字符串作为决策树/随机林中的特征
在一个决策树/随机森林的应用中,我正在做一些问题。我试图适应一个问题,它有数字和字符串(如国家名称)作为功能。现在,科学知识-学习只使用数字作为参数,但是我想注入字符串,因为它们携带了大量的知识。
我如何处理这种情况?
我可以通过某种机制(如Python中的散列)将字符串转换为数字。但是我想知道在决策树问题中如何处理字符串的最佳实践。
回答 6
Data Science用户
发布于 2015-02-25 02:10:55
在大多数建立良好的机器学习系统中,分类变量是自然处理的.例如,在R中使用因子,在WEKA中使用名义变量。这不是科学知识的情况。在scikit-learn中实现的决策树只使用数字特性,并且这些特性总是被解释为连续的数值变量。
因此,应该避免简单地用哈希代码替换字符串,因为被认为是一个连续的数字特性,您将要使用的任何编码都会导致数据中根本不存在的顺序。
一个例子是用“红色”,“绿色”,“蓝色”编写1,2,3代码,会产生一些奇怪的东西,比如‘红色’低于‘蓝色’,如果你把‘红色’和‘蓝色’相加,你就会得到‘绿色’。在用“低”、“中”、“高”编写1,2,3代码时,可能会出现另一个更微妙的例子。在后一种情况下,它可能有一个排序,这是有意义的,然而,一些微妙的不一致,可能会发生在‘中等’中,而不是在‘低’和‘高’。
最后,您的问题的答案在于将分类特性编码成多个二进制特性。例如,您可以用3列编码“红色”,“绿色”,“蓝色”,每个类别一列,当类别匹配时有1列,否则为0。这被称为一次热编码,二进制编码,一次k编码或其他什么。您可以在这里查看文档中的编码分类特征和特征提取-哈希和切分。显然,单热编码会扩展您的空间需求,有时也会损害性能。
Data Science用户
发布于 2015-10-14 11:18:50
您需要将字符串编码为sci可用于ML算法的数值特性。此功能是在预处理模块中处理的(例如,参见sklearn.preprocessing.LabelEncoder中的一个示例)。
Data Science用户
发布于 2018-05-22 10:09:07
2018年更新!
您可以为分类变量创建一个嵌入(密集向量)空间。你们中的许多人都熟悉word2vec和fastext,它们将单词嵌入到有意义的密集向量空间中。同样的想法--你的分类变量会映射到一个有意义的向量上。
来自郭/伯尔哈恩纸:
实体嵌入不仅减少了内存占用,加快了神经网络的一次热编码,更重要的是通过在嵌入空间中映射相似的值,揭示了分类变量的内在特性。我们在最近的一次Kaggle比赛中成功地应用了它,并且能够以相对简单的特性达到第三位。
作者发现,用这种方法表示分类变量提高了所有机器学习算法(包括随机林)的有效性。
最好的例子可能是Pinterest技术的应用来分组相关的Pins:

created的工作人员已经实现了分类嵌入,并与同伴博客帖子一起创建了一个非常好的演示笔记本。
附加细节和解释
使用神经网络来创建嵌入,即给每个分类值赋值一个向量。一旦你有了向量,你就可以在任何接受数值的模型中使用它们。向量的每个分量都变成一个输入变量。例如,如果你使用三维向量嵌入你的颜色分类列表,你可能会得到类似的东西: red=(0,1.5,-2.3),blue=(1,1,0)等等。对于红色事物,c1=0、c2=1.5和c3=-2.3。对于蓝色的东西,c1=1,c2=1,和c3=0。
实际上,您不需要使用神经网络来创建嵌入(虽然我不建议回避这种技术)。在可能的情况下,您可以通过手工或其他方式创建自己的嵌入。下面是一些例子:
- 将颜色映射到RGB向量。
- 将位置映射到lat/长向量。
- 在美国的政治模式中,将城市映射到一些矢量组件,表示左/右对齐、税收负担等。
https://datascience.stackexchange.com/questions/5226
复制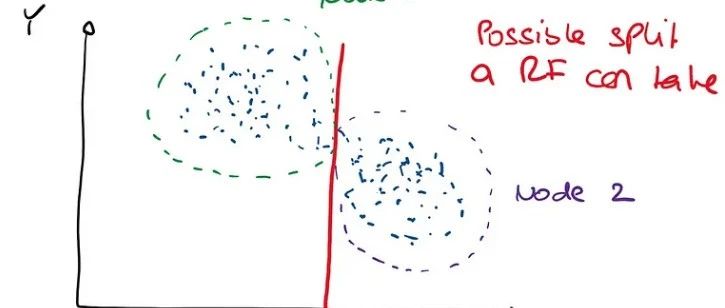

![[机器学习算法]随机森林](https://ask.qcloudimg.com/http-save/yehe-4572088/a2bi32d78a.png)







相似问题
在随机森林中利用特征导入进行特征选择
在随机森林中决策树是如何平均的?
随机森林中混合特征的文本分类
为什么我们在随机森林中选择随机特征?
在随机森林中使用什么样的决策树?
领取专属 10元无门槛券
AI混元助手 在线答疑

洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
