腾讯云
开发者社区
文档
建议反馈
控制台
登录/注册
首页
学习
活动
专区
工具
TVP
最新优惠活动
文章/答案/技术大牛
搜索
搜索
关闭
发布
精选内容/技术社群/优惠产品,
尽在小程序
立即前往
首页
学习
活动
专区
工具
TVP
最新优惠活动
返回腾讯云官网
🔎何时感觉自己真正踏入编程之门?
🌱从代码菜鸟到编程高手,好似瞬间
立即分享
🔥EdgeOne一站式玩转网站加速与防护实战营
🎁鹅厂大牛带你实战无忧,学习赢定制龙年公仔 !
立即报名
21天技术创作挑战赛 | 年中回顾特别季
🌟连更/新人/好文等玩法,参与瓜分苹果耳机、键盘等万元礼品池!
立即参加
腾讯混元大模型AIGC系列产品技术有奖征文
🔥参与赢取京东卡、音响、键盘、资源包等豪礼!
立即参加
精选文章
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
管理
架构设计
架构
跨平台
设计
系统
什么才是真正的架构设计?
就算你是一个打螺丝的,你依然每天游走在这个系统的“架构”里,在里面修修补补,你得从“架构”的全局角度去审视你每天忙碌的价值和意义。经历的项目多了, 在进入新的团队,有些老项目,在了解业务背景后, 你头脑中可能已经闪现出一张“架构”了,然后你去看代码的时候大喜:“果然如此”, 这种“架构”背后的代码让你读起来神清气爽;也有些项目,你在读代码的时候发现和你脑海中闪现的“架构”不一样,这时你只能骂咧咧的合上笔记本,心想怎么会“架构”出来这种坨坨,喝杯咖啡之后,继续来啃里面的“屎山”。
腾讯云开发者
2024-09-19
196
0
腾讯技术创作特训营S9
GPTS全网刷屏!定制增长速度指数增长
GPT-4 Turbo是GPT-4的升级版,具有更强的能力。其知识库已经更新到2023年4月,同时具有更低的成本和更高的性能。
算法一只狗
2024-09-23
80
0
jvm
腾讯技术创作特训营S9
深入浅出JVM(一)之Hotspot虚拟机中的对象
对象的创建可以分为五个步骤:检查类加载,分配内存,初始化零值,设置对象头,执行实例构造器<init>
菜菜的后端私房菜
2024-09-24
33
0
腾讯技术创作特训营S9
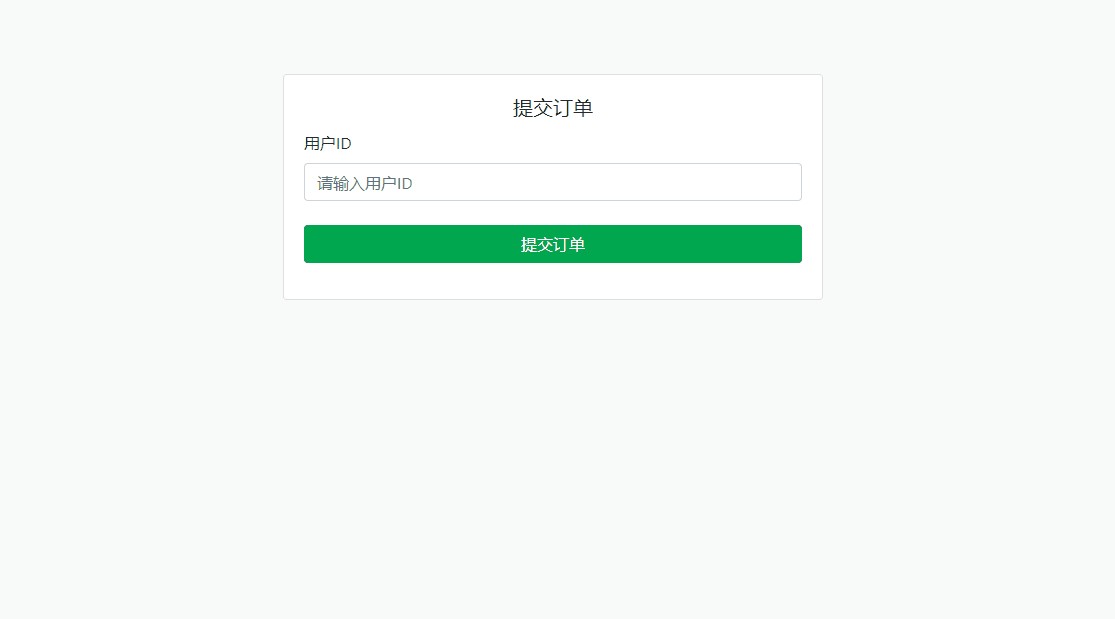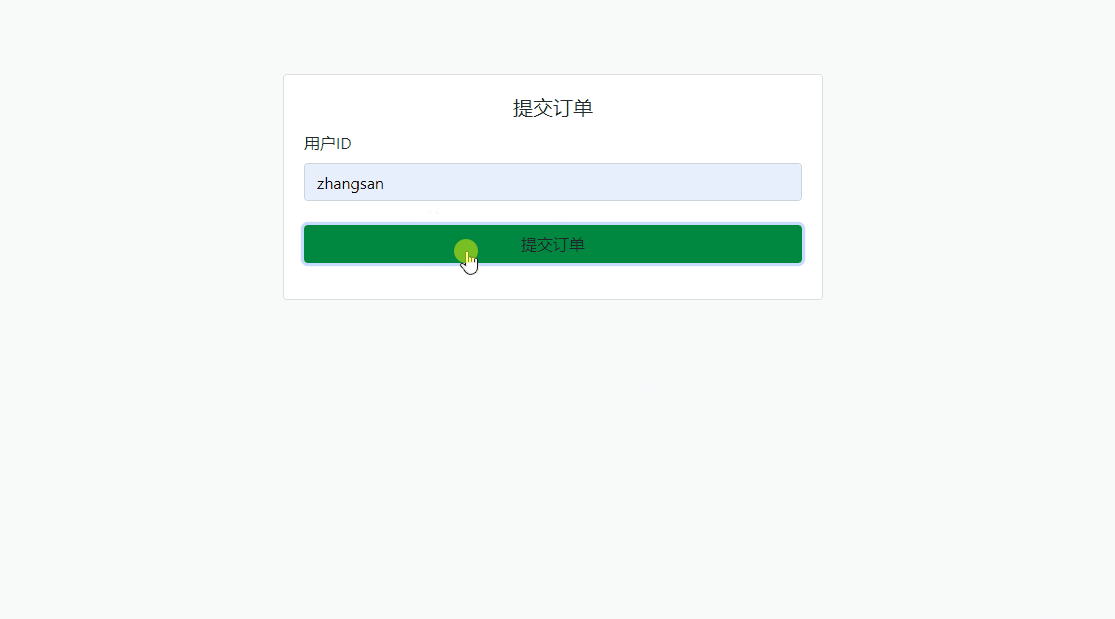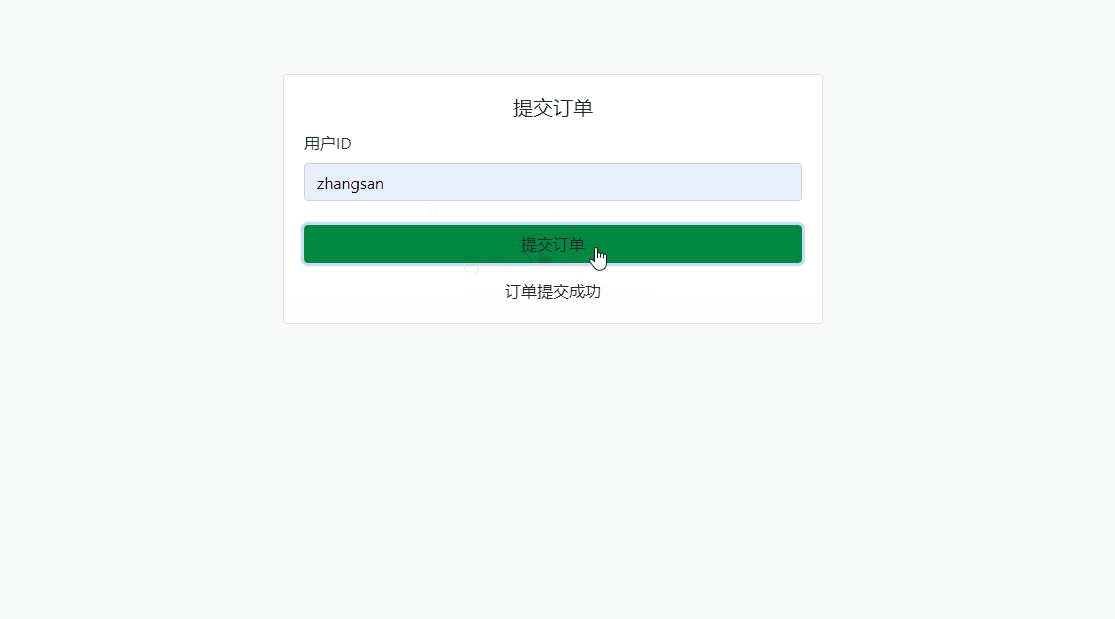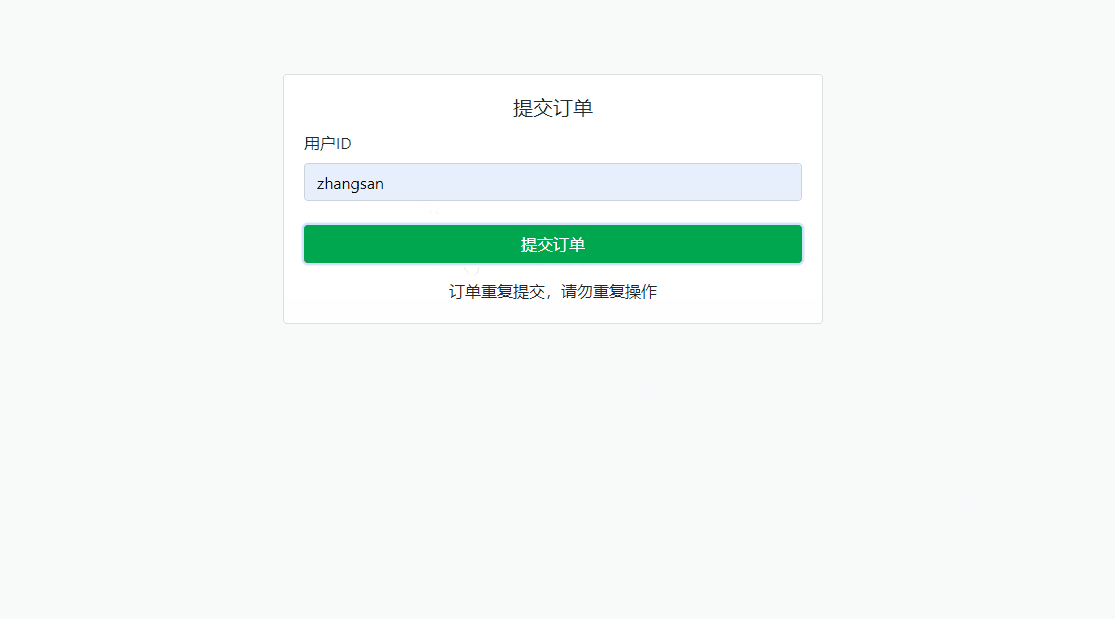
大厂必问 · 如何防止订单重复?
在电商系统或任何涉及订单操作的场景中,用户多次点击“提交订单”按钮可能会导致重复订单提交,造成数据冗余和业务逻辑错误,导致库存问题、用户体验下降或财务上的错误。因此,防止订单重复提交是一个常见需求。
不惑
2024-09-24
95
0
对象
函数
响应式
vue3
变量
尊嘟假嘟?在Vue3.5中解构props不会丢失响应式
在Vue3.5版本中响应式 Props 解构终于正式转正了,这个功能之前一直是试验性的。这篇文章来带你搞清楚,一个String类型的props经过解构后明明应该是一个常量了,为什么还没丢失响应式呢?本文中使用的Vue版本为欧阳写文章时的最新版Vue3.5.5
前端欧阳
2024-09-20
102
0
腾讯技术创作特训营S9
大模型安装部署、测试、接入SpringCloud应用体系
大模型通常指的是具有庞大数据的神经网络模型,如OpenAI的GPT系列、Google的BERT等。这些模型对计算资源的需求极高,因此通常部署在云服务器或高性能计算集群上。安装部署大模型时,需要考虑模型的兼容性、计算资源的需求、存储空间的分配以及模型的优化策略。
后台技术汇
2024-09-22
84
0
工具
开源
布局
插件
程序员
5 款程序员画图神器,全免费!
在程序员的日常工作中,有两大难题:一曰写文档,二曰画图。此前我们策划了多篇技术文档写作指南文章和架构画图技巧文章,有效地帮助到了广大开发者朋友。
腾讯云开发者
2024-09-12
279
1
腾讯技术创作特训营S9
OpenAI发布的o1大模型原理初探
OpenAI终于发布新的模型,这个模型被称为o1。ChatGPT官网已经可以看到有两个模型,一个是o1-preview,另一个是o1-mini。
算法一只狗
2024-09-20
266
1
知识图谱
腾讯技术创作特训营S9
知识图谱嵌入与因果推理的结合
知识图谱通过节点(实体)和边(关系)来表示现实世界中的信息,但如何将这些信息转化为可进行推理和决策的形式,仍然是一个挑战。
数字扫地僧
2024-09-22
219
0
腾讯技术创作特训营S9
面试官:【int i = 6; i += i - 1; 】i 等于什么?
表达式解析:i += i - 1; 这一行等价于 i = i + (i - 1);。
不惑
2024-09-20
208
1
精选文章
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
什么才是真正的架构设计?
就算你是一个打螺丝的,你依然每天游走在这个系统的“架构”里,在里面修修补补,你得从“架构”的全局角度去审视你每天忙碌的价值和意义。经历的项目多了, 在进入新的团队,有些老项目,在了解业务背景后, 你头脑中可能已经闪现出一张“架构”了,然后你去看代码的时候大喜:“果然如此”, 这种“架构”背后的代码让你读起来神清气爽;也有些项目,你在读代码的时候发现和你脑海中闪现的“架构”不一样,这时你只能骂咧咧的合上笔记本,心想怎么会“架构”出来这种坨坨,喝杯咖啡之后,继续来啃里面的“屎山”。
腾讯云开发者
2024-09-19
GPTS全网刷屏!定制增长速度指数增长
GPT-4 Turbo是GPT-4的升级版,具有更强的能力。其知识库已经更新到2023年4月,同时具有更低的成本和更高的性能。
算法一只狗
2024-09-23
深入浅出JVM(一)之Hotspot虚拟机中的对象
对象的创建可以分为五个步骤:检查类加载,分配内存,初始化零值,设置对象头,执行实例构造器<init>
菜菜的后端私房菜
2024-09-24
大厂必问 · 如何防止订单重复?
在电商系统或任何涉及订单操作的场景中,用户多次点击“提交订单”按钮可能会导致重复订单提交,造成数据冗余和业务逻辑错误,导致库存问题、用户体验下降或财务上的错误。因此,防止订单重复提交是一个常见需求。
不惑
2024-09-24
尊嘟假嘟?在Vue3.5中解构props不会丢失响应式
在Vue3.5版本中响应式 Props 解构终于正式转正了,这个功能之前一直是试验性的。这篇文章来带你搞清楚,一个String类型的props经过解构后明明应该是一个常量了,为什么还没丢失响应式呢?本文中使用的Vue版本为欧阳写文章时的最新版Vue3.5.5
前端欧阳
2024-09-20
大模型安装部署、测试、接入SpringCloud应用体系
大模型通常指的是具有庞大数据的神经网络模型,如OpenAI的GPT系列、Google的BERT等。这些模型对计算资源的需求极高,因此通常部署在云服务器或高性能计算集群上。安装部署大模型时,需要考虑模型的兼容性、计算资源的需求、存储空间的分配以及模型的优化策略。
后台技术汇
2024-09-22
5 款程序员画图神器,全免费!
在程序员的日常工作中,有两大难题:一曰写文档,二曰画图。此前我们策划了多篇技术文档写作指南文章和架构画图技巧文章,有效地帮助到了广大开发者朋友。
腾讯云开发者
2024-09-12
OpenAI发布的o1大模型原理初探
OpenAI终于发布新的模型,这个模型被称为o1。ChatGPT官网已经可以看到有两个模型,一个是o1-preview,另一个是o1-mini。
算法一只狗
2024-09-20
知识图谱嵌入与因果推理的结合
知识图谱通过节点(实体)和边(关系)来表示现实世界中的信息,但如何将这些信息转化为可进行推理和决策的形式,仍然是一个挑战。
数字扫地僧
2024-09-22
面试官:【int i = 6; i += i - 1; 】i 等于什么?
表达式解析:i += i - 1; 这一行等价于 i = i + (i - 1);。
不惑
2024-09-20
晚上好!
欢迎来到腾讯云开发者社区
登录
沙龙日历
全部 >
加入讨论
的问答专区 >
原创作者热度排行榜
更多 >
问题归档
专栏文章
快讯文章归档
关键词归档
开发者手册归档
开发者手册 Section 归档
领券