
如何将Cython导入IPython笔记本并编译它
我正在使用IPython和Cython。
我正在外部文本编辑器中编辑模块中的Cython函数。
我希望导入这些模块并在IPython中使用它们,但在导入时使用IPython编译它们。
这样做的语法是什么?我不希望我的代码在我的IPython笔记本中。

回答 1
Stack Overflow用户
发布于 2015-02-15 15:42:11
这是一个不寻常的工作流程,但它应该是有可能的一些工作。首先,要使import能够在您的IPython会话中实现,它们必须出现在sys.path中。您可以像这样在列表中插入新文件夹:
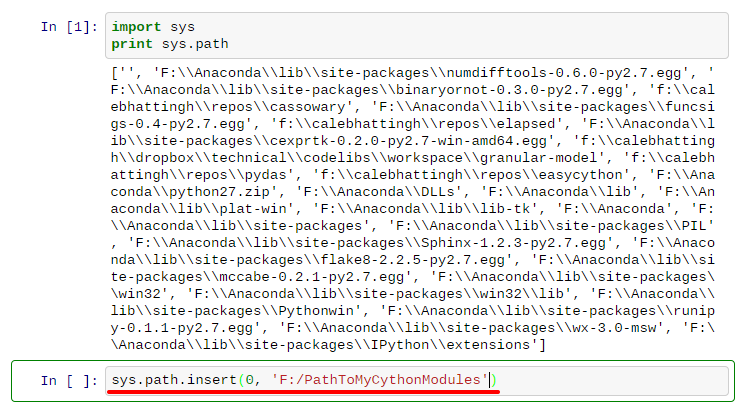
您要添加的路径是将编译后的Cython模块放置在其中的文件夹。无论您使用哪种策略,编译(.pyd) Cython模块的路径至少都需要在sys.path上才能导入。
其次,您需要一种编译Cython模块的方法。如果您正在使用推荐的方法,您将有一个setup.py文件和您的cython源代码以及python setup.py build_ext来生成已编译的.pyd文件。每次重新编译IPython模块时,都必须重新启动您的Cython。
除了setup.py,还有其他的选择。其中之一是my 易囊藻,它是一个命令行工具,可以将.pyx源代码编译成.pyd,而不需要setup.py。这个工具仅由我使用/测试,所以它可能无法工作,ymmv等。您仍然需要重新启动您的IPython内核,每次您重新编译您的Cython模块。(我在这里提到这件事,只是因为它是我的一个婴儿。)
更好的方法是使用pyximport,因为它将按需编译,已经重新加载支持。
# This is inside your IPython Notebook
import pyximport
pyximport.install(reload_support=True)
import my_cython_module您可以用
reload(my_cython_module)您可以尝试使用某种逻辑来使其变得聪明,这样只需简单地重新运行笔记本就可以重新加载或导入:
# Speculative code: I have not tried this!
# This is inside your IPython Notebook
import pyximport
pyximport.install(reload_support=True)
if 'my_cython_module' in dir(): # Maybe sys.modules is better?
reload(my_cython_module)
else:
import my_cython_module您可能需要花一点时间才能找到一些有用的东西,但是对于您的用例来说,某些东西应该是可行的。
https://stackoverflow.com/questions/28532139
复制











腾讯云开发者
