hadoop之为什么不能一直格式化namenode

格式化NameNode会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据,所以,格式化NameNode前,先关闭掉NameNode和DataNode,然后一定要删除data数据和log日志。最后再进行格式化。
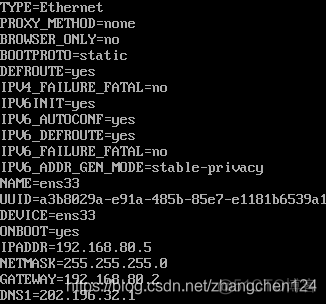
在hadoop-2.9.2/data/tmp/dfs/name/current/VERSION中可查到NameNode标识id

在hadoop-2.9.2/data/tmp/dfs/data/current/VERSION中可查到DataNode标识id

可以看出它们的集群Id是要保持一致的。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2020-03-01 ,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
暂无评论
推荐阅读
编辑精选文章
换一批







推荐阅读
相关推荐
hadoop伪分布式之启动HDFS并运行MR程序(WordCount)
更多 >
社区富文本编辑器全新改版!诚邀体验~
全新交互,全新视觉,新增快捷键、悬浮工具栏、高亮块等功能并同时优化现有功能,全面提升创作效率和体验
腾讯云开发者
