PySpark 任务数据倾斜导致 python+jvm 内存占用超过 K8s request 内出现 OOMkilled?
问题描述:PySpark 任务执行时,executor 日志出现“k8s执行OOMKiiled”,使用内存超过 k8s 限制的内存。
原因分析:K8s 申请的内存是根据 Spark executor 内存乘以 memoryOerheadFactor计算出来的,如果 Python 处理的数据有倾斜,或单条数据过大,可能导致使用内存超过 K8s 分配的内存。
解决方案:添加任务参数 spark.kubernetes.memoryOverheadFactor=0.8,默认值0.4。

Insert into/overwrite 后如何自动添加 repartition 命令对数据做分区以减少小文件数量?
解决方案:开启自动重分区,配置如下参数:
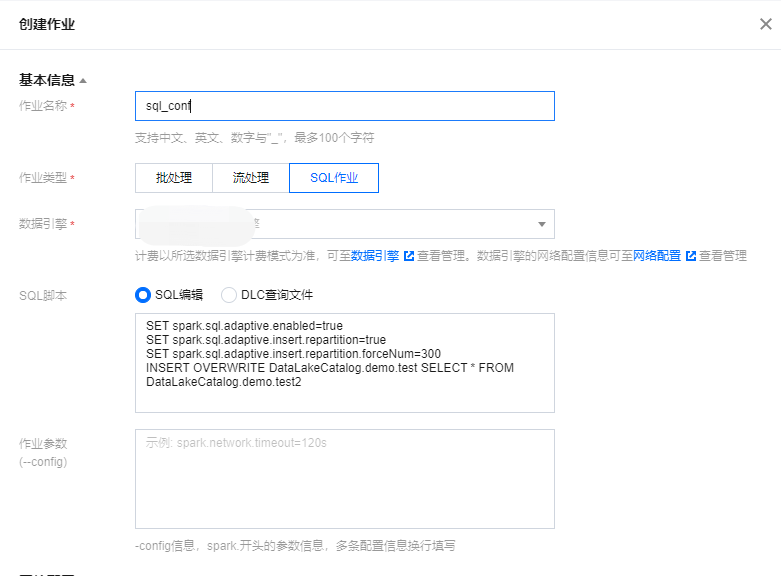
spark.sql.adaptive.enabled:truespark.sql.adaptive.insert.repartition:truespark.sql.adaptive.insert.repartition.forceNum:300 (指定了具体需要分区的值)
操作步骤:
程序内配置到 SparkConf:
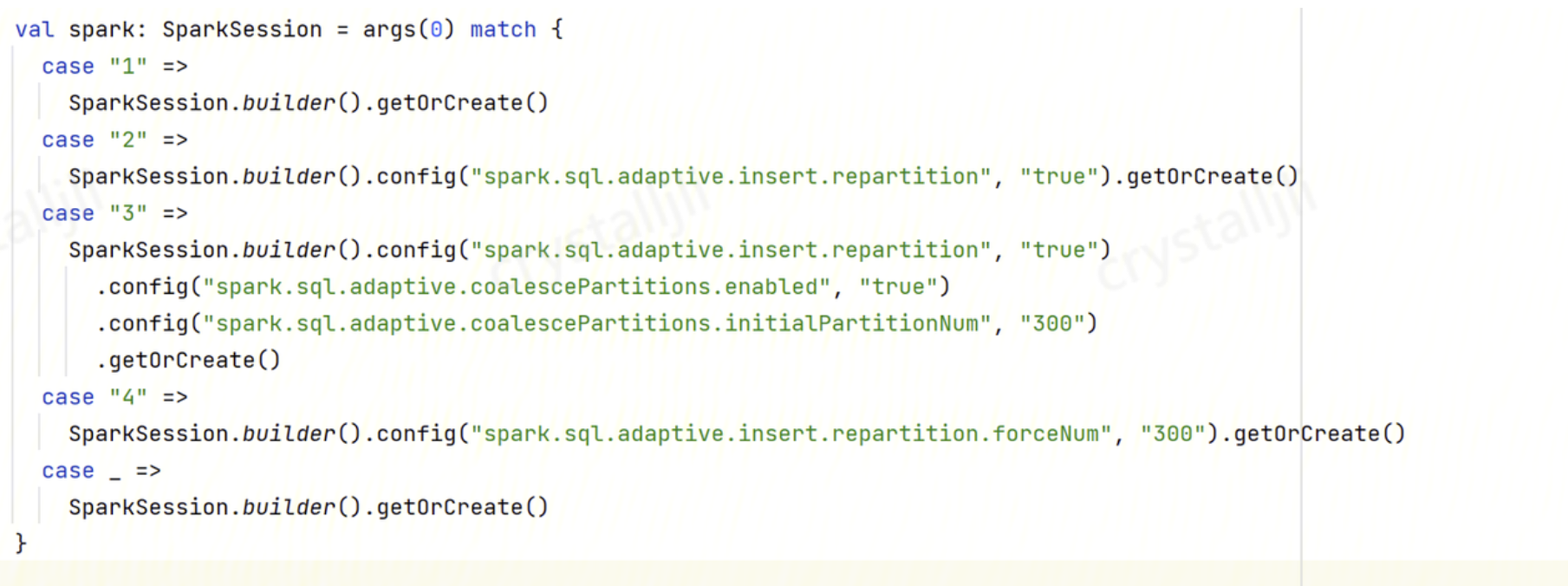
程序内设置 SQL SET:
PySpark 任务高并发写 COS 存储桶时返回503错误?
问题描述:PySpark 任务高并发写 COS 存储桶时,executor 有非常多的 COS 返回503错误。
问题原因:Spark 任务写 COS 时的并行核数为 *fs.cosn.trsf.fs.ofs.data.transfer.thread.count 指定 。例如,4096核下不做调优,默认并发度为4096*32=131072,导致 COS 瓶颈。
解决方案:
1. COS 新建一个元数据加速桶,避免 spark 任务写时的 list 和 rename 超频。
2. 通过 COS 调整元数据加速桶带宽限制。
3. 任务添加以下参数降低高并行度时对 COS 访问压力过大。
fs.cosn.trsf.fs.ofs.data.transfer.thread.count=8fs.cosn.trsf.fs.ofs.block.max.file.cache.mb=0spark.hadoop.fs.cosn.trsf.fs.ofs.data.transfer.thread.count=8spark.hadoop.fs.cosn.trsf.fs.ofs.block.max.file.cache.mb=0
常用数据治理 SQL 有哪些?
关闭库治理 SQL
ALTER DATABASE DataLakeCatalog.demo_dbSETDBPROPERTIES ('dlc.ao.data.govern.inherit' = 'none','dlc.ao.merge.data.enable' = 'disable','dlc.ao.expired.snapshots.enable' = 'disable','dlc.ao.remove.orphan.enable' = 'disable','dlc.ao.merge.manifests.enable' = 'disable')
开启库治理 SQL
ALTER DATABASE DataLakeCatalog.db_nameSETDBPROPERTIES ('dlc.ao.data.govern.inherit' = 'none','dlc.ao.merge.data.enable' = 'enable','dlc.ao.merge.data.engine' = 'bda-sinker','dlc.ao.merge.data.min-input-files' = '10','dlc.ao.merge.data.target-file-size-bytes' = '536870912','dlc.ao.merge.data.interval-min' = '90','dlc.ao.expired.snapshots.enable' = 'enable','dlc.ao.expired.snapshots.engine' = 'bda-sinker','dlc.ao.expired.snapshots.retain-last' = '5','dlc.ao.expired.snapshots.before-days' = '2','dlc.ao.expired.snapshots.max-concurrent-deletes' = '4','dlc.ao.expired.snapshots.interval-min' = '150','dlc.ao.remove.orphan.enable' = 'enable','dlc.ao.remove.orphan.engine' = 'bda-sinker','dlc.ao.remove.orphan.before-days' = '3','dlc.ao.remove.orphan.max-concurrent-deletes' = '4','dlc.ao.remove.orphan.interval-min' = '600','dlc.ao.merge.manifests.enable' = 'enable','dlc.ao.merge.manifests.engine' = 'bda-sinker','dlc.ao.merge.manifests.interval-min' = '1440')
关闭表治理 SQL
ALTER TABLE`DataLakeCatalog`.`db_name`.`tb_name`SETTBLPROPERTIES ('dlc.ao.data.govern.inherit' = 'none','dlc.ao.merge.data.enable' = 'disable','dlc.ao.expired.snapshots.enable' = 'disable','dlc.ao.remove.orphan.enable' = 'disable','dlc.ao.merge.manifests.enable' = 'disable')
开启继承库治理 SQL
ALTER TABLE `DataLakeCatalog`.`db_name`.`tb_name`SET TBLPROPERTIES ('dlc.ao.data.govern.inherit' = 'default')
开启表治理 SQL
ALTER TABLE`DataLakeCatalog`.`db_name`.`tb_name`SETTBLPROPERTIES ('dlc.ao.data.govern.inherit' = 'none','dlc.ao.merge.data.enable' = 'enable','dlc.ao.merge.data.engine' = 'bda-sinker','dlc.ao.merge.data.min-input-files' = '10','dlc.ao.merge.data.target-file-size-bytes' = '536870912','dlc.ao.merge.data.interval-min' = '90','dlc.ao.expired.snapshots.enable' = 'enable','dlc.ao.expired.snapshots.engine' = 'bda-sinker','dlc.ao.expired.snapshots.retain-last' = '5','dlc.ao.expired.snapshots.before-days' = '2','dlc.ao.expired.snapshots.max-concurrent-deletes' = '4','dlc.ao.expired.snapshots.interval-min' = '150','dlc.ao.remove.orphan.enable' = 'enable','dlc.ao.remove.orphan.engine' = 'bda-sinker','dlc.ao.remove.orphan.before-days' = '3','dlc.ao.remove.orphan.max-concurrent-deletes' = '4','dlc.ao.remove.orphan.interval-min' = '600','dlc.ao.merge.manifests.enable' = 'enable','dlc.ao.merge.manifests.engine' = 'bda-sinker','dlc.ao.merge.manifests.interval-min' = '1440')
不指定 Where 条件全表合并 SQL
CALL `DataLakeCatalog`.`system`.`rewrite_data_files`(`table` => 'tb_name',`options` => map('min-input-files','10','target-file-size-bytes','536870912','delete-file-threshold','1','max-concurrent-file-group-rewrites','20'))
支持 Where 条件增量合并 SQL
CALL `DataLakeCatalog`.`system`.`rewrite_data_files`(`table` => 'tb_name',`options` => map('min-input-files','10','target-file-size-bytes','536870912','delete-file-threshold','1','max-concurrent-file-group-rewrites','20'),`where` => 'field_date > "2022-01-01" and field_date <= "2023-01-01"')
快照过期 SQL
CALL `DataLakeCatalog`.`system`.`expire_snapshots`(`table` => 'tb_name',older_than => TIMESTAMP '2023-02-28 16:06:35.000',retain_last => 1,max_concurrent_deletes => 4,stream_results => true)
如何查看 SQL 执行计划和 SQL 执行的日志?
查看SQL执行日志:
1. 数据探索执行 SQL,运行结果展示 SQL 执行日志。
2. DLC 控制台 > 数据运维 > 历史运行可以查看 SQL 执行日志。
CAST 未自动转换精度导致数据写入失败?
问题描述:hive sql 迁移 spark sql 时,报错 Cannot safely cast 'class_type': string to bigint。
问题定位:Spark 3.0.0 开始,Spark SQL 在处理类型转换时有 3 种安全策略:
ANSI:不允许 Spark 进行某些不合理的类型转换,如:string 转换成 timestamp。
LEGACY :允许 Spark 进行类型强制转换,只要它是有效的 Cast 操作。
STRICT :不允许 Spark 进行任何可能有损精度的转换。默认策略是 ANSI。
解决方案:修改策略为 LEGACY,设置 spark.sql.storeAssignmentPolicy=LEGACY。
QUERY_PROGRESS_UPDATE_ERROR(code=3060): Failed to update statement progress 错误
问题描述:数据探索中提交 spark sql 任务,执行过程中,提示 Failed to Update statement progress 错误。
问题定位:当有多个 Spark SQL 任务提交时,需要持续的异步跟进每个 SQL 的执行进度,这里异步处理的队列有限制,默认值是100(2024.1.14以后的版本更新为300)。所以当某个任务被提交后一直没有执行完成,而后续新增的任务超过了队列上限会导致该错误。如果您出现这种错误,一般表示该 SQL 任务可能是个长尾任务,需要关注对其他任务资源占用是否合理。
解决方案:可以在引擎上调整配置 livy.rsc.retained-statements,调整到大于默认值的值。注意调整后引擎会重启。具体值可以根据任务的并发量来设置,该参数对集群影响较小,同时提交的 SQL 并发量达到100-200/min时,该参数调整到6000也实测没有影响。



