R情节中的传说
R情节中的传说
提问于 2012-03-02 05:56:47
我想把图上的图例分裂成2,这样前3个元素和第4个元素之间有一个大约1线高的间隙。最初,我只是尝试在第一个元素之前添加一个换行符:
legend("topright",col=1,lty=1:3,lwd=1,legend=c("leg1","leg2","\nleg3"), bty="n")但这似乎增加了所有元素之间的差距(这是记录在案的行为吗?)
然后,我使用了两个不同的传说,将边框设置为"n",并使用lines()重建边框(顺便说一句,是否有一种方法来抑制图例中的一个边框?);虽然这是可行的,但它确实需要对inset的值进行大量的尝试和错误。
inset在legend()中的默认值是c(0,0),但在对legend()的初始调用中,这些值显然会根据图例元素中文本的长度进行调整。根据?legend,legend()调用的值包括
长度(图例)的数字向量,给出图例文本的x和y坐标。
无论如何,这是否可以转换为第二个调用的inset的适当值,以便这两个传说的元素排列起来?
回答 1
Stack Overflow用户
回答已采纳
发布于 2012-03-02 06:30:32
只需在您希望空间所在的参数中指定NAs即可。您需要将所有的传奇参数作为向量给出。
set.seed(2)
plot(0:10, rnorm(11), col = sample(c("green", "blue"), 11, replace = TRUE),
pch = sample(c(3, 19), 11, replace = TRUE), xlim = c(0, 12))
legend("topright", pch = c(3, 19, NA, 3, 19),
col = c("green", "green", NA, "blue", "blue"),
legend = c("green cross", "green dot", NA, "blue cross", "blue dot"))
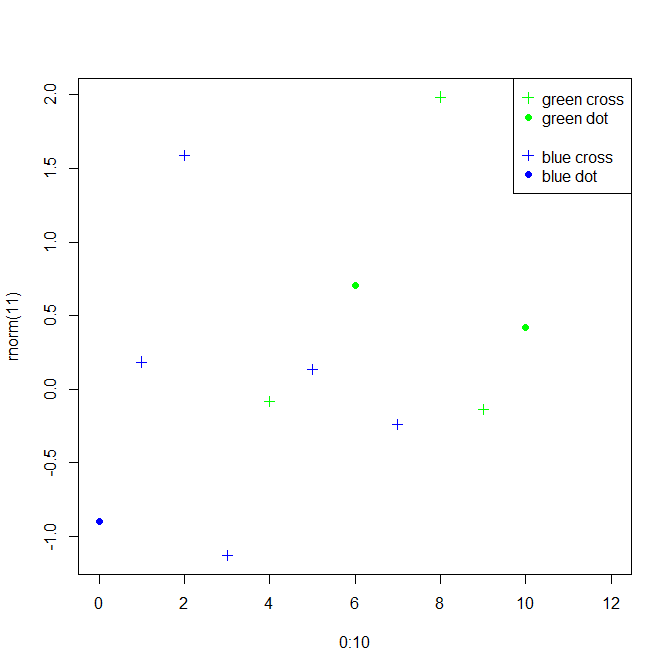
或者,如果您想要对legend()进行2次调用以获得更精细的控件,请在参数中指定trace=TRUE,它将返回所需的x和y坐标。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/9534481
复制












相似问题
R中的高级传说:情节
传说在R情节的后面
R‘牛仔情节’巧妙地制作出有共同传说和独特传说的网格情节。
隐藏的情节传说
不同传说在多个传说情节中的位置
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
