
非正规化与子女/父母和筑巢
我们正在设计活动的弹性搜索模型,活动的时间表和地点,事件发生的地点。设计如下:
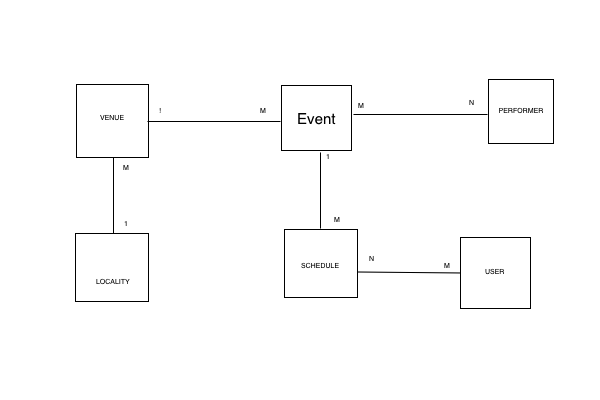
我们可能需要的查询示例:
查找2017年7月1日至2017年7月7日之间的音乐会活动 寻找在伦敦表演的艺术家,活动是戏剧。 查找事件,即电影,得分超过70% 查找参加活动AwesomeEvent的用户 寻找场地,哪个地点是伦敦,从今天起任何活动都是计划好的。
我读过弹性医生,很少读过像这和一些堆栈问题这样的文章。但我仍然不确定我们的模型,因为它非常具体。
可能使用的例子:
1)使用嵌套模式
{
"title": "Event",
"body": "This great event is going to be...",
"Schedules": [
{
"name": "Schedule 1",
"start": "7.7.2017",
"end": "8.7.2017"
},
{
"name": "Schedule 2",
"start": "10.7.2017",
"end": "11.7.2017"
}
],
"Performers": [
{
"name": "Performer 1",
"genre": "Rock"
},
{
"name": "Performer 2",
"genre": "Pop"
}
],
...
}优点:
- 更平坦的模型,应该坚持“键:值”的方法。
- 实体本身携带所有信息。
缺点:
- 大量冗余数据
- 更复杂的实体
2)以下实体之间的父母/子女关系(简化)
{
"title": "Event",
"body": "This great event is going to be...",
}
{
"title": "Schedule",
"start": "7.7.2017",
"end": "8.7.2017"
}
{
"name": "Performer",
"genre": "Rock"
}优点:
- 避免重复冗余数据
缺点:
- 更多的连接(即使父/子存储在同一个分片中)
- 模特儿没那么平,我对表演不太确定
到目前为止,我们有一个关系数据库,其中的模型工作良好,但速度不够快。特别是当你想象一家电影院,一个事件(电影)可以在不同的地方有成千上万的时间表,我们想要达到非常快的过滤响应,正如我在第一部分所写的。
我期待任何能正确设计数据模型的建议。我也会很高兴重新审视我的假设(可能有些假设是错误的)。

回答 1
Stack Overflow用户
发布于 2017-07-18 16:34:37
很难对你的数据进行反篡改。例如,事件中表演者的数量是未知的;因此,如果要为表演者指定特定的字段,则需要perofrmer1. have、perofrmer1.lastname、karer2.name、tester2.lastname等。但是,如果使用嵌套字段,则只需在事件索引下定义一个嵌套字段执行器,并具有正确的子字段映射,那么您可以添加任意数量的元素。这将使您能够按表演者或表演者逐个事件查找事件。这同样适用于其余的指数。
就父-子和嵌套而言,父子关系提供了更多依赖,因为子文档驻留在完全独立的索引上。父-子字段和嵌套字段都可以指定"include_in_parent“选项,以便为您自动还原字段。
https://stackoverflow.com/questions/45174436
复制







腾讯云开发者
