:
1. 使用内置 Connector “datagen” 创建数据源表 Data_Input,包含字段 age(BIGINT 型)、score(BIGINT 型)。datagen 是位于集群本地的数据源,可以不断生成随机数据。
2. 使用内置 Connector “blackhole” 创建数据结果表 Data_Output,包含字段 avg_age(BIGINT 型)、avg_score(BIGINT 型)。blackhole 是位于集群本地的数据目的,可以不断接收数据。
3. 将 Data_Intput 中的 age 和 score 取平均数之后存储于 Data_Output。
CREATE TABLE `Data_Input` ( --步骤 1 :创建数据源表(Source) Data_Inputage BIGINT,score BIGINT) WITH ('connector' = 'datagen','rows-per-second'='100', -- 每秒产生的数据条数'fields.age.kind'='random', -- 无界的随机数'fields.age.min'='1', -- 随机数的最小值'fields.age.max'='100', -- 随机数的最大值'fields.score.kind'='random', -- 无界的随机数'fields.score.min'='1', -- 随机数的最小值'fields.score.max'='1000' -- 随机数的最大值);CREATE TABLE `Data_Output` ( --步骤 2 :创建数据结果表(Sink) Data_Output`avg_age` BIGINT,`avg_score` BIGINT) WITH ('connector' = 'blackhole');INSERT INTO `Data_Output` --步骤 3 : 将数据源表(Source) Data_Intput 中的 age 和 score 取平均数之后存储于数据结果表(Sink) Data_OutputSELECT AVG(age), AVG(score) FROM `Data_Input`;
步骤4:设置作业参数
在作业参数中设置 Checkpoint 和算子默认并行度等参数的值,使用其他上下游数据则需选择相应的内置 Connector。
步骤5:发布运行 SQL 作业
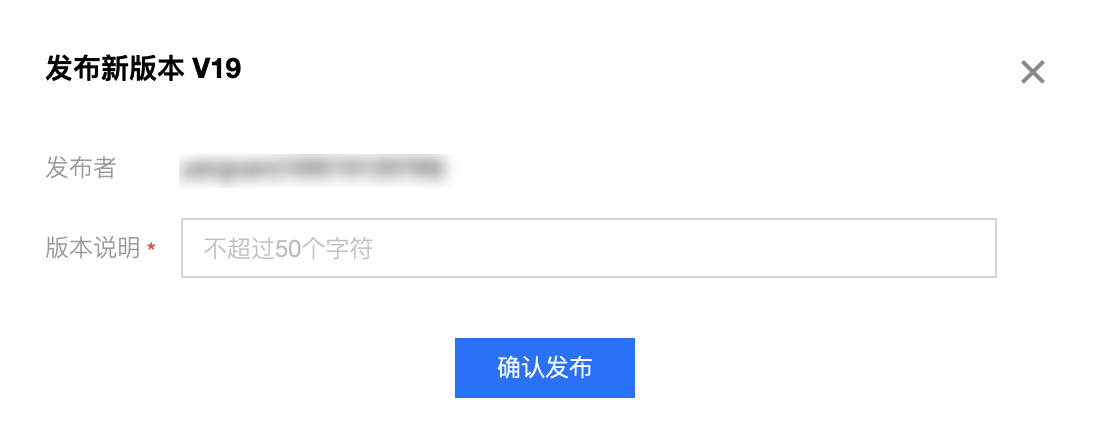
单击发布草稿,将进行作业运行检查,检查通过后将进入发布确认。发布将生成新的作业版本,版本号由系统自动生成。
发布草稿后,单击版本管理,可以查看并切换当前作业的不同版本。
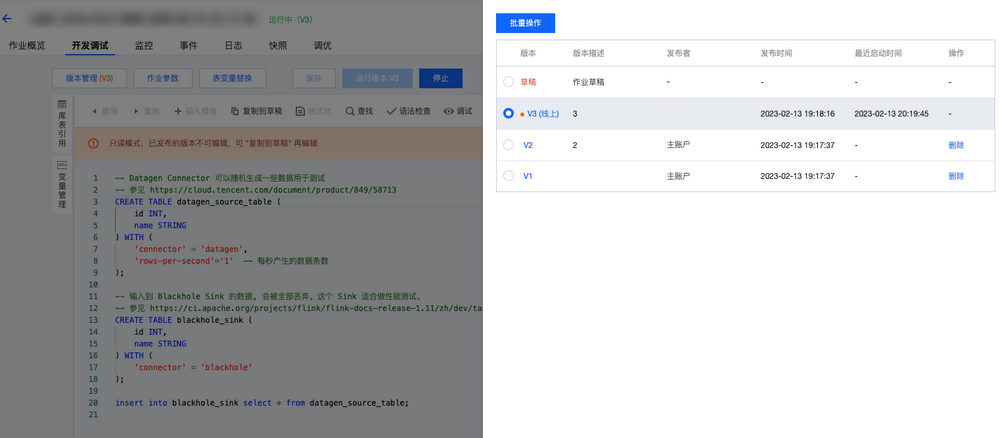
切换到期望运行的作业版本后,单击运行版本,再单击确认即可启动作业。
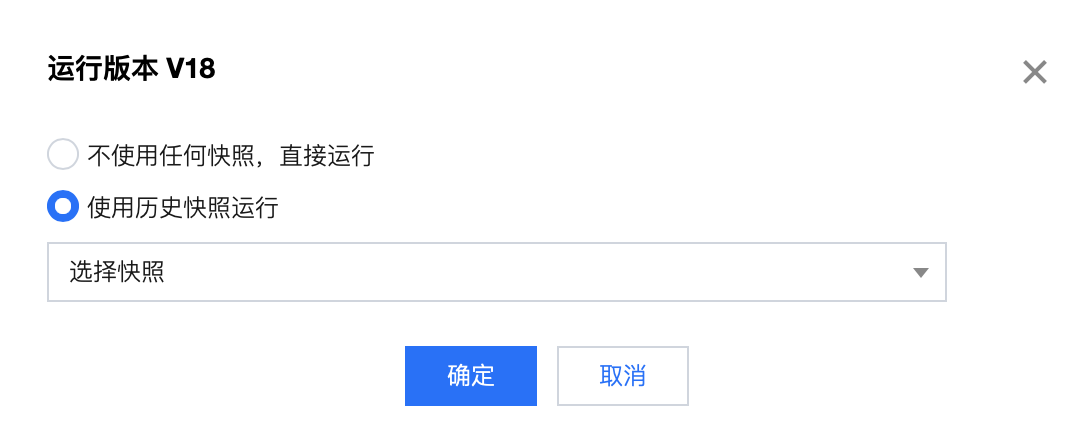
步骤6:查看作业运行情况
作业发布并启动运行后,将变为操作中的状态,成功启动后将变为运行中的状态。作业运行中时,可以通过监控、日志、Flink UI 等功能查看作业运行的情况。