
将星火DataFrame列中的JSON数据转换为表格格式
提问于 2021-04-08 16:35:58
我得到了从一个多行JSON文件加载的spark dataframe。
列(data)模式之一如下:
root
|-- data: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- f: struct (nullable = true)
| | | |-- 0: struct (nullable = true)
| | | | |-- v: double (nullable = true)
| | |-- ts: string (nullable = true)和抽样数据:
array
0: {"f": {"0": {"v": 25.08}}, "ts": "2021-01-11T05:59:00.170Z"}
1: {"f": {"0": {"v": 25.92}}, "ts": "2021-03-22T03:29:00.170Z"}
2: {"f": {"0": {"v": 25.94}}, "ts": "2021-03-22T03:39:00.173Z"}
3: {"f": {"0": {"v": 25.95}}, "ts": "2021-03-22T03:49:00.170Z"}
4: {"f": {"0": {"v": 25.99}}, "ts": "2021-03-22T04:00:00.173Z"}我只想提取T和v。
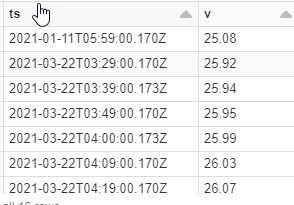
实例结果

回答 1
Stack Overflow用户
回答已采纳
发布于 2021-04-09 00:12:40
可以将结构数组分解为多个行,并选择所需的struct元素:
import pyspark.sql.functions as F
df2 = df.select(F.explode('data').alias('data')).select('data.ts', 'data.f.0.v')
df2.show(truncate=False)
+------------------------+-----+
|ts |v |
+------------------------+-----+
|2021-01-11T05:59:00.170Z|25.08|
|2021-03-22T03:29:00.170Z|25.92|
|2021-03-22T03:39:00.173Z|25.94|
|2021-03-22T03:49:00.170Z|25.95|
|2021-03-22T04:00:00.173Z|25.99|
+------------------------+-----+页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67013548
复制相关文章




点击加载更多


腾讯云开发者
