
如何从Pandas dataframe中删除一行中的“A”列等于另一行中的“B”列的行?
提问于 2021-10-16 10:44:05
我正试图从重复的行中清理我的熊猫数据帧。我知道如何删除列值相同的行,但如果(第1行的A列等于第2行的B列,第1行的B等于第2行的A列等于第2行的A列),则如何删除行。我希望这不是太混乱。我在下面添加了一个表格的例子。我认为第2行和第3行是重复的。我怎么用熊猫把它们移走呢?
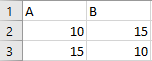
编辑:
重复的行不一定就在彼此之间。我只需要保留其中的一行(具体而言,哪一行不重要)。

回答 1
Stack Overflow用户
回答已采纳
发布于 2021-10-16 11:00:12
使用np.sort使每行按顺序具有相同的值
import pandas as pd
import numpy as np
# toy data
df = pd.DataFrame(data=[[10, 15], [15, 10]], columns=["A", "B"])
# find duplicates rows
duplicated = pd.DataFrame(np.sort(df[["A", "B"]], axis=1), index=df.index).duplicated()
# filter out
res = df[duplicated]
print(res)输出
A B
1 15 10另一种方法是使用frozenset将每一行转换为一个可选的集合,而顺序并不重要。
# find duplicates rows
duplicated = df[["A", "B"]].apply(frozenset, axis=1).duplicated()
# filter out
res = df[duplicated]
print(res)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69598599
复制相关文章









腾讯云开发者
