如何从两个向量中选择递增值??“编织两个向量”
如何从两个向量中选择递增值??“编织两个向量”
提问于 2018-06-18 12:22:58
我有两个不同长度的向量。这两个向量的值顺序如下:
v1 <- c(1:5, 11:18)
v2 <- c(2, 7, 8, 14)
v1
# [1] 1 2 3 4 5 11 12 13 14 15 16 17 18
v2
# [1] 2 7 8 14从v1的第一个元素开始,我希望在两个向量之间交替,每次从每个向量中选择一个元素。要选择的每个后续值都应该大于前面的值。
在“织入”两个向量之后所需的序列:
c(1, 2, 3, 7, 11, 14, 15)因此,我们从v1 (1)中的第一个元素开始。然后,下一个元素应该从v2中选择,并且大于前面选择的值;我们从v2 (2 > 1)中选择2。下一个值应该来自v1,并且大于2:我们从v1中选择3。然后7从v2 (7 > 3),11从v1 (11 > 7)等等,在向量之间交替,选择增加的值。
当v2中没有比v1中的前面值更大的元素时,我们将终止对值的选择。因此,在本例中,15是我们从v1中选择的最后一个值(16、17、18被丢弃):
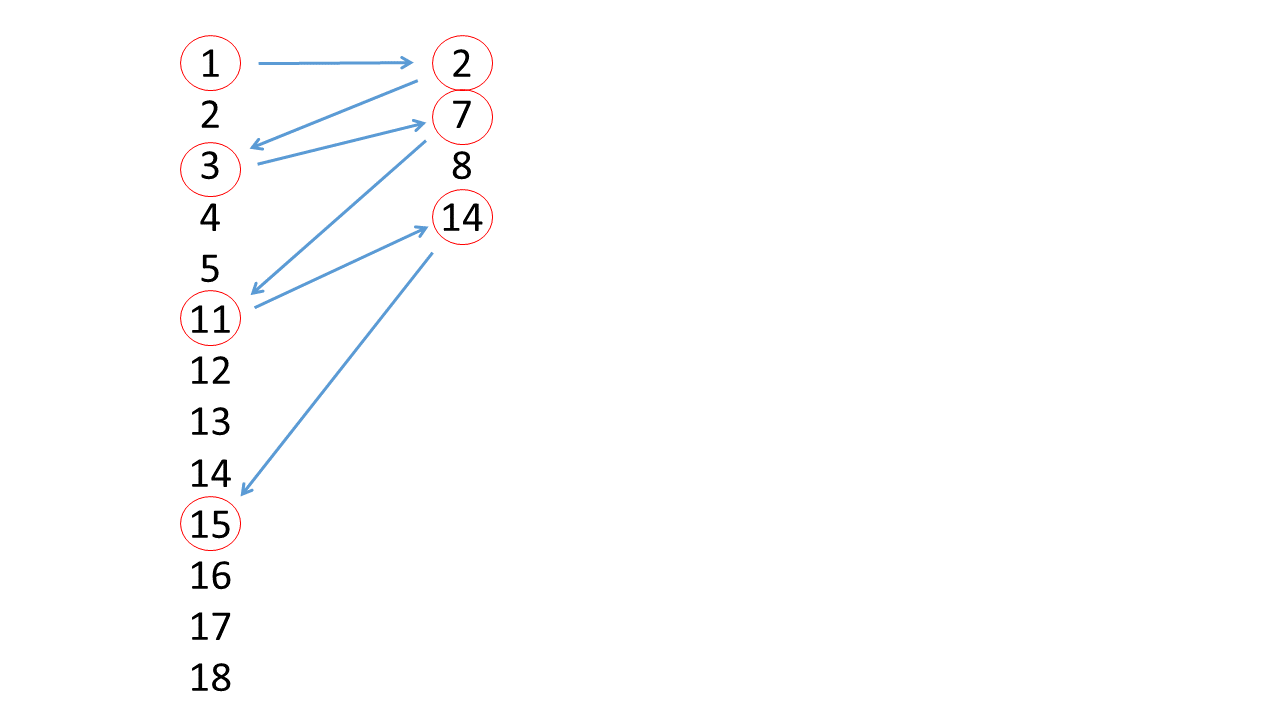
我更喜欢矢量化操作,而不是不必要的循环。
额外:我的虚拟代码在int中。但是,我的实际数据是结构良好的时间值,可以直接用作“lubridate”包中函数的参数。有什么能胜任这项工作的功能吗?
Q1)是否有一个现有的函数可以这样做?( Q2)是否有一种方法可以用矢量化的方法来实现,而不是在每个循环之后循环和修剪输入向量?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-06-18 14:55:19
看看这是否足够普遍:
# extend the shorter of the two vectors, bind them to a matrix,
m <- cbind(v1, v2[1:length(v1)])
# 'weave' the two vectors and bind with a vector index
m2 <- cbind(c(t(m)), 1:2)
# remove NA and duplicates
m3 <- m2[!is.na(m2[ , 1]) & !duplicated(m2[ , 1]), ]
# order
m3 <- m3[order(m3[ , 1]), ]
# to pick values from every other vector,
# create a run-length id based on the vector index,
# remove duplicates of it, and use as index
m3[!duplicated(cumsum(c(1L, m3[ , 2][-nrow(m3)] != m3[ , 2][-1]))), 1]
# [1] 1 2 3 7 11 14 15相同的想法,但稍微更紧凑与data.table
library(data.table)
m <- cbind(v1, v2[1:length(v1)])
d <- data.table(v = c(t(m)), g = 1:2)
d2 <- d[!is.na(v) & !duplicated(v), ]
setorder(d2, v)
d2[ , .SD[1], by = rleid(g)]$v
# [1] 1 2 3 7 11 14 15页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50916951
复制相关文章










点击加载更多
相似问题
谷歌移动视觉是否支持iOS上的光学字符识别?
如何在iOS上使用谷歌云视觉光学字符识别(swift)
如何使用谷歌的AutoML进行光学字符识别
光学字符识别
光学字符识别
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
