NIPS 2024 | 跨领域图像去噪的适应性领域学习

NIPS 2024 | 跨领域图像去噪的适应性领域学习

小白学视觉
发布于 2025-03-24 14:11:45
发布于 2025-03-24 14:11:45
论文信息
题目:Adaptive Domain Learning for Cross-domain Image Denoising
跨领域图像去噪的适应性领域学习
作者:Zian Qian,Chenyang Qi,Ka Lung Law,Hao Fu,Chenyang Lei,Qifeng Chen
论文创新点
- 适应性领域学习(ADL)策略:作者提出了一种新颖的ADL策略,能够通过自动评估源领域数据的有用性,去除有害数据,从而在目标领域中以少量数据的情况下训练出有效的去噪模型。
- 动态验证集和软标准评估:作者引入了动态验证集和基于PSNR的软标准评估方法,通过动态采样验证集并维护一个优先队列来存储历史最高PSNR值,从而在训练过程中动态评估数据的有用性。
- 通道调制网络:作者设计了一个通道调制网络,通过嵌入传感器类型和ISO信息,调整不同传感器的特征空间,使网络能够更好地适应不同传感器的噪声分布。
摘要
不同的相机传感器具有不同的噪声模式,因此在一个传感器上训练的图像去噪模型通常无法很好地泛化到另一个传感器上。一个可行的解决方案是为每个传感器收集大量数据进行训练或微调,但这不可避免地耗时且费力。为了解决这一跨领域挑战,作者提出了一种新颖的适应性领域学习(Adaptive Domain Learning, ADL)方案,通过利用来自不同传感器的现有数据(源领域)以及少量来自新传感器的数据(目标领域),实现跨领域RAW图像去噪。ADL训练方案能够自动去除对目标领域微调模型有害的源领域数据(某些数据由于领域差异,加入训练会降低性能)。此外,作者引入了一个调制模块,用于采用传感器特定的信息(传感器类型和ISO)来理解输入数据以进行图像去噪。作者在包含多种智能手机和DSLR相机的公开数据集上进行了广泛的实验,结果表明,在目标领域传感器提供少量图像数据的情况下,作者提出的模型在跨领域图像去噪方面优于现有工作。
3 方法
在本节中,作者介绍了适应性领域学习管道的三个步骤:目标领域预训练、源领域适应性学习和目标领域微调。总体管道如图1所示。
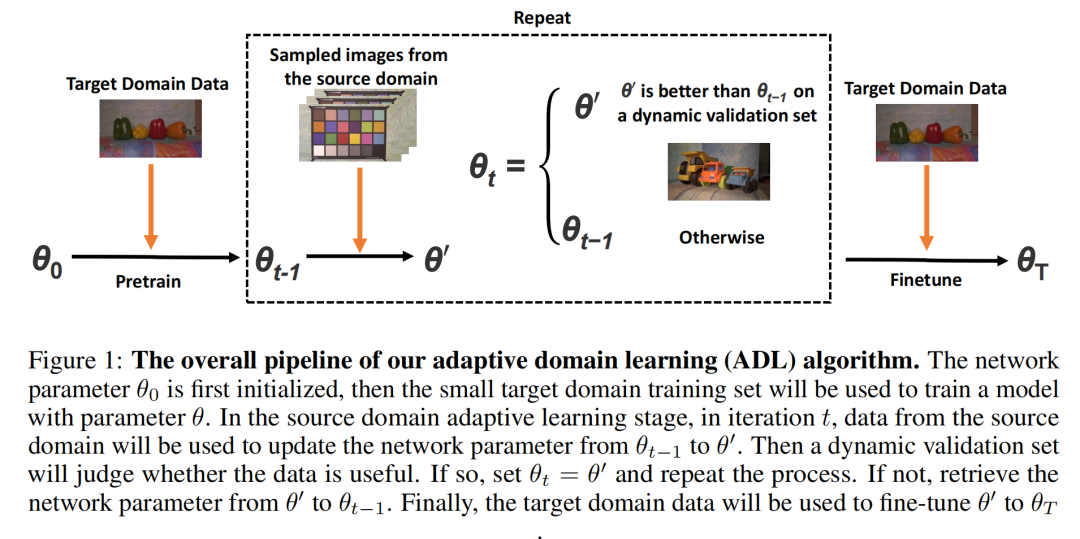
适应性领域学习算法
3.1.1 目标领域预训练
给定目标领域的小训练集,作者首先通过最小化像素级损失对目标领域进行预训练。
目标领域预训练有两个好处。首先,尽管源领域和目标领域之间存在领域差距,但去噪任务共享相似的隐式特征表示。因此,预训练可以为目标领域适应性学习阶段提供更好的初始化。其次,目标领域的数据非常少,源领域的数据可能是目标领域数据的100倍。在目标领域上预训练可以提高鲁棒性,并确保目标领域数据在整个训练过程中的主导地位,防止模型过拟合到源领域。
3.1.2 源领域适应性学习
然而,由于源领域和目标领域之间的领域差距,并非所有源领域数据都对目标领域的训练有贡献,某些数据可能有害并导致性能下降。因此,作者提出了适应性领域学习(ADL),以消除有害数据并利用对模型有贡献的数据。
在每次迭代中,作者从某个源领域中采样一批训练数据,并通过以下公式将预训练参数适应为:
其中是学习率,是定义在上的损失。
动态验证集 为了判断数据批次是否对模型有贡献,作者在目标领域验证集上评估更新后的参数,该验证集从目标领域数据集中采样。每次迭代中验证集的选择对方法的性能至关重要。固定的验证集选择可能导致训练陷入局部最小值并容易过拟合到验证集。为了避免这些问题,在每次迭代中,作者随机从目标领域数据集中采样一个动态验证集,大小为,以使模型以随机方式探索特征空间。另一方面,的其余部分,记为,将与结合,为训练过程提供正确的方向。在训练开始时,设置为大小的20%,并在训练过程中增加。训练结束时,的50%将用于验证。
此外,受启发,当的大小极小时,即小于10,作者有意选择具有非常多样系统增益的数据来形成,以避免过拟合问题。
动态平均PSNR 作者通过比较更新后的网络参数在采样验证集上的PSNR与前一次迭代的PSNR来评估数据批次是否有用。然而,基于PSNR的硬标准通常在动态验证集设置下使训练过程不稳定。当动态验证集的大小较小时,PSNR的方差较大,因此不太可靠。某些有用的数据可能会被意外删除。在这种情况下,如果有提高模型性能的趋势,作者希望模型将其视为有用数据。作者设计了基于PSNR的软标准,通过维护一个优先队列来存储训练过程中历史上的最高PSNR值。按PSNR值升序排列。作者将在训练过程中迭代时模型在动态验证集上的PSNR记为。在适应性领域学习阶段开始时,作者将推入。在训练过程中,如果更新后的参数在动态验证集上的PSNR 高于中的平均PSNR,作者保留更新后的参数,并将推入,如果已满,则弹出第一个元素。否则,作者将网络参数从恢复到。该过程可以表示为:
在最终阶段,作者使用目标领域训练集微调在前一阶段获得的网络参数,并更新网络参数为。适应性领域学习算法的详细描述如算法3.2所示。
通道调制网络
为了使网络更好地利用具有不同噪声分布的传感器信息,作者需要调整不同输入的特征空间。对于由CMOS传感器捕获的RAW数据,作者可以将其噪声建模为:
其中是系统增益,是信号依赖噪声,是信号独立噪声。基于此建模,作者提出了一种通道调制网络,通过嵌入两个易于访问的参数(传感器类型和ISO)来调整特征空间。ISO与系统增益成正比,而传感器类型可以帮助网络了解如何利用ISO学习信号依赖噪声并识别信号独立噪声。
给定传感器类型的一热编码和对应的ISO (在向量中重复次),作者的通道调制层通过以下公式将连接的元数据转换为通道尺度和偏移:
其中,和是两个四层的多层感知器。设第个卷积层的特征图为,作者通过通道线性组合将传感器特定数据嵌入到中:
注意,通道调制策略的输入元数据类型不固定。只要提供了更多的元信息,输入连接向量就可以扩展。
4 实验
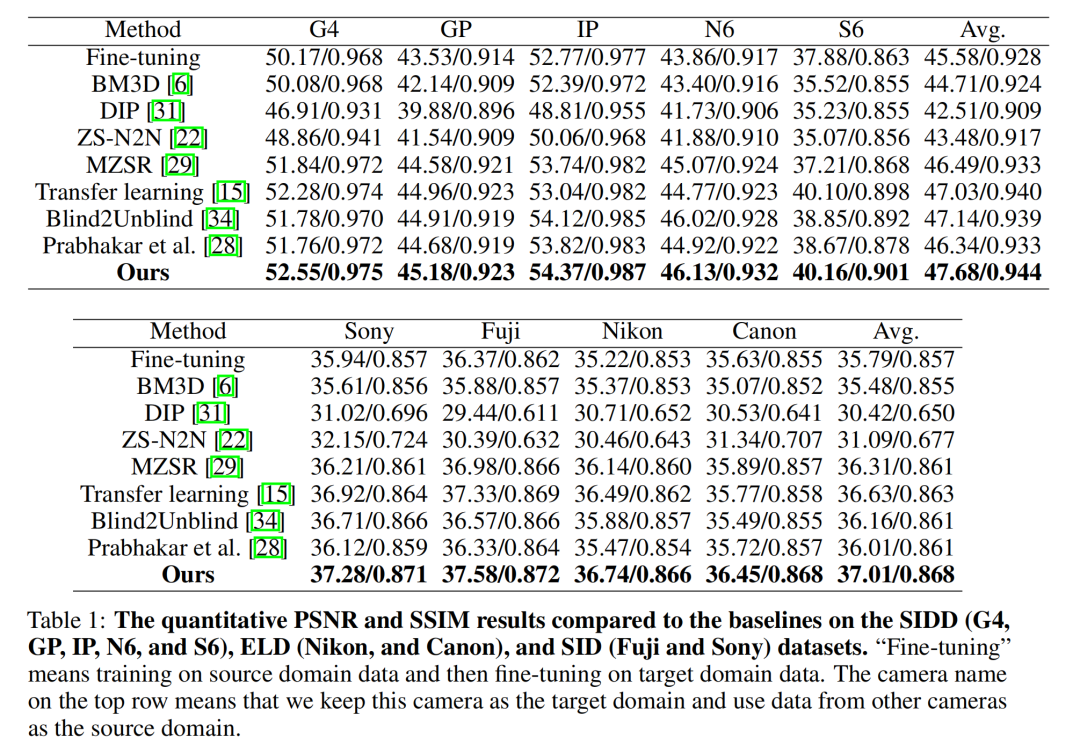

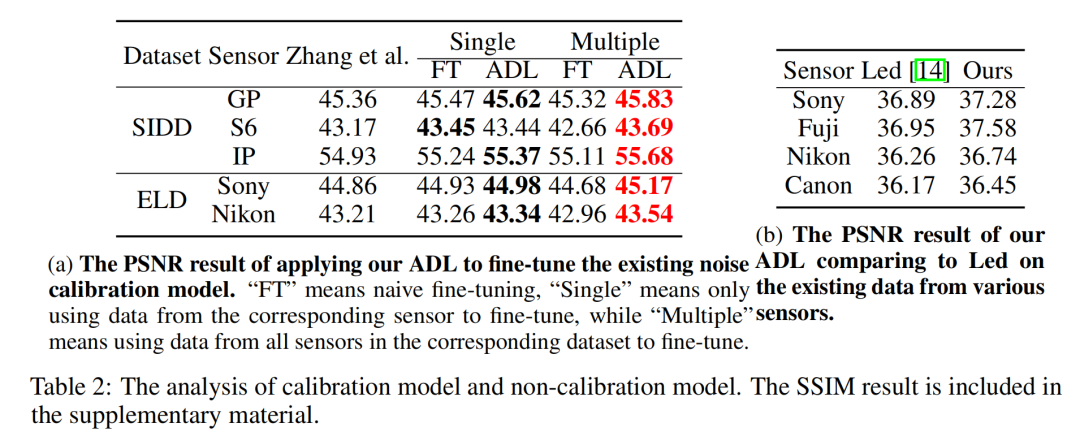
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号