程序如何才能正确地映射代词?
程序如何学会正确地将代词映射到课文中的其他内容?
例如,在文本“丽莎击败珍妮。她是残忍的。”,我希望“她”映射到“丽莎”。
这样的算法是否有一个已知的名称?如果是,那是什么?
回答 4
Stack Overflow用户
发布于 2018-02-08 09:58:56
你要寻找的是共同引用/回指/代词解析[1,2],但与其说是算法,不如说是研究问题。
请看下面的图片,看看CoreNLP在线演示如何处理"Lisa殴打珍妮,她是残忍的“这句话。要记住,它并不总是有您想要/期望的结果,但是.。
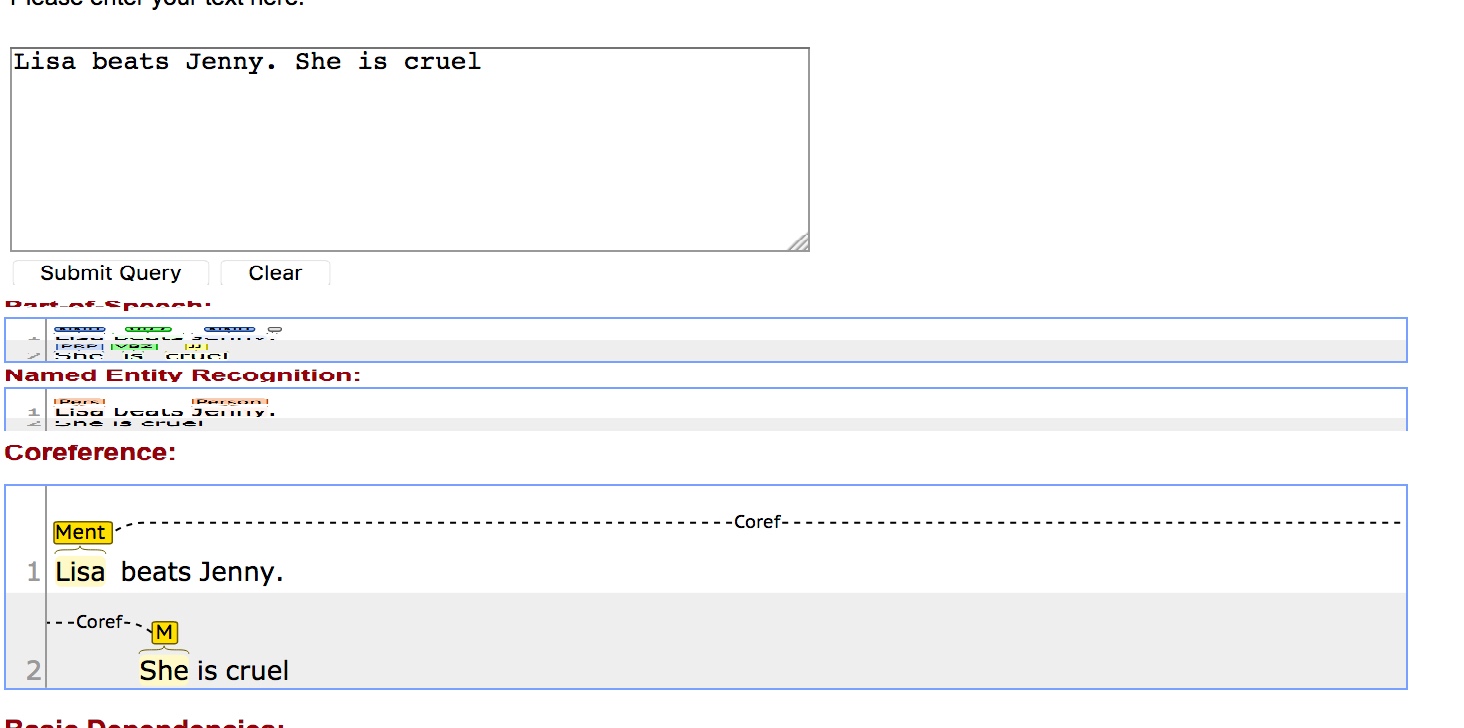
Stack Overflow用户
发布于 2018-02-08 07:11:47
我相信您正在寻找的信息可以在这个链接中找到,关于NLP (自然语言处理)并在CNN (卷积神经网络)中使用它。
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
还值得注意的是,CNN是专门为“视觉”或图像解析而制作的。在大多数情况下,这样一个复杂的需求需要一个深度神经网络(DNN)。
DNN/NLP读数可在以下位置找到:https://arxiv.org/pdf/1703.03091.pdf
TL;博士
没有具体的算法,而是可以用来推断上述信息的多个算法的子集。看看微软关于语言研究的白皮书。
Stack Overflow用户
发布于 2018-02-08 09:14:35
分析这样的句子需要大量的常识。你需要知道殴打某人是一种残忍的行为。据我所知,没有人能真正做到这一点,在不受约束的发言。
海事组织,机器学习技术将失败,因为它们的工作没有理解,只是复制学习模式。但是想想“丽莎打败了珍妮,她很残忍。”“丽莎打败了珍妮,她是金发。”在结构上是相同的,但你不能从另一个中概括出一个。
一些系统,如谷歌翻译工作,通过重用已经看到的片段,即短词序列。但在你的例子中,这些模式可以跨越几个句子,它们再出现的可能性太小了。
https://stackoverflow.com/questions/48688351
复制

![[系统安全] 十二.熊猫烧香病毒IDA和OD逆向分析(上)病毒初始化](https://ask.qcloudimg.com/http-save/yehe-8243071/8864d532471e4ff32fbb10013c863742.png)







相似问题
OCI CLI从对象存储中删除最旧的文件
从字典中删除最旧的项
从localStorage中删除最旧的记录
从数组中删除最旧的元素
从git存储库中删除最旧的提交
领取专属 10元无门槛券
AI混元助手 在线答疑

洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
