
告别“幻觉生成”!清华团队提出DRAGIN框架:让大模型主动动态检索关键信息

现有RAG检索的不足
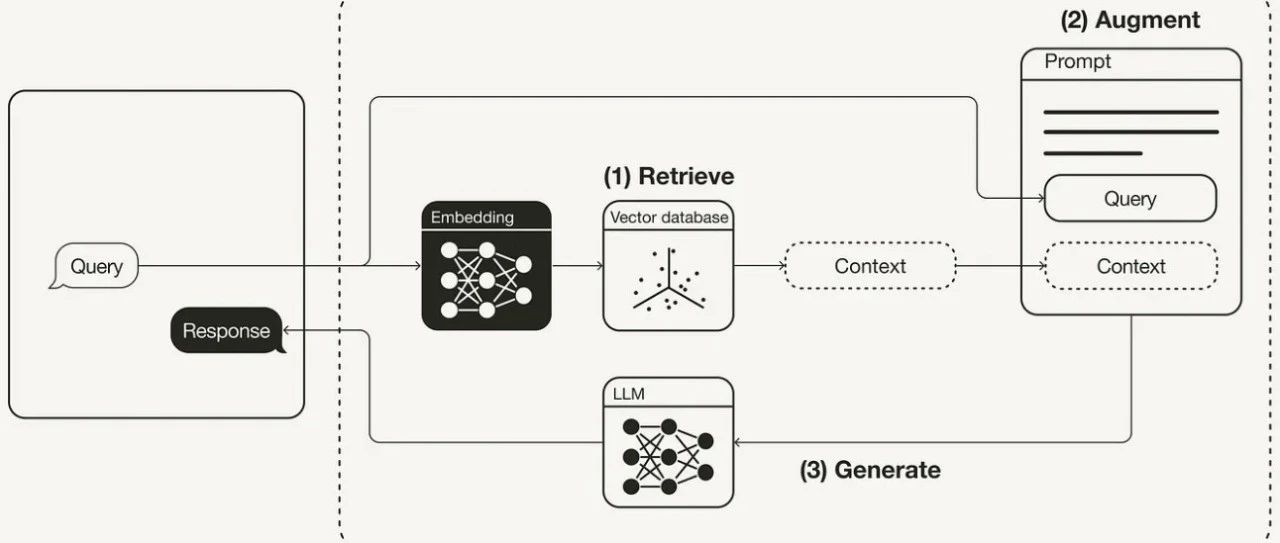
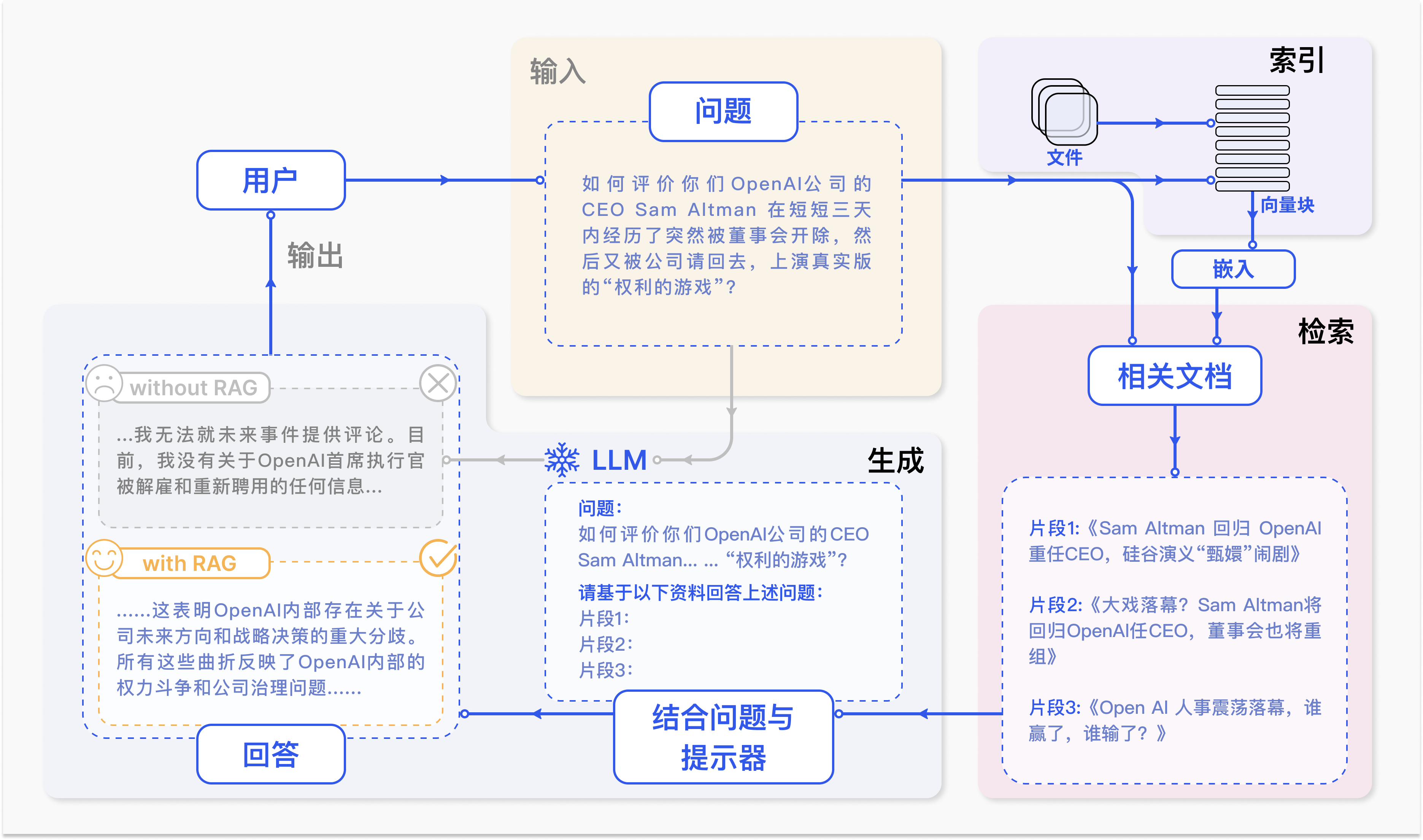
传统的 RAG 方法通常依赖于单轮检索,即使用 LLM 的初始输入从外部语料库中检索相关信息。现有方法通常依赖于静态规则来决定何时检索,忽略了对检索必要性及潜在风险的评估。
一方面,根据输入查询和检索模型的质量,不必要的检索增强可能会为 LLMs 引入无关或噪声数据,从而影响输出质量。另一方面,进行检索增强不可避免地会增加 LLM 推理的时间和计算成本,如果 LLMs 能够自行生成正确输出,这种成本是不值得的。此外,现有研究在决定检索什么时,通常局限于 LLM 最近生成的句子或最后几个词元。这种方法可能无法捕捉模型的实时信息需求,因为 LLM 的信息需求实际上可能与贯穿整个上下文的术语相关。因此,以这种方式检索文档在许多情况下是次优的。
清华大学&北京理工大学联合推出最新 DRAGIN,基于大型语言模型信息需求的动态检索增强生成方法。

动态检索增强生成
动态检索增强生成(RAG)范式能够在 LLM 的文本生成过程中主动决定何时以及检索什么内容。这一范式的两个关键要素是:确定激活检索模块的最佳时机(决定何时检索)以及在触发检索后构建适当的查询(决定检索什么)。
DRAGIN,即基于 LLM 信息需求的动态检索增强生成框架。专门设计用于在文本生成过程中,根据 LLM 的信息需求来决定何时检索以及检索什么。
对于检索时机,提出了 实时信息需求检测(RIND),它综合考虑了 LLM 对其生成内容的不确定性、每个词元对后续词元的影响以及每个词元的语义重要性。
对于查询生成,提出了 基于自注意力的查询生成,通过利用 LLM 对整个上下文的自注意力机制,创新性地生成查询。
DRAGIN 是一个轻量级的 RAG 框架,无需进一步训练、微调或提示工程,即可集成到任何基于 Transformer 的 LLMs 中。
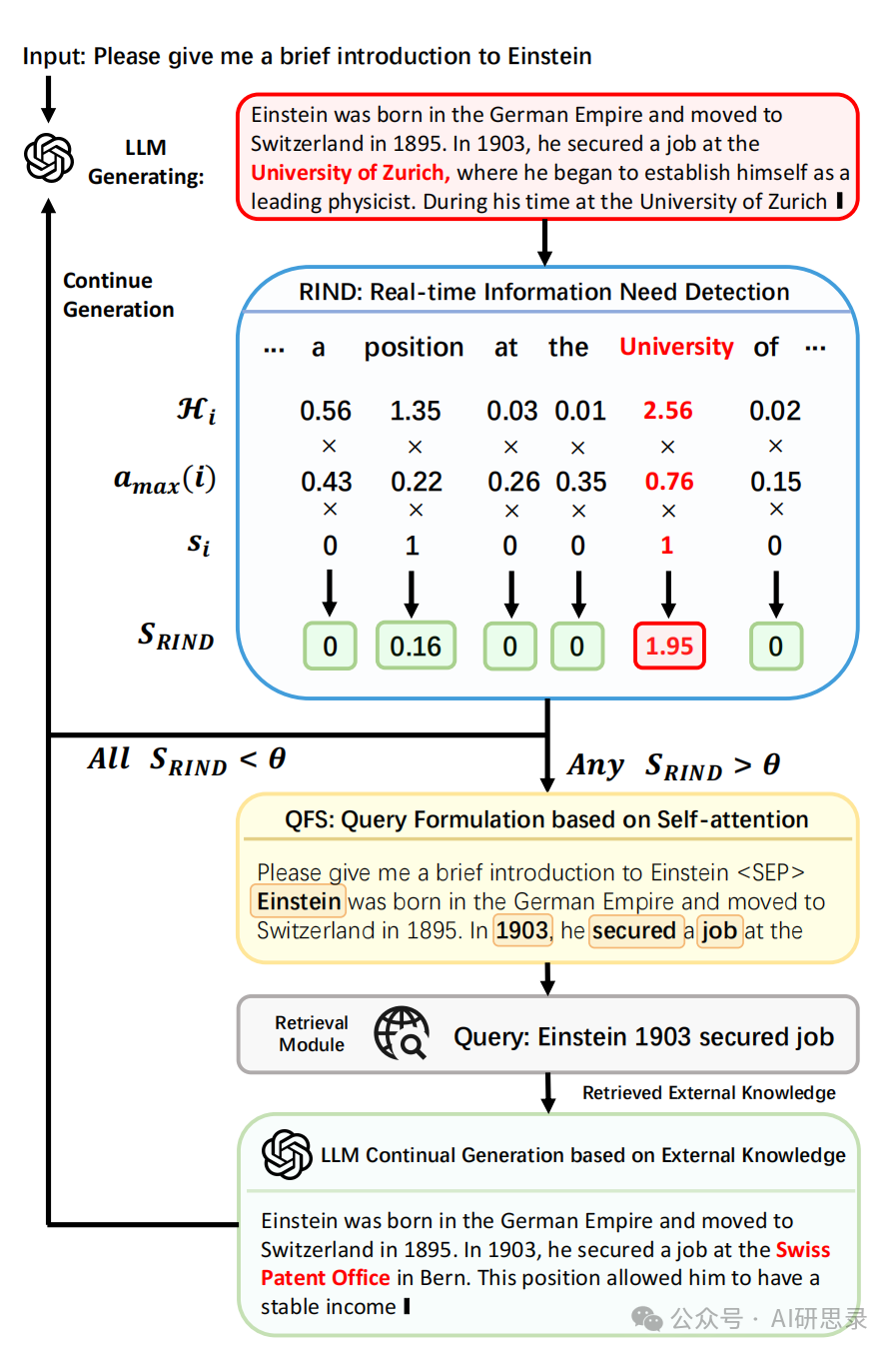
实时信息需求检测
检索增强的必要性取决于:
- 词元重要性:当前词元对后续上下文的影响;
- 语义价值:词元是否承载关键语义;
- 上下文依赖性:词元是否关联长期知识需求。
通过多维评估优化检索触发机制,避免了仅依赖置信度的单维度策略的不足。
基于自注意力的查询生成
当RIND模块确定需要触发检索后,动态RAG框架的下一步是生成查询以从外部数据库中检索必要信息,辅助LLM继续生成。现有动态RAG框架的查询生成方法通常局限于LLM最近生成的句子或最后几个词元,这种狭窄的视野无法满足模型可能覆盖整个上下文的实时信息需求。
为突破这一局限,基于自注意力的查询生成(QFS),通过挖掘Transformer架构的自注意力机制,精准捕捉LLM对上下文的全局理解,从而生成更适配当前信息需求的查询。
- 注意力权重反映上下文关联:生成时,LLM对前文词元的注意力权重揭示了哪些词元对当前决策最关键。
- 全局语义聚焦:通过分析整个上下文的注意力分布,QFS能识别与当前信息需求最相关的跨句或长程依赖词元,而非仅依赖局部上下文。
核心思想
假设LLM生成的序列为,当RIND模块检测到位置 的词元 需要外部知识时,QFS基于以下观察生成查询:
- 提取注意力权重:对触发检索的位置,提取最后一层 Transformer 中对前文所有词元的注意力分数;
- 排序并筛选关键词元:按注意力分数降序排列,选择注意力权重最高的前 个词元;
- 重构查询语句:根据词元的原始顺序,拼接生成查询语句。
技术优势
- 长程依赖捕捉: 通过全局注意力权重,QFS能识别跨句或长距离相关的关键实体(例如前文提到的“量子比特”与后文“纠错机制”的关联)。 示例:生成技术文档时,若当前触发位置涉及“纠错机制”,QFS可能检索前文提到的“量子比特”和后文的“低温稳定性”,形成查询“量子比特 纠错机制 低温稳定性”。
- 动态语义适配: 相比静态截取最近词元,QFS根据实时注意力分布调整查询焦点,避免噪声干扰。 示例:生成历史事件描述时,若触发位置涉及因果关系(如“导致经济衰退”),QFS可能提取前文的“政策调整”和后文的“市场反应”构建查询。
- 计算高效: 注意力权重已在LLM推理过程中计算完成,QFS仅需排序和选择操作,几乎无额外开销。
检索后的继续生成
当RIND模块检测到位置 i 需要外部知识时,QFS模块生成查询并利用现成检索模型(如BM25)从外部知识库中检索相关信息。假设检索到的文档为,动态RAG框架的下一步是将这些知识整合到LLM的生成流程中,
输入提示词模板
以下是外部知识参考: [1] [2] [3] 请基于外部知识回答问题: 问题:{原始问题或上下文} 回答:{T'}
示例: 若原始生成序列为“量子计算机的______需要极低温环境”,检索到文档包含“量子比特需在稀释制冷机中运行”,则LLM输入变为:
以下是外部知识参考: [1] 量子计算机的核心组件是量子比特,其运行需在接近绝对零度的稀释制冷机中进行。 请基于外部知识回答问题: 问题:量子计算机的哪些组件需要极低温环境? 回答:量子计算机的___需要极低温环境。
LLM基于整合后的输入继续生成后续内容,例如补全为“量子计算机的量子比特和稀释制冷机需要极低温环境”。
总结
主要特点
- 动态检索:DRAGIN 根据 LLM 的实时信息需求主动决定何时检索以及检索什么,从而显著提高生成文本的相关性和准确性。
- 轻量级集成:DRAGIN 设计为轻量级框架,可以无缝集成到任何基于 Transformer 的 LLM 中,而无需额外的培训、微调或提示工程。
- 增强的文本生成:通过更有效地解决检索的时间和内容问题,DRAGIN 提高了 LLM 生成的文本的质量,使其信息量更大、上下文相关性更强、连贯性更强。
实验结果
在2WikiMultihopQA、HotpotQA(多跳推理)、IIRC(阅读理解)、StrategyQA(常识推理)进行了实验。 对比实验:
- wo-RAG:LLM 直接回答问题,不使用 RAG 增强。
- FLARE:动态 RAG 框架,仅当生成置信度低于阈值时触发检索。
- IR-CoT:每生成一个句子触发一次检索,使用最新句子作为查询。
- RETRO:基于固定词元窗口触发检索,使用最后 N 个词元作为查询。
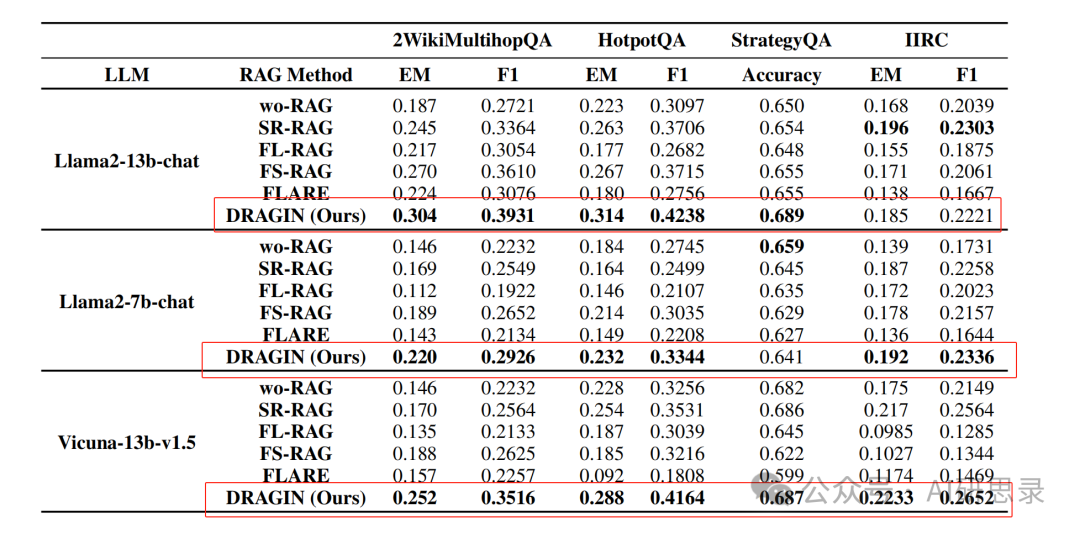
与传统RAG对比
方法 | 知识整合方式 | 局限性 |
|---|---|---|
传统 RAG | 初始检索后一次性注入所有知识 | 长文本生成中知识过时或冗余 |
动态 RAG-DRAGIN | 按需多轮注入,每次仅更新局部知识 | 需管理多轮检索的上下文依赖 |
代码地址:https://github.com/oneal2000/DRAGIN/tree/main
论文地址:https://arxiv.org/pdf/2403.10081









腾讯云开发者
