pymc3:具有多个强求变量的层次模型
pymc3:具有多个强求变量的层次模型
提问于 2015-11-11 14:28:25
我有一个简单的层次模型,有很多个人,我有一个正态分布的小样本。这些分布的平均值也服从正态分布。
import numpy as np
n_individuals = 200
points_per_individual = 10
means = np.random.normal(30, 12, n_individuals)
y = np.random.normal(means, 1, (points_per_individual, n_individuals))我想使用PyMC3来计算样本中的模型参数。
import pymc3 as pm
import matplotlib.pyplot as plt
model = pm.Model()
with model:
model_means = pm.Normal('model_means', mu=35, sd=15)
y_obs = pm.Normal('y_obs', mu=model_means, sd=1, shape=n_individuals, observed=y)
trace = pm.sample(1000)
pm.traceplot(trace[100:], vars=['model_means'])
plt.show()

我原以为model_means的后部看起来像我最初的分布方式。但它似乎收敛于30,即手段的平均值。如何从pymc3模型恢复均值的原始标准差(在我的示例中为12)?
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-11-13 01:09:13
这个问题是我为PyMC3的概念而奋斗的。
我需要n_individuals观察到的随机变量来建模y和n_individual随机变量来建模means。它们还需要先验hyper_mean和hyper_sigma作为它们的参数。sigmas是y标准差的优先项。
import matplotlib.pyplot as plt
model = pm.Model()
with model:
hyper_mean = pm.Normal('hyper_mean', mu=0, sd=100)
hyper_sigma = pm.HalfNormal('hyper_sigma', sd=3)
means = pm.Normal('means', mu=hyper_mean, sd=hyper_sigma, shape=n_individuals)
sigmas = pm.HalfNormal('sigmas', sd=100)
y = pm.Normal('y', mu=means, sd=sigmas, observed=y)
trace = pm.sample(10000)
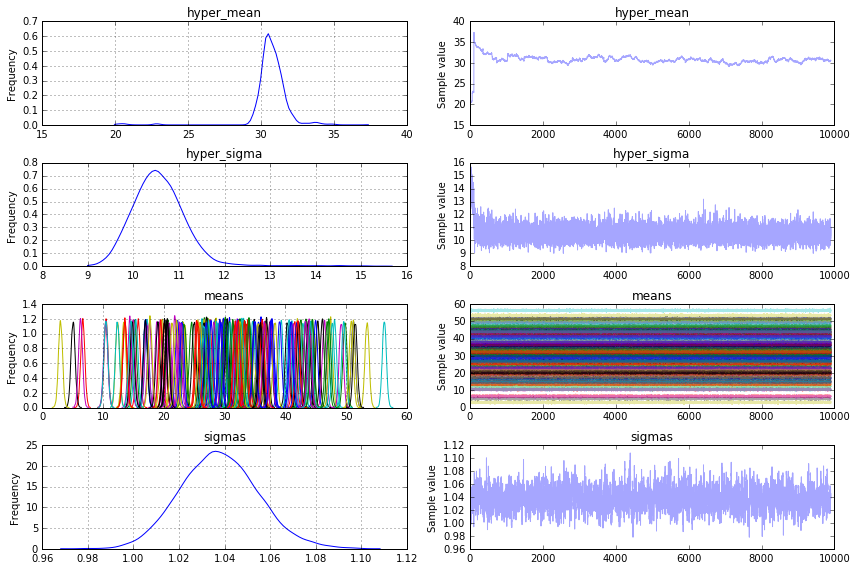
pm.traceplot(trace[100:], vars=['hyper_mean', 'hyper_sigma', 'means', 'sigmas'])
plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/33661064
复制相关文章





相似问题
具有交互项的Pymc3层次模型
在weibullAFT中建立具有协变量的PyMC3模型?
rails:具有多个父级的层次模型
PYMC3混合模型:帮助理解多变量模型
复制具有层次结构的模型
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
