基于测试批次大小的神经分割网络给出不同的输出。
基于测试批次大小的神经分割网络给出不同的输出。
提问于 2021-05-04 07:39:42
我已经实现并训练了(224,224)图像的神经分割模型。但是,在测试期间,根据测试批的形状,模型返回的结果略有不同。
下面的图像是在我的预训练模型测试中得到的结果。
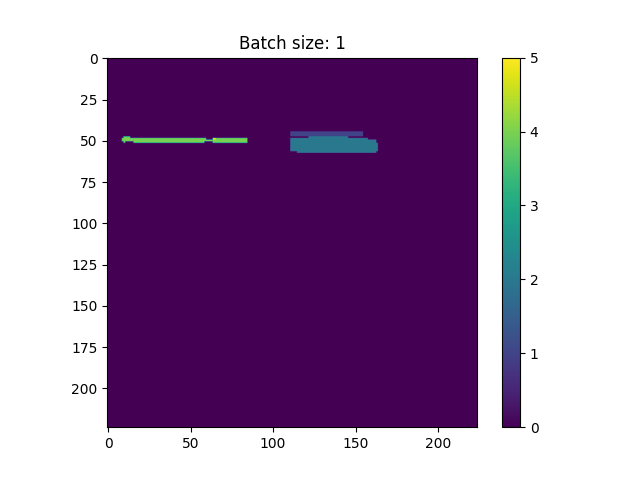
第一个图像是我预测单个示例时得到的预测(让我们称之为img0) (因此,输入是[img0],具有形状(1,224,224))。
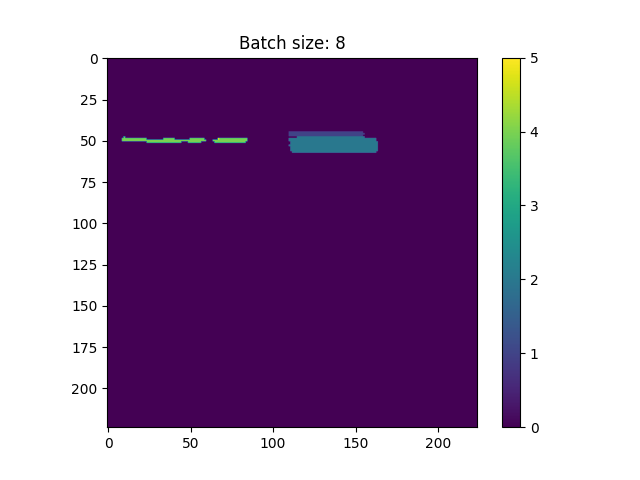
第二个图像是对同一图像的预测,但当它与其他7个图像一起批处理时(因此,输入是[img0, img1, ..., img7]并具有形状(8,224,224))。
与第二个输出相比,第一个输出比我预期的更接近。
但是,我不明白为什么输出是不同的.这应该是正常行为吗?提前谢谢。
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-05-25 12:02:39
这种行为来自于我的模型中的批处理规范化层。我在调用模型时使用training=true。
其结果是,批规范化将基于它们的规范对批进行规范化,而该规范则根据批大小而变化。
因此,这是正常的行为!
Stack Overflow用户
发布于 2021-05-04 19:43:58
是的,批处理大小是一个超参数,这意味着您应该尝试和错误来找到它的最佳值(超参数调优)。但你也应该意识到它对训练过程的影响。在每一批中,损失将通过给出批中的样本来计算,然后再使用该损失值进行反向传播。因此,如果您为批处理大小选择一个很小的值,很有可能您将无法找到全局最优,而您只是在它周围波动,甚至停留在局部最优(从优化的角度)。对于批处理大小(特别是1),建议不要太小的值。
此外,您还需要一个验证集(多个样本)来完全确定您的模型是否准确。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67387883
复制相关文章












相似问题
不同的批次大小给出不同的测试分数。
神经网络:时代与批次大小
对于同一输入,神经网络给出不同的输出。
训练验证.基于神经网络和网格搜索的测试分割
如何分割神经元网络的输出
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
