memcached的最新状态

memcached 是由 Danga Interactive 开发并使用 BSD 许可的一种通用的分布式内存缓存系统。最新的稳定版本是memcached 1.4.4,1.4版本加了需要好的特性,这里简要介绍2个:
1、memcached之前一直有个缓存对象的大小限制是1M,从1.4版本开始可以通过命令配置缓存的对象大小上限。可以通过参数-I进行配置
C:\Documents and Settings\geffzhang>F:\Software\memcached-win32-1.4.4-14\mem
ed.exe -h
memcached 1.4.4-14-g9c660c0
……
-I Override the size of each slab page. Adjusts max item size
(default: 1mb, min: 1k, max: 128m)
例如
memcached -I 128k # Refuse items larger than 128k.
memcached -I 10m # Allow objects up to 10MB
2、开始支持64位操作系统
memcached的介绍可参考IBM网站上的文章memcached 和 Grails,第 1 部分:安装和使用 memcached,windows上的使用方法参烤在 ASP.NET 環境下使用 Memcached 快速上手指南 。
下载 memcached 1.4.4 Windows 32-bit binary 或者 memcached Windows 64-bit pre-release
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2010-02-01 ,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
暂无评论
推荐阅读










推荐阅读
相关推荐
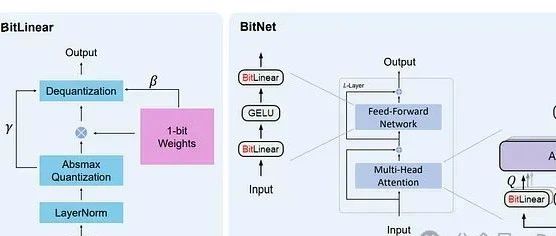
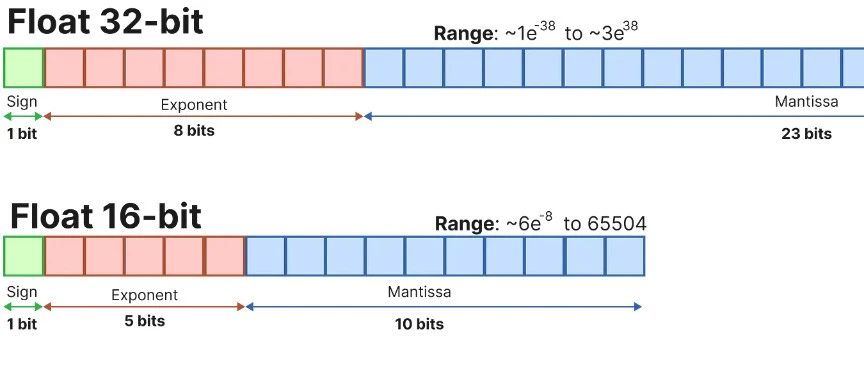
从16-bit 到 1.58-bit :大模型内存效率和准确性之间的最佳权衡
更多 >
腾讯云开发者
