用CTE优化时态表
我创建时态表是为了设置级别:
CREATE TABLE [#DesignLvl]
(
[DesignKey] INT,
[DesignLevel] INT
);
WITH RCTE AS
(
SELECT
*,
1 AS [Lvl]
FROM
[Design]
WHERE
[ParentDesignKey] IS NULL
UNION ALL
SELECT
[D].*,
[Lvl] + 1 AS [Lvl]
FROM
[dbo].[Design] AS [D]
INNER JOIN
[RCTE] AS [rc] ON [rc].[DesignKey] = [D].[ParentDesignKey]
)
INSERT INTO [#DesignLvl]
SELECT
[DesignKey], [Lvl]
FROM
[RCTE]创建之后,我在真正的大查询中使用了左联接,如下所示:
SELECT...
FROM..
LEFT JOIN [#DesignLvl] AS [dl] ON d.DesignKey = dl.DesignKey
WHERE ...查询工作正常,但性能下降,查询速度太慢。有办法优化这张桌子吗?
CTE的执行计划
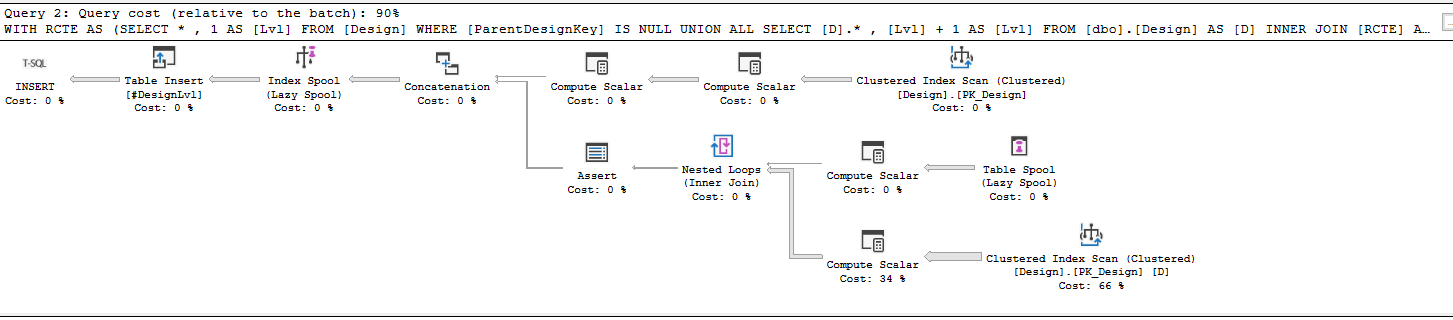
我尝试将聚集索引添加为:
CREATE TABLE [#DesignLvl]
(
[DesignKey] INT,
[DesignLevel] INT
);
CREATE CLUSTERED INDEX ix_DesignLvl
ON [#DesignLvl] ([DesignKey], [DesignLevel]);还试着:
CREATE TABLE [#DesignLvl]
( [DesignKey] INT INDEX IX1 CLUSTERED ,
[DesignLevel] INT INDEX IX2 NONCLUSTERED );但我得到了同样的结果,需要很长时间才能执行
回答 9
Stack Overflow用户
发布于 2019-03-06 16:03:05
性能可能更慢,因为在嵌套循环中访问dbo.Design表上的聚集索引。根据成本估算,数据库花费了66%的时间扫描该索引。翻个圈只会让事情变得更糟。
请参阅相关问题
考虑将dbo.Design上的索引更改为非聚集索引,或尝试使用非聚集索引创建另一个临时表,并将其用于递归查询:
CREATE TABLE [#DesignTemp]
(
ParentDesignKey INT,
DesignKey INT
);
-- Insert the data, then create the index.
INSERT INTO [#DesignTemp]
SELECT
ParentDesignKey,
DesignKey
FROM [dbo].[Design];
COMMIT;
-- Try this index, or create indexes for individual columns if the plan works better at high volumes.
CREATE NONCLUSTERED INDEX ix_DesignTemp1 ON [#DesignTemp] (ParentDesignKey, DesignKey);
CREATE TABLE [#DesignLvl]
(
[DesignKey] INT,
[DesignLevel] INT
);
WITH RCTE AS
(
SELECT
*,
1 AS [Lvl]
FROM
[DesignTemp]
WHERE
[ParentDesignKey] IS NULL
UNION ALL
SELECT
[D].*,
[Lvl] + 1 AS [Lvl]
FROM
[DesignTemp] AS [D]
INNER JOIN
[RCTE] AS [rc] ON [rc].[DesignKey] = [D].[ParentDesignKey]
)
INSERT INTO [#DesignLvl]
SELECT
[DesignKey], [Lvl]
FROM
[RCTE];Stack Overflow用户
发布于 2019-03-06 22:49:40
您的问题是不完整的,“查询很慢”,但是查询的哪一部分比较慢?
CTEQuery或LEFT JOIN in really big query
我认为需要大查询的脚本,以及详细信息,比如哪个表包含多少行、它们的数据类型等等。
抛出更多有关大查询的详细信息。
还请让我们知道是否有任何UDF涉及到连接条件。
你为什么要left join临时表?为什么不INNER JOIN?
分别测试性能或CTE和Big。
一旦在递归部分中使用了[D].[ParentDesignKey] is not null,
SELECT
[D].*,
[Lvl] + 1 AS [Lvl]
FROM
[dbo].[Design] AS [D]
INNER JOIN
[RCTE] AS [rc] ON [rc].[DesignKey] = [D].[ParentDesignKey]
and [D].[ParentDesignKey] is not null注意: CTE中的只使用那些需要的列。
如果可以的话,Pre- Calculate [Lvl],因为Recursive CTE的性能特别差,涉及到很多记录。
平均每个CTE查询将处理多少行?
如果临时表的容纳量超过100 rows,则可以在其上创建聚集索引,
CREATE CLUSTERED INDEX ix_DesignLvl
ON [#DesignLvl] ([DesignKey], [DesignLevel]);如果在联接条件下不使用[DesignLevel],则从索引中删除。
同时,还揭示了表[dbo].[Design]的索引以及DesignKey和ParentDesignKey的少量数据。
获得Index Scan有几个原因,其中之一就是Selectivity of Key。
因此,一个DesignKey可以有多少行,一个ParentDesignKey可以有多少行?
因此,根据上面的答案,Create Composite Clustered Index在表[dbo].[Design]的两个键上
因此,考虑到我的回答是不完整的,我会相应地更新它。
Stack Overflow用户
发布于 2019-03-04 11:52:20
根据我在这篇文章上发布的测试,基于集合的循环可以比递归的CTE提高性能。
DECLARE @DesignLevel int = 0;
INSERT INTO [#DesignLvl]
SELECT [DesignKey], 1
FROM [RCTE];
WHILE @@ROWCOUNT > 0
BEGIN
SET @DesignLevel += 1;
INSERT INTO [#DesignLvl]
SELECT [D].[DesignKey], dl.DesignLevel
FROM [dbo].[Design] AS [D]
JOIN [#DesignLvl] AS [dl] ON [dl].[DesignKey] = [D].[ParentDesignKey]
WHERE dl.DesignLevel = @DesignLevel;
END;https://stackoverflow.com/questions/54989684
复制![[PostgreSQL] - CTE](https://ask.qcloudimg.com/http-save/yehe-2343993/3a3d88af36f9fc1c8c54e0ccc73d4556.png)





相似问题
CTE表优化
优化CTE查询
用CTE语句创建表
优化CTE查询
如何优化时态SQL Server表的性能
领取专属 10元无门槛券
AI混元助手 在线答疑

洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
