
如何删除Geopandas数据框架中的列索引?
提问于 2022-04-13 08:46:13
我从这里下载了一个全球排放的.csv:https://data.worldbank.org/indicator/EN.ATM.CO2E.KT?locations=EU
将其放入一个GeoPandas DataFrame中,并将其与整个世界的shapefile合并。在排放量的.csv中,列名都是正确的。但是,在执行ghg.head()之后,在原始列名上方有一行,其中有'field_1‘、'field_2’.
我想知道如何删除这一行不需要的列名,而下面的行是列名。我已经将ghg.head90输出附在下面。输出图像
请告诉我我能做些什么,谢谢。

回答 1
Stack Overflow用户
回答已采纳
发布于 2022-04-13 09:37:23
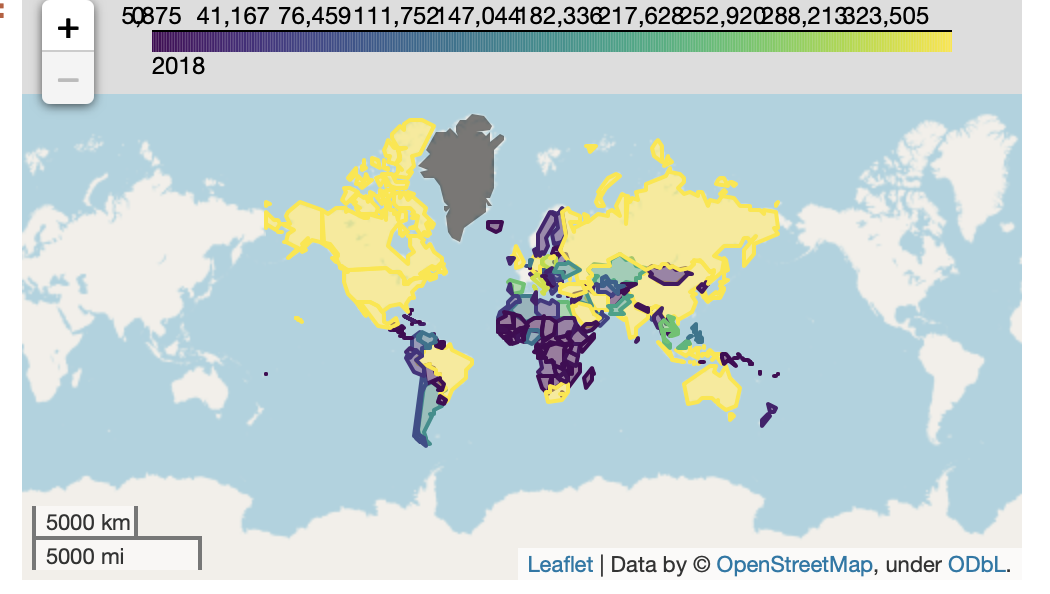
下载了相同的文件。关键部分是在加载CSV时跳过前三行。
import pandas as pd
from pathlib import Path
import geopandas as gpd
# https://api.worldbank.org/v2/en/indicator/EN.ATM.CO2E.KT?downloadformat=csv
f = Path.home().joinpath(
"Downloads/API_EN/API_EN.ATM.CO2E.KT_DS2_en_csv_v2_3888754.csv"
)
df = pd.read_csv(f, skiprows=3)
world = gpd.read_file(gpd.datasets.get_path("naturalearth_lowres"))
# join data and geometry
gdf = gpd.GeoDataFrame(df.merge(world, left_on="Country Code", right_on="iso_a3"))
# now generate a choropleth
gdf.loc[
:, ["Country Name", "Country Code", "Indicator Name", "2018", "geometry"]
].explore(
column="2018",
vmin=gdf["2018"].quantile(0.25),
vmax=gdf["2018"].quantile(0.9),
height=300,
width=500,
)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71861084
复制相关文章







点击加载更多


{kind=link}
腾讯云开发者
