

python读取文件夹下所有图片文件_python删除某一列

大家好,又见面了,我是你们的朋友全栈君。
python读取文件夹下所有图片
具体实现步骤
功能需求
读取一个文件夹中的所有图片,并将图像数据存储在一个文件中。
说明
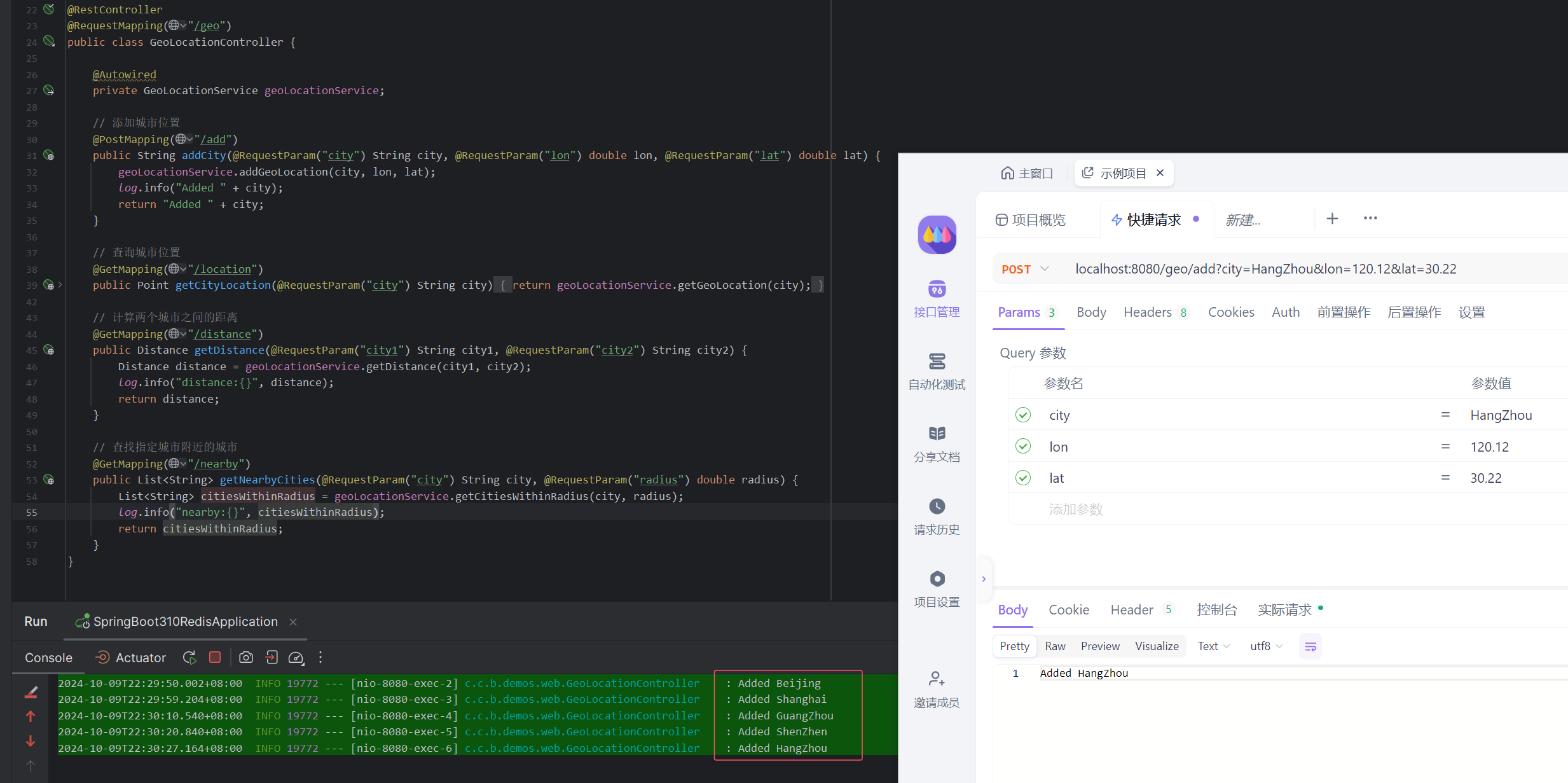
对于本程序中的实现,图片文件夹与python文件应在图一个目录中。

如上图所示,楼主的face.py为读文件夹中所有文件的代码。file中存放的是多张图片。这两个文件都在根目录下,你也可以将他们两个放在其他的目录下,若不放在同一个目录下,则需要修改代码,才能运行成功。
第一步:导入库
代码为:
import os
import cv2,因为涉及到读取图像,所以需要opencv环境。导入cv2时,若电脑里没有安装opencv环境,需要先安装opencv环境。
安装opencv环境的代码为:pip install opencv-python
第二步:写读取函数
代码为:
array_of_img = [] # this if for store all of the image data
# this function is for read image,the input is directory name
def read_directory(directory_name):
# this loop is for read each image in this foder,directory_name is the foder name with images.
for filename in os.listdir(r"./"+directory_name):
#print(filename) #just for test
#img is used to store the image data
img = cv2.imread(directory_name + "/" + filename)
array_of_img.append(img)
#print(img)
print(array_of_img)代码中,array_of_img用来存储图像数据,如果在你的项目中不需要,这个是可以删除的,但是相应的要删除函数里的array_of_img.append(img)。
read_directory为读图像的函数,函数的参数directory_name为图像所在的文件夹名称,在这里,因为这个是函数的参数,所以并不是你真正的文件夹名称。
for filename in os.listdir(r"./"+directory_name)用来循环获取文件夹下的文件名。
img = cv2.imread(directory_name + "/" + filename)用来根据文件夹名称与文件名进行图像的读取。然后并把图像数据存储到array_of_img中。
第三步:函数调用
在第二步中,已经写好了读取的函数,所以只需要对函数进行调用即可。 代码为:
read_directory("file")函数的传入参数file即为你所要读取的文件夹名称,这个是你电脑中真实的文件夹名字。
结语
为什么要写这个博文呢?主要是因为一个美女刚开始学习人脸识别方面,在读取图像这里卡住了,不知道该如何实现读取图像,所以在帮助这个美女实现了这个功能之后,想到可能对于别的一些初学者可能也会遇到这个问题,所以就有了一个不算文章的文章。至此,用python读取一个文件夹中所有的文件的功能已经实现,虽然这个功能很简单,但是对于初学者来说,也并非一个很简单的事情,希望这篇博文能够帮助到初学python,初入计算机视觉的一些同学。 如果在学习的过程中遇到什么问题,欢迎一起讨论进步!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/194935.html原文链接:https://javaforall.cn







![PC端网页使用微信扫码获取用户精确地理位置的一种解决方案[未测试]](https://ask.qcloudimg.com/http-save/yehe-1609133/u2lcs2cv82.jpeg)




腾讯云开发者

